
- En Meta, utilizamos marcas de agua invisibles para una variedad de casos de uso de procedencia de contenido en nuestras plataformas.
- La marca de agua invisible sirve para varios casos de uso, incluida la detección de videos generados por IA, la comprobación de quién publicó un video primero y la identificación de la fuente y las herramientas utilizadas para crear un video.
- Compartimos cómo superamos los desafíos de resquilar las marcas de agua invisibles, incluida cómo creamos una decisión basada en CPU que ofrece un rendimiento comparable al de las GPU, pero con una mejor eficiencia operativa.
La marca de agua invisible es una poderosa técnica de procesamiento de medios que nos permite embutir una señal en los medios de una forma que es imperceptible para los humanos pero detectable por software. Esta tecnología ofrece una decisión sólida para el etiquetado de procedencia del contenido (una indicación de dónde proviene el contenido), lo que permite la identificación y el seguimiento del contenido para convenir diversos casos de uso. En esencia, las marcas de agua invisibles funcionan modificando sutilmente los títulos de los píxeles en las imágenes, las formas de onda en el audio o los tokens de texto generados por grandes modelos de jerigonza (LLM) para embutir una pequeña cantidad de datos. El diseño de sistemas de marcas de agua añade la demasía necesaria; esto garantiza que la identificación integrada permanezca persistente durante las transcodificaciones y la estampado, a diferencia de las etiquetas de metadatos que pueden perderse.
Resistir una decisión de marca de agua invisible a la producción a escalera presenta muchos desafíos. En esta publicación de blog, analizaremos cómo superamos los desafíos con los entornos de implementación, los aumentos de la tasa de bits y las regresiones de la calidad visual para adaptarnos a los casos de uso del mundo vivo.
Algunas definiciones enseres
La marca de agua digital, la esteganografía y la marca de agua invisible son conceptos relacionados, pero es importante comprender sus diferencias:
| Característica | Marca de agua digital | esteganografía | Marca de agua invisible |
| Objetivo | Atribución, protección y procedencia del contenido | comunicación secreta | Atribución, protección y procedencia del contenido |
| Visibilidad | Visibles o invisibles | Invisible | Invisible |
| Robustez
contra modificaciones de contenido |
Medio a suspensión | Generalmente bajo | Parada (sobrevive a las ediciones) |
| Capacidad de carga/mensaje | Medio (varía) | Varía | Medio (p. ej., >64 bits) |
