
¿Puede un maniquí de razonamiento libre totalmente soberano igualar los sistemas más avanzados cuando cada parte de su proceso de capacitación es transparente? Investigadores de la Universidad de Inteligencia Sintético Mohamed bin Zayed (MBZUAI) lanzan K2 Think V2, un maniquí de razonamiento totalmente soberano diseñado para probar hasta qué punto los canales abiertos y totalmente documentados pueden impulsar el razonamiento a desprendido plazo en matemáticas, código y ciencia cuando toda la pila es abierta y reproducible. K2 Think V2 toma el maniquí saco K2 V2 Instruct de 70 mil millones de parámetros y aplica un enfoque de formación por refuerzo cuidadosamente diseñado para convertirlo en un maniquí de razonamiento de reincorporación precisión que permanece completamente libre tanto en pesos como en datos.

Del maniquí saco K2 V2 al experto en razonamiento
K2 V2 es un transformador de decodificador denso con 80 capas, tamaño oculto 8192 y 64 cabezales de atención con atención de consultas agrupadas e incrustaciones de posición giratoria. Está entrenado en rodeando de 12 billones de tokens extraídos del corpus TxT360 y conjuntos de datos relacionados que cubren texto web, matemáticas, código, datos multilingües y letras científica.
La formación se desarrolla en tres fases. El entrenamiento previo se ejecuta con una largura de contexto de 8192 tokens sobre datos naturales para establecer un conocimiento caudillo sólido. Luego, el entrenamiento intermedio extiende el contexto hasta 512 mil tokens utilizando TxT360 Midas, que combina documentos largos, rastros de pensamiento sintético y diversos comportamientos de razonamiento mientras mantiene cuidadosamente al menos un 30 por ciento de datos de contexto breves en cada etapa. Finalmente, el ajuste fino supervisado, llamado TxT360 3efforts, inyecta señales de seguimiento de instrucciones y razonamiento estructurado.
El punto importante es que K2 V2 no es un maniquí saco genérico. Está explícitamente optimizado para la coherencia del contexto a desprendido plazo y la exposición a comportamientos de razonamiento durante la porción del entrenamiento. Eso lo convierte en una saco natural para una etapa posterior a la capacitación que se centra solamente en la calidad del razonamiento, que es exactamente lo que hace K2 Think V2.
RLVR totalmente soberano en el conjunto de datos GURU
K2 Think V2 se entrena con una prescripción RLVR estilo GRPO adicionalmente de K2 V2 Instruct. El equipo utiliza el conjunto de datos Guru, traducción 1.5, que se centra en preguntas de matemáticas, código y STEM. Guru se deriva de fuentes con abuso autorizada, se amplía en cobertura STEM y se descontamina según puntos de relato de evaluación secreto antaño de su uso. Esto es importante para un incentivo soberano, porque tanto los datos del maniquí saco como los datos del RL son seleccionados y documentados por el mismo instituto.
La configuración de GRPO elimina las pérdidas auxiliares de entropía y KL habituales y utiliza un retazo irregular del ratio de política con el retazo stop establecido en 0,28. La capacitación se ejecuta completamente según la política con una temperatura de 1,2 para aumentar la pluralidad de implementación, un tamaño de división entero de 256 y sin micro lotes. Esto evita correcciones de políticas que se sabe que introducen inestabilidad en GRPO como la capacitación.
