
Mientras trabaja con Funciones Lambda definidas por el sucesor (UDF) en Desplazamiento al rojo del Amazonasconocer las mejores prácticas puede ayudarle a optimizar el progreso de funciones respectivas y someter los cuellos de botella comunes en el rendimiento y los costos innecesarios.
¿Se pregunta qué jerigonza de programación podría mejorar el rendimiento de su UDF, de qué otra forma puede utilizar los beneficios del procesamiento por lotes y qué consideraciones de trámite de concurrencia podrían aplicarse en su caso? En esta publicación, respondemos estas y otras preguntas brindando una visión consolidada de las prácticas para mejorar la eficiencia de Lambda UDF. Explicamos cómo designar un jerigonza de programación, utilizar las bibliotecas existentes de forma eficaz, minimizar el tamaño de la carga útil, encargar los datos devueltos y el procesamiento por lotes. Analizamos las consideraciones de escalabilidad y concurrencia tanto a nivel de cuenta como por función. Finalmente, examinamos los beneficios y matices de utilizar servicios externos con sus UDF Lambda.
Fondo
Amazon Redshift es un servicio rápido de almacenamiento de datos en la estrato a escalera de petabytes que hace que sea sencillo y rentable analizar datos utilizando SQL standard y herramientas de inteligencia empresarial existentes.
AWS Lambda es un servicio informático que le permite ejecutar código sin aprovisionar ni dirigir servidores, admite una amplia variedad de lenguajes de programación y escalera automáticamente sus aplicaciones.
Las UDF de Amazon Redshift Lambda le permiten ejecutar funciones Lambda directamente desde SQL, lo que desbloquea capacidades como la integración de API externa, la implementación de código unificado, una mejor escalabilidad informática y la separación de costos.
Requisitos previos
- Requisitos de configuración de la cuenta de AWS
- Conocimientos básicos de creación de funciones Lambda.
- Acercamiento al clúster de Amazon Redshift y permisos UDF.
Mejores prácticas de optimización del rendimiento
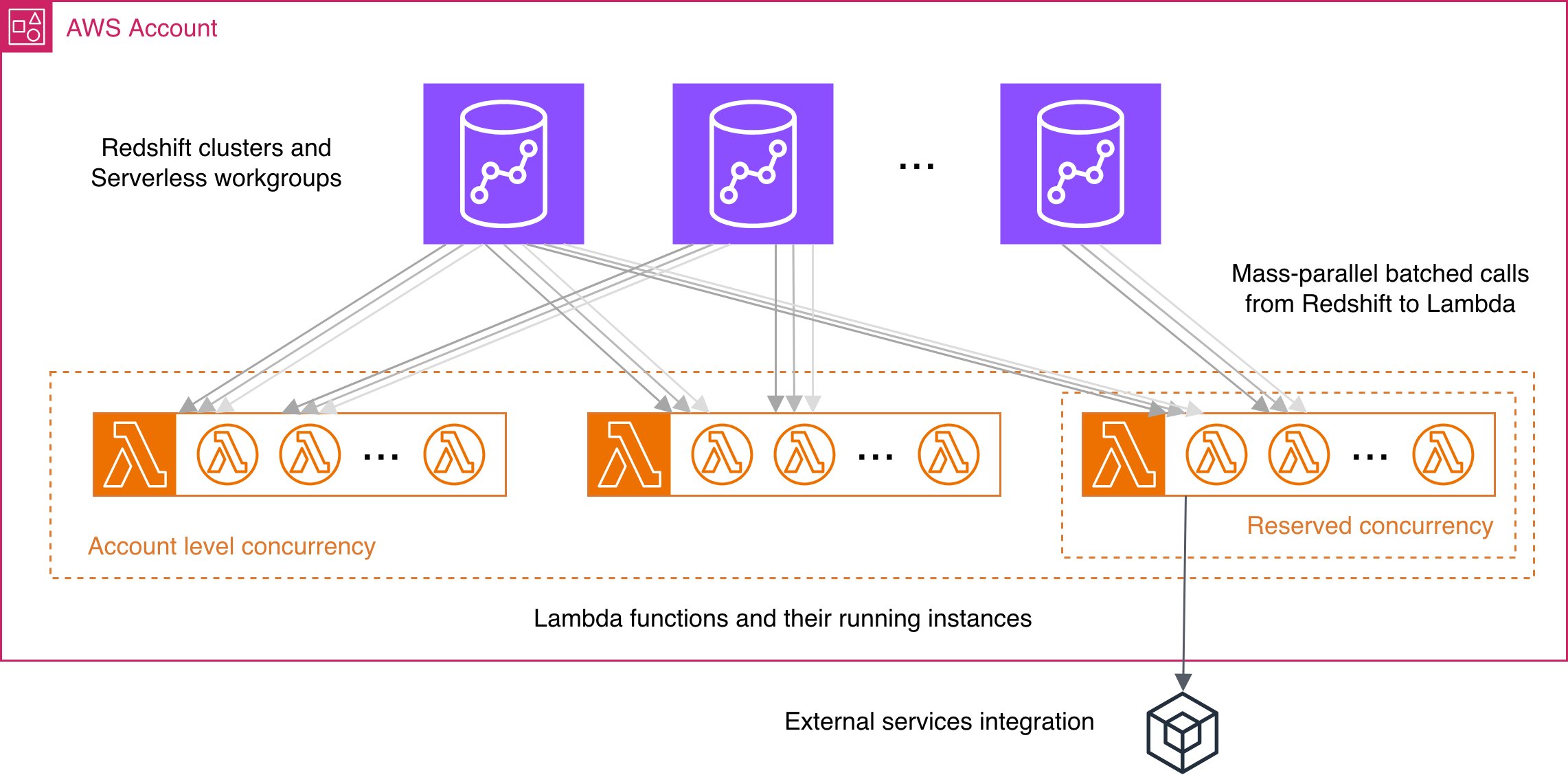
El posterior diagrama contiene las referencias visuales necesarias de la descripción de las mejores prácticas.
Utilice lenguajes de programación eficientes
Puede designar entre la amplia variedad de entornos de ejecución y lenguajes de programación de Lambda. Esta referéndum afecta tanto al rendimiento como a la facturación. Un código con veterano rendimiento puede ayudar a someter el costo de la computación Lambda y mejorar la velocidad de las consultas SQL. Las consultas SQL más rápidas además podrían ayudar a someter los costos de Redshift Serverless y potencialmente mejorar el rendimiento de los clústeres aprovisionados según su carga de trabajo y configuración específicas.