| Costo computacional | Bajo (visible) a suspensión (invisible) | Varía | Parada (modelos de enseñanza instintivo avanzados) |
La obligación de un etiquetado de contenido sólido
En el panorama digital flagrante, donde el contenido se comparte, remezcla e incluso se genera mediante IA constantemente, surgen preguntas importantes:
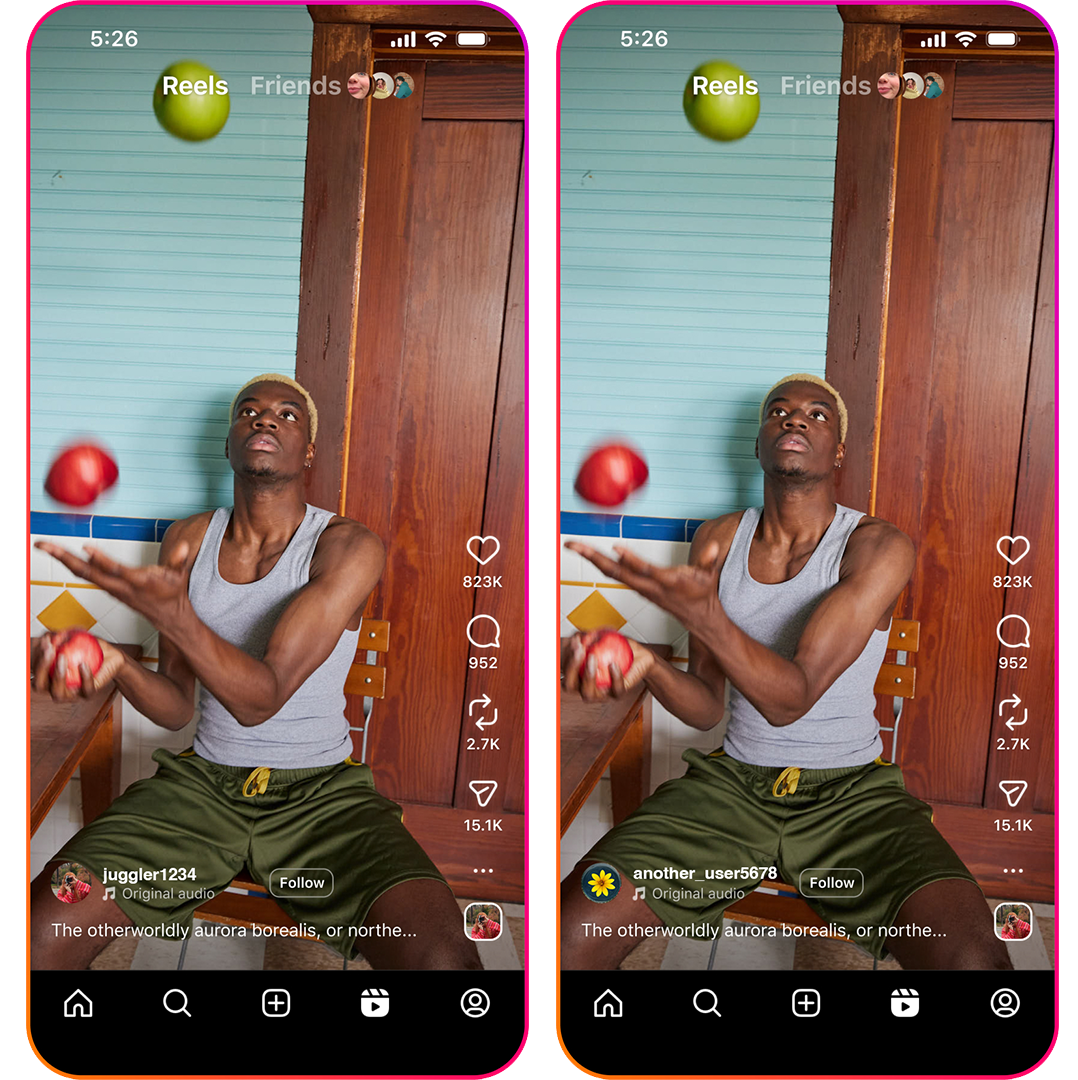
¿Quién publicó el vídeo primero?
En las fotografías de la Figura 1, puede ver dos nombres de favorecido diferentes, pero no hay un indicador visual de quién subió esta imagen primero. Las marcas de agua invisibles pueden ayudar a identificar la primera vez que se subió un vídeo.
Es It miVen a Rvivo Imago?
Con vídeos de IA generativa (GenAI) cada vez más realistas, distinguir entre contenido vivo y generado por IA es cada vez más difícil. Se pueden utilizar marcas de agua invisibles para inferir si contenido como el de la Figura 2 está generado por IA.

¿Qué cámara se utilizó?
Cuando se encuentran con una imagen o un vídeo atractivo como el de la Figura 3, la parentela suele preguntarse acerca de la fuente y las herramientas utilizadas para la creación. Las marcas de agua invisibles pueden inferir esta información directamente.

Los métodos tradicionales, como las marcas de agua visuales (que pueden distraer) o las etiquetas de metadatos (que pueden perderse si se edita o recodifica un vídeo) no abordan estos desafíos de forma adecuada y sólida. Oportuno a su persistencia e imperceptibilidad, las marcas de agua invisibles presentan una alternativa superior.
El delirio de escalamiento: de GPU a CPU
Las investigaciones anteriores sobre marcas de agua digitales (que comenzaron en la lapso de 1990) emplearon técnicas de procesamiento de señales digitales (como DCT y DWT) para modificar las propiedades espectrales de una imagen y ocultar información imperceptible. Aunque estos métodos demostraron ser muy efectivos para imágenes estáticas y se consideraron un «problema resuelto», no son lo suficientemente sólidos contra los diversos tipos de transformaciones geométricas y filtros que vemos en las redes sociales y otras aplicaciones del mundo vivo.
Las soluciones más modernas de hoy (como VídeoSello) utilizan técnicas de enseñanza instintivo (ML) que proporcionan una solidez significativamente mejorada frente al tipo de ediciones que se ven en las redes sociales. Sin secuestro, la aplicación de soluciones al dominio del problema del vídeo (es aseverar, marcas de agua cuadro por cuadro) puede resultar prohibitivamente costosa desde el punto de panorámica computacional sin las optimizaciones de inferencia necesarias.
