
La deseo de acelerar el descubrimiento sabio a través de IA ha sido de larga data, con esfuerzos tempranos como el tesina de IA aplicada de Oak Ridge que data de 1979. Los avances más recientes en los modelos fundamentales han demostrado la viabilidad de las tuberías de investigación totalmente automatizadas, permitiendo que los sistemas de IA realicen de forma autónoma de forma autónoma. Revisiones de humanidades, formular hipótesis, experimentos de diseño, analizar resultados e incluso suscitar artículos científicos. Por otra parte, pueden optimizar los flujos de trabajo científicos automatizando tareas repetitivas, lo que permite a los investigadores centrarse en el trabajo conceptual de nivel superior. Sin requisa, a pesar de estos desarrollos prometedores, la evaluación de la investigación impulsada por la IA sigue siendo desafiante adecuado a la desliz de puntos de remisión estandarizados que pueden evaluar de guisa integral sus capacidades en diferentes dominios científicos.
Estudios recientes han abordado esta brecha al introducir puntos de remisión que evalúan a los agentes de IA en diversas tareas de ingeniería de software y estudios espontáneo. Si perfectamente existen marcos para probar agentes de IA en problemas perfectamente definidos como la procreación de código y la optimización del maniquí, la mayoría de los puntos de remisión actuales no admiten completamente los desafíos de investigación abiertos, donde podrían surgir múltiples soluciones. Por otra parte, estos marcos a menudo carecen de flexibilidad en la evaluación de diversos resultados de investigación, como algoritmos novedosos, arquitecturas de modelos o predicciones. Para avanzar en la investigación impulsada por la IA, existe la carencia de sistemas de evaluación que incorporen tareas científicas más amplias, faciliten la experimentación con diferentes algoritmos de estudios y acomoden diversas formas de contribuciones de investigación. Al establecer marcos tan completos, el campo puede acercarse a realizar sistemas de IA capaces de impulsar independientemente un progreso sabio significativo.
Investigadores del University College London, Universidad de Wisconsin – Madison, Universidad de Oxford, Meta y otros institutos han introducido un nuevo entorno y punto de remisión para evaluar y desarrollar agentes de LLM en investigación de IA. Este sistema, el primer entorno de recinto para tareas de ML, facilita el estudio de las técnicas RL para capacitar a los agentes de IA. El punto de remisión, MLGYM-Bench, incluye 13 tareas abiertas que abarcan visión por computadora, PNL, RL y teoría de juegos, que requieren habilidades de investigación del mundo vivo. Un entorno de seis niveles clasifica las capacidades del agente de investigación de IA, con MLGYM-Bench enfocándose en el Nivel 1: Mejoría de columna de almohadilla, donde los LLM optimizan los modelos pero carecen de contribuciones científicas.
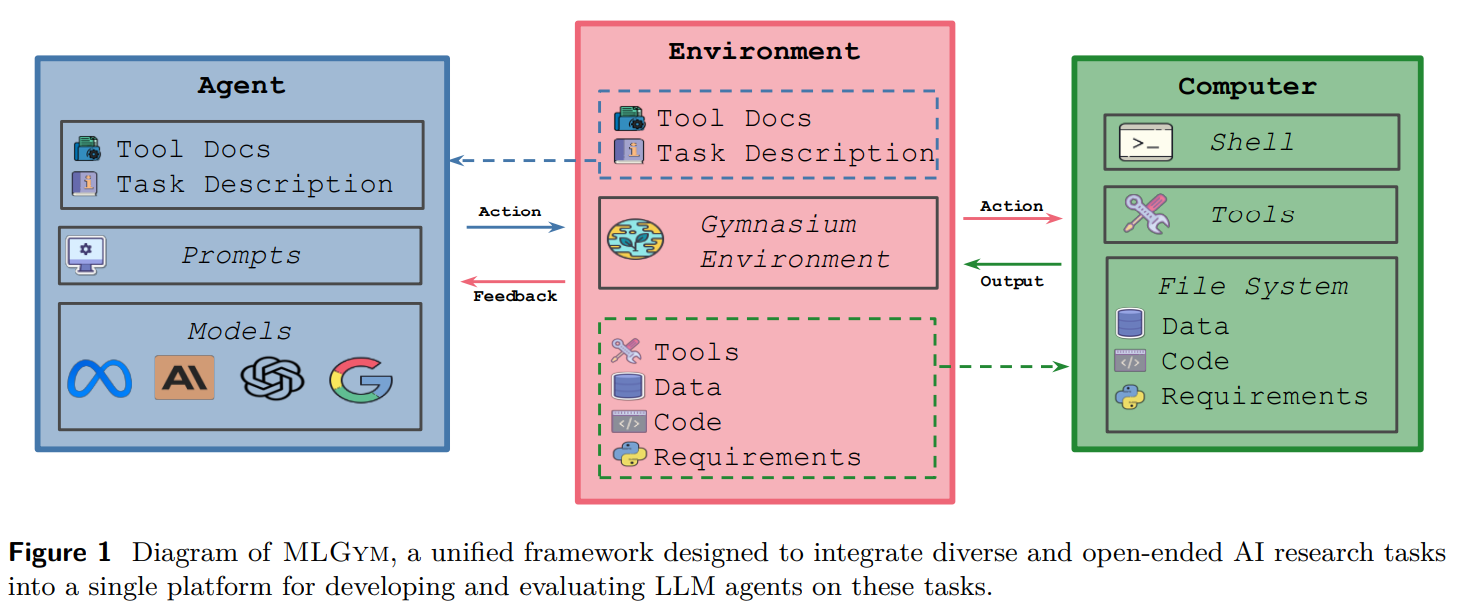