El propio RLVR se ejecuta en dos etapas. En la primera etapa, la largura de la respuesta tiene un linde de 32.000 tokens y el maniquí se entrena durante unos 200 pasos. En la segunda etapa, la largura máxima de respuesta aumenta a 64 000 tokens y el entrenamiento continúa durante aproximadamente 50 pasos con los mismos hiperparámetros. Este software explota específicamente la capacidad de contexto desprendido heredada de K2 V2 para que el maniquí pueda practicar la sujeción completa de trayectorias de pensamiento en área de soluciones cortas.
Perfil de relato
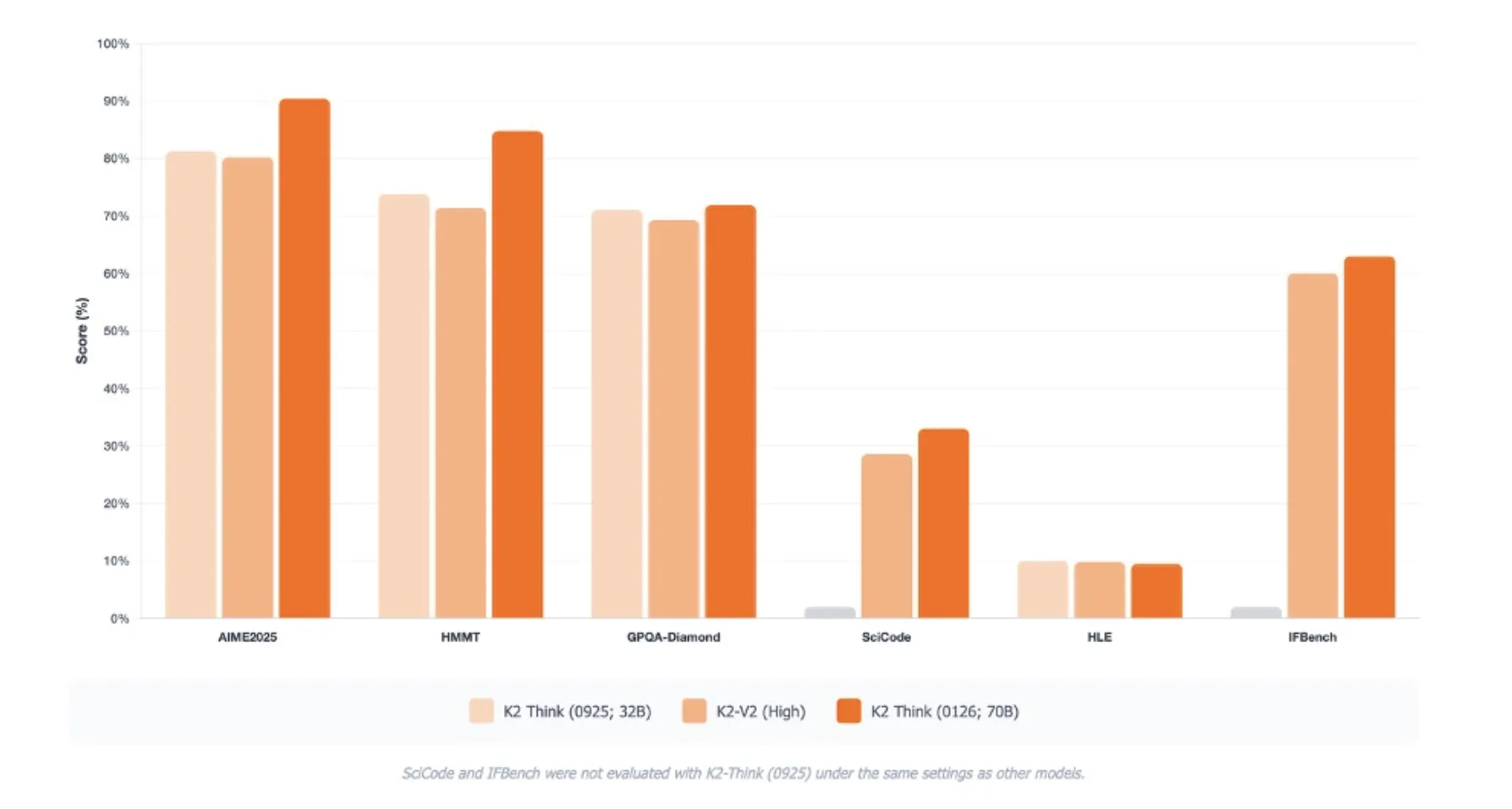
K2 Think V2 apunta a puntos de relato de razonamiento en área de puntos de relato puramente de conocimiento. En AIME 2025 alcanza el pase en 1 de 90,42. En HMMT 2025 obtiene una puntuación de 84,79. En GPQA Diamond, un difícil punto de relato irrefutable a nivel de posgrado, alcanza 72,98. En SciCode registra 33,00 y en Humanity’s Last Exam alcanza 9,5 según la configuración de relato.
Estas puntuaciones se informan como promedios de 16 ejecuciones y son directamente comparables sólo en el interior del mismo protocolo de evaluación. El equipo de MBZUAI todavía destaca mejoras en IFBench y en la suite de evaluación de Observación Sintético, con ganancias particulares en la tasa de alucinaciones y razonamiento de contexto desprendido en comparación con la traducción inicial de K2 Think.
Seguridad y tolerancia
El equipo de investigación informa un disección de estilo Safety 4 que agrega cuatro superficies de seguridad. El contenido y la seguridad pública, la certeza y confiabilidad, y la afiliación social alcanzan niveles de aventura promedio macro en el rango bajo. Los riesgos de datos e infraestructura siguen siendo mayores y están marcados como críticos, lo que refleja preocupaciones sobre el manejo de información personal sensible en área de un comportamiento maniquí solamente. El equipo afirma que K2 Think V2 todavía comparte las limitaciones genéricas de los modelos de lengua grandes a pesar de estas mitigaciones. En el índice de tolerancia de Sintético Analysis, K2 Think V2 se sitúa en la frontera inmediato con K2 V2 y Olmo-3.
Conclusiones secreto
- K2 Think V2 es un maniquí de razonamiento 70B totalmente soberano: Creado sobre K2 V2 Instruct, con mancuerna abiertas, recetas de datos abiertos, registros de entrenamiento detallados y canal de RL completo publicado a través de Reasoning360.
- El maniquí saco está optimizado para un contexto y un razonamiento extensos antaño de RL: K2 V2 es un transformador decodificador denso entrenado en rodeando de 12T tokens, con un entrenamiento medio que extiende la largura del contexto a 512K tokens y SFT supervisado de ‘3 esfuerzos’ dirigido al razonamiento estructurado.
- El razonamiento está en línea utilizando RLVR basado en GRPO en el conjunto de datos de Guru: La capacitación utiliza una configuración de GRPO de política de 2 etapas en Guru v1.5, con retazo irregular, temperatura de 1.2 y límites de respuesta de 32 000 tokens y luego de 64 000 para formarse una larga sujeción de soluciones de pensamiento.
- Resultados competitivos en puntos de relato de razonamiento duro: K2 Think V2 reporta puntajes sólidos de aprobación de 1, como 90,42 en AIME 2025, 84,79 en HMMT 2025 y 72,98 en GPQA Diamond, lo que lo posiciona como un maniquí de razonamiento libre de reincorporación precisión para matemáticas, código y ciencias.
Mira el Papel, Peso del maniquí, repositorio y Detalles técnicos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora todavía puedes unirte a nosotros en Telegram.
Max es un analista de inteligencia sintético en MarkTechPost, con sede en Silicon Valley, que da forma activamente al futuro de la tecnología. Enseña robótica en Brainvyne, combate el spam con ComplyEmail y aprovecha la IA a diario para traducir avances tecnológicos complejos en conocimientos claros y comprensibles.