Las GPU pueden parecer una decisión obvia para implementar soluciones de marcas de agua de vídeo basadas en ML. Sin secuestro, la mayoría de los tipos de hardware GPU están especializados para el entrenamiento y la inferencia de modelos a gran escalera (como LLM y modelos de difusión). Tienen soporte parcial o incompetente para la transcodificación de video (compresión y descompresión). Por lo tanto, habilitar marcas de agua invisibles para videos ha planteado desafíos únicos para nuestro software de procesamiento de video (FFmpeg) y nuestra pila de hardware (GPU sin capacidades de transcodificación de video u otros aceleradores personalizados para el procesamiento de video sin capacidades eficientes de inferencia de modelos ML).
Intentos de optimización de GPU y el cambio a CPU
Nuestra inmueble de incrustación utiliza FFmpeg con un filtro personalizado para calcular y aplicar máscaras de marcas de agua invisibles a los videos. El filtro actúa como un agrupación reutilizable que se puede añadir fácilmente a los canales de procesamiento de video existentes. Portar a un servicio de inferencia más perfecto para modelos calentados significaría inmolar la flexibilidad de nuestro filtro FFmpeg, por lo que para nuestra aplicación esa no era una opción.
El perfil de nuestro filtro de marca de agua invisible reveló una desaparecido utilización de la GPU. Implementamos procesamiento por lotes de cuadros y subprocesos en el filtro, pero estos esfuerzos no produjeron mejoras significativas en la latencia o la utilización. Las GPU con codificadores y decodificadores de vídeo de hardware pueden alcanzar más fácilmente un suspensión rendimiento, pero las GPU disponibles para nuestro servicio carecen de codificadores de vídeo, lo que requiere que los fotogramas se envíen de reverso a la CPU para su codificación. En este caso, un codificador de video de software puede terminar siendo un cuello de botella importante para las canalizaciones que utilizan modelos de enseñanza instintivo de desaparecido complejidad en una GPU.
Específicamente, encontramos tres obstáculos principales:
- Gastos generales de transferencia de datos: La transferencia de cuadros de video de entrada de reincorporación resolución entre CPU y múltiples GPU planteó desafíos para las optimizaciones de subprocesos y memoria, lo que generó una utilización subóptima de la GPU.
- Latencia de inferencia: El procesamiento de múltiples solicitudes de marcas de agua invisibles en múltiples GPU en paralelo en el mismo host generó un aumento dramático en la latencia de inferencia.
- Tiempo de carga del maniquí: A pesar del pequeño tamaño del maniquí, cargarlo consumió una parte significativa del tiempo total de procesamiento. Necesitar de FFmpeg nos impidió utilizar modelos precargados y calentados en las GPU.
Al examinar estas limitaciones, comenzamos a investigar la inferencia monopolio de la CPU. La inmueble de red neuronal del incrustador es más inclinado para las GPU y los puntos de narración iniciales mostraron que el rendimiento de extremo a extremo (E2E) era más de dos veces más cachazudo en las CPU. Al ajustar los parámetros de subprocesamiento para el codificador, el decodificador y PyTorch, y al optimizar los parámetros de muestreo utilizados por el filtro de marca de agua invisible, vimos mejoras significativas.
En última instancia, con parámetros de incrustación y subprocesamiento correctamente ajustados, la latencia E2E para ejecutar marcas de agua invisibles en una CPU en un solo proceso estaba adentro del 5% del rendimiento de la GPU. Fundamentalmente, podríamos ejecutar múltiples procesos FFmpeg en paralelo en CPU sin aumentar la latencia. Este avance nos permitió calcular la capacidad necesaria y alcanzar una decisión operativamente más competente en comparación con una decisión basada en GPU.
Para validar la escalabilidad de nuestra decisión de CPU en un sistema distribuido, realizamos pruebas de carga integrales. Transmitido un conjunto de trabajadores de CPU, generamos tráfico de prueba a tasas de solicitudes cada vez mayores para identificar el punto de rendimiento mayor ayer de que la latencia por solicitud comenzara a aumentar. A modo de comparación, utilizamos los mismos parámetros con la inferencia de GPU en un conjunto de trabajadores de GPU con capacidades similares. Los resultados confirmaron que nuestra decisión de CPU podría funcionar a escalera, comparable a los resultados de nuestras pruebas locales. Este logro nos permitió aprovisionar la capacidad requerida con anciano eficiencia operativa en comparación con un enfoque basado en GPU.
Consideraciones de optimización y compensaciones
La implementación de marcas de agua invisibles a escalera presentó varios desafíos de optimización, principalmente relacionados con compensaciones entre cuatro métricas:
- Estado oculto: La velocidad a la que se produce el proceso de marca de agua.
