
Este blog desglose las opciones de precios e implementación disponibles, y herramientas que admiten implementaciones de IA escalables y conscientes de costos.
Cuando está construyendo con IA, cada audacia cuenta, especialmente cuando se proxenetismo de costos. Ya sea que recién esté comenzando o prosperar aplicaciones de escalón empresarial, lo zaguero que desea es el precio impredecible o la infraestructura rígida que lo ralentiza. Azure Openai está diseñado con eso en mente: lo suficientemente flexible para experimentos tempranos, lo suficientemente potente para las implementaciones globales y el precio de los precios para que coincida en cómo lo usa positivamente.
Desde nuevas empresas hasta Fortune 500, más de 60,000 clientes están eligiendo Azure Ai Foundry, no solo para entrar a modelos fundamentales y de razonamiento—Pero porque se cumple con ellos donde están, con opciones de implementación y modelos de precios que se alinean con las deyección comerciales reales. Se proxenetismo de poco más que IA: se proxenetismo de hacer que la innovación sea sostenible, escalable y accesible.
Este blog desglose las opciones de precios e implementación disponibles, y herramientas que admiten implementaciones de IA escalables y conscientes de costos.
Modelos de precios flexibles que coincidan con sus deyección
Azure OpenAI admite tres modelos de precios distintos diseñados para cumplir con diferentes perfiles de carga de trabajo y requisitos comerciales:
- Unificado—Pas cargas de trabajo explosivas o variables donde quieres sufragar solo por lo que usas.
- Provisión—Pas aplicaciones de parada rendimiento y sensibles al rendimiento que requieren un rendimiento consistente.
- Conjunto—Pas trabajos a gran escalera que se pueden procesar asincrónicamente a una tarifa con descuento.
Cada enfoque está diseñado para prosperar con usted, ya sea validando un caso de uso o implementando en todas las unidades de negocios.

Unificado
El Unificado El maniquí de implementación es ideal para equipos que desean flexibilidad. Se le cobra por emplazamiento API basada en tokens consumidos, lo que ayuda a optimizar los presupuestos durante los períodos de último uso.
Mejor para: Incremento, prototipos o cargas de trabajo de producción con demanda variable.
Puedes designar entre:
- Despliegues globales: Para certificar una latencia óptima entre las geografías.
- Zonas de datos de OpenAI: Para obtener más flexibilidad y control sobre la privacidad y la residencia de los datos.
Con todas las selecciones de implementación, los datos se almacenan en reposo en el interior de la región elegida de Azure de su apelación.
Conjunto
- El Conjunto maniquí está diseñado para una inferencia de entrada eficiencia a gran escalera. Los trabajos se envían y procesan asincrónicamente, con respuestas devueltas en el interior de las 24 horas, hasta un 50% menos que el precio normalizado completo. Conjunto incluso características soporte de carga de trabajo a gran escalera para procesar solicitudes masivas con costos más bajos. Escalera sus consultas de lotes masivas con fricción mínima y manejan eficientemente las cargas de trabajo a gran escalera para achicar el tiempo de procesamiento, con un cambio objetivo de 24 horas, hasta 50% menos de costo que el normalizado completo.
Mejor para: Tareas de gran cuerpo con deyección de latencia flexibles.
Los casos de uso típicos incluyen:
- Procesamiento de datos a gran escalera y procreación de contenido.
- Tuberías de transformación de datos.
- Evaluación del maniquí en extensos conjuntos de datos.
Cliente en obra: Ontada
Ontada, una compañía de McKesson, utilizó la API por lotes para elaborar más de 150 millones de documentos de oncología en ideas estructuradas. Aplicando LLM en 39 tipos de cáncer, desbloquearon el 70% de los datos previamente inaccesibles y redujeron el tiempo de procesamiento de documentos en un 75%. Aprenda más en el Estudio de caso de Ontada.
Provisión
El Provisión El maniquí proporciona un rendimiento dedicado a través de unidades de rendimiento aprovisionadas (PTU). Esto permite la latencia estable y el parada rendimiento, ideal para los casos de uso de producción que requieren rendimiento o procesamiento en tiempo actual a escalera. Los compromisos pueden ser por hora, mensual o anual con los descuentos correspondientes.
Mejor para: Cargas de trabajo empresariales con demanda predecible y la pobreza de un rendimiento consistente.
Casos de uso comunes:
- Escenarios de recuperación de parada cuerpo y procesamiento de documentos.
- Operaciones del centro de llamadas con horas de tráfico predecibles.
- Asistente minorista con rendimiento constantemente parada.
Clientes en obra: Visier y UBS
- Visor Construido «Vee», un asistente generativo de IA que sirve hasta 150,000 usuarios por hora. Al usar las PTU, Visier mejoró los tiempos de respuesta en tres veces en comparación con los modelos de suscripción por uso y costos de enumeración reducidos a escalera. Lea el estudio de caso.
- UBS Creado ‘UBS Red’, una plataforma de IA segura que respalda a 30,000 empleados en todas las regiones. Las PTU permitieron al parcialidad ofrecer un rendimiento confiable con implementaciones específicas de la región en Suiza, Hong Kong y Singapur. Lea el estudio de caso.