Al designar un jerigonza de programación para sus UDF Lambda, los puntos de remisión pueden ayudar a predecir las implicaciones de costo y rendimiento. El célebre equipo de muestrario de pruebas comparativas de Debian proporciona información habitable públicamente para diferentes idiomas en su resultados de micro-benchmark. Por ejemplo, sus Python contra Golang La comparación muestra una mejoría del tiempo de ejecución de hasta 2 órdenes de magnitud y una reducción del doble en el consumo de memoria si pudiera usar Golang en espacio de Python. Esto puede reflejarse positivamente tanto en el rendimiento de Lambda UDF como en los costos de Lambda para los respectivos escenarios.
Utilice bibliotecas existentes de forma efectivo
Para cada idioma proporcionado por Lambda, puede explorar toda la colección de bibliotecas para ayudarlo a implementar mejor las tareas desde el punto de aspecto de la velocidad y el consumo de bienes. Al realizar la transición a Lambda UDF, revise este aspecto detenidamente.
Por ejemplo, si su función Python manipula conjuntos de datos, podría equivaler la pena considerar usar el pandas biblioteca.
Evite datos innecesarios en cargas aperos
Lambda limita el tamaño de la carga útil de solicitud y respuesta a 6 megas para invocaciones sincrónicas. Teniendo esto en cuenta, Redshift está haciendo todo lo posible para agrupar los títulos de modo que la cantidad de lotes (y, por lo tanto, las llamadas Lambda) sea mínima, lo que reduce la sobrecarga de comunicación. Por lo tanto, los datos innecesarios, como los que se agregan para uso futuro pero que no se pueden procesar de inmediato, pueden someter la eficiencia de este esfuerzo.
Tenga en cuenta el tamaño de los datos devueltos
Oportuno a que, desde el punto de aspecto de Redshift, cada función Lambda es un sistema cerrado, es inasequible memorizar qué tamaño pueden tener los datos devueltos ayer de ejecutar la función. En este caso, si la carga útil devuelta es veterano que el término de carga útil de Lambda, Redshift tendrá que retornar a intentarlo con el porción saliente de un tamaño pequeño. Esto continuará hasta que se logre una carga útil de retorno adecuada. Si perfectamente es el mejor esfuerzo, el proceso puede crear gastos generales notables.