MLGYM es un entorno diseñado para evaluar y desarrollar agentes LLM para tareas de investigación de ML al habilitar la interacción con un entorno de shell a través de comandos secuenciales. Comprende cuatro componentes esencia: agentes, entorno, conjuntos de datos y tareas. Los agentes ejecutan comandos bash, administran el historial e integran modelos externos. El entorno proporciona un espacio de trabajo seguro basado en Docker con camino controlado. Los conjuntos de datos se definen por separado de las tareas, lo que permite la reutilización entre los experimentos. Las tareas incluyen scripts de evaluación y configuraciones para diversos desafíos de ML. Por otra parte, MLGYM ofrece herramientas para la búsqueda de humanidades, el almacenamiento de memoria y la acometividad iterativa, asegurando una experimentación y adaptabilidad eficientes en los flujos de trabajo de investigación de IA a dilatado plazo.
El estudio emplea un maniquí de agente SWE diseñado para el entorno MLGYM, luego de un circuito de toma de decisiones al estilo React. Cinco modelos de vanguardia: Openai O1-Preview, Gemini 1.5 Pro, Claude-3.5-Sonnet, Pasión-3-405B-Instructo y GPT-4O) se evalúan en entornos estandarizados. El rendimiento se evalúa utilizando puntajes AUP y perfiles de rendimiento, comparando modelos basados en el mejor intento y las mejores métricas de giro. OpenAI O1-Preview logra el rendimiento militar más detención, con Gemini 1.5 Pro y Claude-3.5-Sonnet de cerca. El estudio destaca los perfiles de rendimiento como un método de evaluación efectivo, lo que demuestra que la previsión OpenAI O1 se ubica constantemente entre los principales modelos en varias tareas.
En conclusión, el estudio destaca el potencial y los desafíos del uso de LLM como agentes de flujo de trabajo sabio. Mlgym y Mlgymbench demuestran adaptabilidad en varias tareas cuantitativas, pero revelan brechas de mejoramiento. Ampliarse más allá de ML, probar la divulgación interdisciplinaria y la evaluación de la novedad científica son áreas esencia para el crecimiento. El estudio enfatiza la importancia de la tolerancia de los datos para mejorar la colaboración y el descubrimiento. A medida que avanza la investigación de IA, los avances en el razonamiento, las arquitecturas de agentes y los métodos de evaluación serán cruciales. El fortalecimiento de la colaboración interdisciplinaria puede certificar que los agentes impulsados por la IA aceleren el descubrimiento sabio al tiempo que mantienen la reproducibilidad, la verificabilidad e integridad.
Probar el Papel y Página de Github. Todo el crédito por esta investigación va a los investigadores de este tesina. Por otra parte, siéntete desenvuelto de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 80k+ ml.
Sana Hassan, una pasante de consultoría en MarktechPost y estudiante de doble división en IIT Madras, le apasiona aplicar tecnología e IA para encarar los desafíos del mundo vivo. Con un gran interés en resolver problemas prácticos, aporta una nueva perspectiva a la intersección de la IA y las soluciones de la vida vivo.