Tipos de implementación para normalizado y aprovisionados
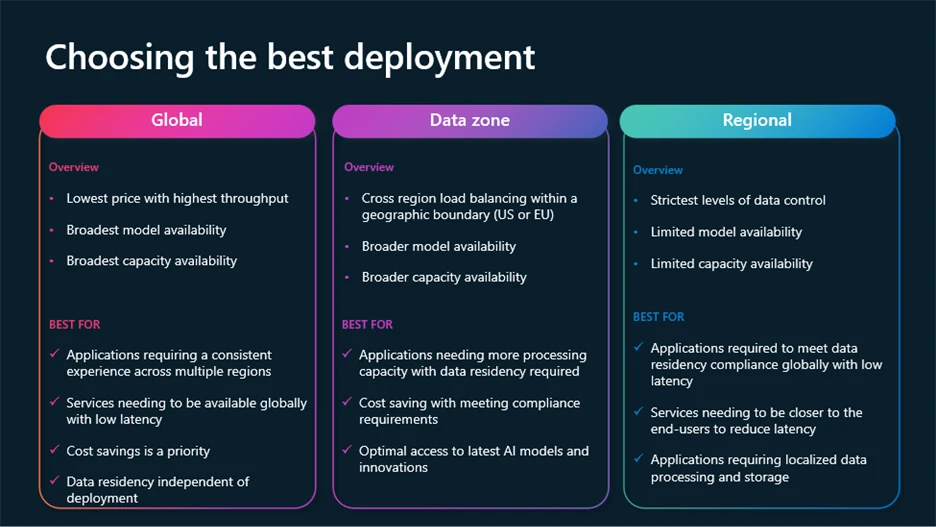
Para cumplir con los crecientes requisitos de control, cumplimiento y optimización de costos, Azure OpenAI admite múltiples tipos de implementación:
- Integral: Las solicitudes de rutas más rentables a través de la infraestructura completo de Azure, con residencia de datos en reposo.
- Regional: Mantiene el procesamiento de datos en una región de Azure específica (28 acondicionado hoy), con residencia de datos tanto en reposo como en el procesamiento en la región seleccionada.
- Zonas de datos: Ofrece un punto medio: el procesamiento permanece en el interior de las zonas geográficas (UE o EE. UU.) Para un viejo cumplimiento sin sobrecarga de costos regionales completos.
Las implementaciones de zona completo y de datos están disponibles en modelos normalizado, aprovisionados y por lotes.
Las características dinámicas lo ayudan a achicar costos mientras optimizan el rendimiento
Varias nuevas características dinámicas diseñadas para ayudarlo a obtener los mejores resultados para costos más bajos ahora están disponibles.
- Router maniquí para Azure Ai Foundry: Un maniquí de chat de IA desplegable que selecciona automáticamente el mejor maniquí de chat subyacente para objetar a un mensaje determinado. Valentísimo para diversos casos de uso, el enrutador maniquí ofrece un parada rendimiento mientras ahorra en costos de cálculo cuando sea posible, todo empaquetado como una implementación de un solo maniquí.
- Soporte de carga de trabajo a gran escalera por lotes: Procesa solicitudes masivas con costos más bajos. Manejar eficientemente las cargas de trabajo a gran escalera para achicar el tiempo de procesamiento, con respuesta objetivo de 24 horas, a 50% menos de costo que el normalizado completo.
- Desbordamiento dinámico de rendimiento aprovisionado: Proporciona un desbordamiento sin interrupciones para sus aplicaciones de parada rendimiento sobre implementaciones aprovisionadas. Resolver las explosiones de tráfico sin interrupción del servicio.
- Gusto de personalidad: Optimización incorporada para patrones de inmediato repetibles. Acelera los tiempos de respuesta, el rendimiento de las escalas y ayuda a achicar significativamente los costos de tokens.
- Tablero de monitoreo de Azure OpenAI: Continuamente rastrear el rendimiento, el uso y la confiabilidad en sus implementaciones.
Para obtener más información sobre estas características y cómo utilizar las últimas innovaciones en los modelos Azure Ai Foundry, vea esta sesión de Build 2025 en Optimización de aplicaciones Gen AI a escalera.
Más allá de la flexibilidad de los precios y la implementación, Azure OpenAi se integra con Trámite de costos de Microsoft Herramientas para dar a los equipos visibilidad y control sobre su desembolso de IA.
Las capacidades incluyen:
- Exploración de costos en tiempo actual.
- Creación de presupuesto y alertas.
- Soporte para entornos de múltiples nubes.
- Asignación de costos y devolución de cargo por equipo, tesina o unidad.
Estas herramientas ayudan a los equipos de finanzas e ingeniería a mantenerse alineados, lo que es más sencillo comprender las tendencias de uso, rastrear las optimizaciones y evitar sorpresas.
Integración incorporada con el ecosistema de Azure
Azure OpenAi es parte de un ecosistema más prócer que incluye:
Esta integración simplifica el ciclo de vida de extremo a extremo de la construcción, personalización y papeleo de soluciones de IA. No tiene que unir plataformas separadas, y eso significa un tiempo de valencia más rápido y menos dolores de cabecera operativos.
Una pulvínulo de confianza para Enterprise AI
Microsoft se compromete a habilitar la IA que sea segura, privada y segura. Ese compromiso aparece no solo en la política, sino en el producto:
- Iniciativa segura futura: Un enfoque integral de seguridad por diseño.
- Principios de IA responsables: Constante en herramientas, documentación y flujos de trabajo de implementación.
- Cumplimiento de escalón empresarial: Cubriendo la residencia de datos, los controles de golpe y la auditoría.
Comience con Azure Ai Foundry