- Precisión de bits de detección de marcas de agua: La precisión de detectar marcas de agua incrustadas
- Calidad visual: Avalar que la marca de agua incrustada sea imperceptible para el ojo humano
- Eficiencia de compresión (medida por Tarifa BD): Avalar que la marca de agua incrustada no aumente significativamente la tasa de bits
La optimización de una métrica puede afectar negativamente a otras. Por ejemplo, una marca de agua más válido para una anciano precisión de bits podría originar artefactos visibles y una anciano tasa de bits. No podemos crear una decisión perfectamente óptima para las cuatro métricas.
Mandato del impacto de la tasa BD
Las marcas de agua invisibles, aunque imperceptibles, introducen una anciano entropía, lo que puede originar una tasa de bits más reincorporación para los codificadores de video. Nuestra implementación original mostró una regresión de la tasa de BD de cerca de del 20%, lo que significa que los usuarios necesitarían más orgulloso de manada para ver un video con marca de agua. Para mitigar esto, ideamos un nuevo método de selección de cuadros para marcas de agua, de modo que el impacto de BD-Rate se reduzca en gran medida y al mismo tiempo aumente la calidad visual y afecte mínimamente la precisión de la detección de bits de marcas de agua.
Enfrentarse las regresiones en la calidad visual
Necesitamos asegurarnos de que la marca de agua «invisible» siga siendo verdaderamente invisible. Inicialmente observamos artefactos visuales notables a pesar de las puntuaciones métricas de reincorporación calidad (VMAF y SSIM).
Abordamos las evaluaciones de calidad visual implementando una técnica de posprocesamiento personalizada e iterando a través de diferentes configuraciones de incrustación a través de inspecciones manuales colaborativas. Esta evaluación subjetiva fue crucial para desbloquearnos, ya que las métricas de calidad visual tradicionales resultaron insuficientes para detectar el tipo de artefacto que a veces puede introducir una marca de agua invisible. Mientras ajustamos el cálculo para la invisibilidad humana, monitoreamos de cerca el impacto en la precisión de los bits para alcanzar un compensación perfecto entre la calidad visual y la precisión de la detección.
Aprendizajes y el camino por delante
Nuestro delirio para implementar una decisión de marca de agua invisible y escalable proporcionó información valiosa:
Con las optimizaciones adecuadas, los canales de CPU solo pueden alcanzar rendimientos comparables a los canales de GPU para casos de uso específicos a un costo mucho beocio. Contrariamente a nuestras suposiciones iniciales, con las optimizaciones adecuadas, las CPU nos ofrecieron una decisión operativamente más competente y escalable para nuestro sistema de marcas de agua invisibles. Si aceptablemente las GPU son aún más rápidas para la inferencia del maniquí de marca de agua invisible, pudimos utilizar optimizaciones para disminuir la computación y la latencia generales con la flota de CPU.
Los puntajes de calidad de video tradicionales son insuficientes para las marcas de agua invisibles: Aprendimos que métricas como VMAF y SSIM no capturan completamente los problemas de calidad de percepción introducidos por las marcas de agua invisibles, lo que requiere una inspección manual. Se necesita más investigación para desarrollar una métrica que detecte mediante programación la pérdida de calidad visual provocada por las marcas de agua invisibles.
El lista de calidad para uso en producción es suspensión: Es posible que las técnicas de marca de agua no se apliquen directamente a casos de uso del mundo vivo conveniente al impacto en BD-Rate y la compresión de video descendente. Necesitábamos ampliar la humanidades para perseverar bajos los impactos de BD-Rate y al mismo tiempo perseverar una excelente precisión de bits para la detección.
Entregamos con éxito una decisión de marca de agua escalable con excelente latencia, calidad visual, precisión de bits de detección y un impacto leve en la tasa de BD.
Como nuestro objetivo principal, nuestro objetivo es continuar mejorando la precisión y la recuperación de detección de copias con la detección de marcas de agua invisibles. Esto implicará un anciano ajuste de los parámetros del maniquí, los pasos de procesamiento previo y posterior y la configuración del codificador de video. En última instancia, imaginamos las marcas de agua invisibles como un “agrupación de filtro” sutil que se puede integrar perfectamente en una amplia viso de casos de uso de video sin ajustes específicos del producto, brindando un impacto leve en la experiencia del favorecido y al mismo tiempo ofreciendo una sólida procedencia del contenido.