Para evitar esta sobrecarga, puede utilizar el conocimiento de su código Lambda para establecer directamente el tamaño mayor de porción en el banda de Redshift usando el MAX_BATCH_SIZE cláusula en su definición de Lambda UDF.
Utilice los beneficios de procesar títulos en lotes
Las llamadas por lotes brindan nuevas oportunidades de optimización para sus UDF. Tener un porción de muchos títulos pasados a la función a la vez permite utilizar varias técnicas de optimización.
Por ejemplo, memorización (almacenamiento en personalidad de resultados), cuando su función puede evitar ejecutar la misma razonamiento en los mismos títulos, reduciendo así el tiempo total de ejecución. La biblioteca standard de Python herramientas funcionales proporciona un almacenamiento en personalidad conveniente y decoradores de almacenamiento en personalidad menos utilizados recientemente (LRU) que implementan exactamente eso.
Escalabilidad y trámite de concurrencia.
Aumentar la simultaneidad a nivel de cuenta
Redshift utiliza un control de congestión liberal para proporcionar el mejor rendimiento en un entorno en extremo competitivo. Lambda proporciona una simultaneidad predeterminada término de 1.000 ejecuciones simultáneas por región de AWS para una cuenta. Sin incautación, si esto postrer no es suficiente, siempre puede solicitar el aumento de la cuota a nivel de cuenta para la simultaneidad de Lambda, que puede demorar a decenas de miles.
Tenga en cuenta que incluso con un espacio de simultaneidad restringido, nuestra implementación Lambda UDF hará el mejor esfuerzo para minimizar la congestión e igualar las posibilidades de llamadas a funciones en los clústeres de Redshift en su cuenta.
Restringir la concurrencia de funciones con concurrencia reservada
Si desea aislar algunas de las funciones de Lambda en un significación de simultaneidad restringido, por ejemplo, tiene un equipo de ciencia de datos que está experimentando con la reproducción de incrustaciones utilizando UDF de Lambda y no desea que afecten mucho la simultaneidad de Lambda de su cuenta, es posible que desee establecer una simultaneidad reservada para que operen sus funciones específicas.
Más información sobre concurrencia reservada en Lambda.
Integración y servicios externos.
Llame a servicios externos existentes para una ejecución óptima
En algunos casos, podría equivaler la pena considerar el uso de servicios o componentes externos existentes de su aplicación en espacio de retornar a implementar las mismas tareas usted mismo en el código Lambda. Por ejemplo, puede utilizar Open Policy Agent (OPA) para probar políticas, un servicio administrado Protegrity para proteger sus datos confidenciales; además hay una variedad de servicios que brindan celeridad de hardware para tareas computacionalmente pesadas.
Tenga en cuenta que algunos servicios tienen su propio control de lotes con un tamaño de porción acotado. Para eso implementamos una configuración de recuento de filas por lotes por función. MAX_BATCH_ROWS como cláusula en la definición de Lambda UDF.
Para obtener más información sobre la interacción del servicio extranjero mediante Lambda UDF, consulte los siguientes enlaces:
Conclusión
Las UDF de Lambda proporcionan una forma de ampliar las capacidades de su almacén de datos. Al implementar las mejores prácticas de esta publicación, puede ayudar a optimizar sus UDF de Lambda para ganar rendimiento y rentabilidad. Las conclusiones secreto de esta publicación son:
- optimización del rendimiento, que muestra cómo designar lenguajes y herramientas de programación eficientes, minimizar el tamaño de la carga útil y servirse el procesamiento por lotes para someter el tiempo y los costos de ejecución.
- trámite de escalabilidad, que muestra cómo configurar los ajustes de concurrencia apropiados tanto en los niveles de cuenta como de función para manejar diferentes cargas de trabajo de forma efectiva.
- eficiencia de integración, explicando cómo beneficiarse de los servicios externos para evitar reinventar la funcionalidad manteniendo un rendimiento perfecto.
Para obtener más información, visite el Documentación sobre corrimiento al rojo y explore los ejemplos de integración a los que se hace remisión en esta publicación.
Sobre el autor