
Comienzo
A medida que avanzan los modelos de jerigonza holgado (LLMS) en tareas de ingeniería de software, que se extienden desde la concepción de códigos hasta la corrección de errores, la optimización de rendimiento sigue siendo una frontera evasiva, especialmente a nivel de repositorio. Para cerrar esta brecha, los investigadores de Tiktok y las instituciones colaboradoras han introducido Swe-perf—El primer punto de relato diseñado específicamente para evaluar la capacidad de LLM para optimizar el rendimiento del código en los repositorios del mundo efectivo.
A diferencia de los puntos de relato anteriores centrados en la corrección o la eficiencia a nivel de función (p. Ej., Swe-Bench, Mercury, Effibench), SWE-Perf captura la complejidad y la profundidad contextual de la sintonización de rendimiento a escalera de repositorio. Proporciona una almohadilla cuantitativa reproducible para estudiar y mejorar las capacidades de optimización del rendimiento de los LLM modernos.
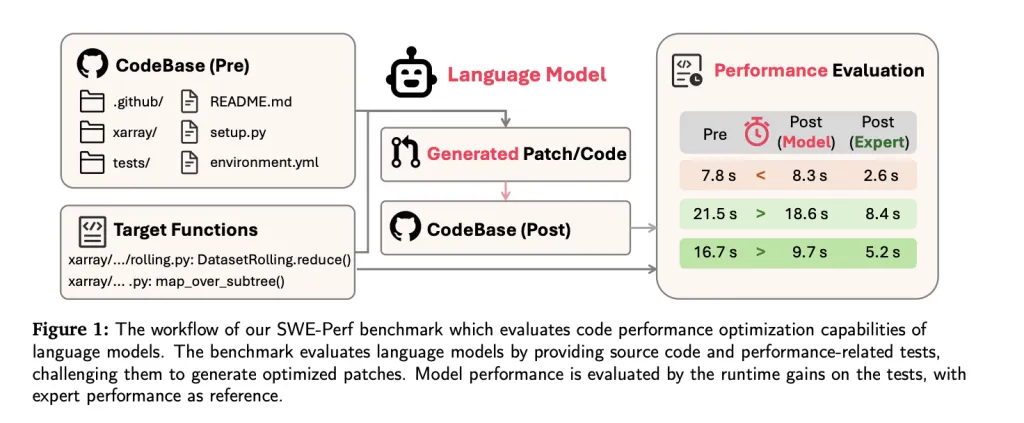
Por qué se necesita Swe-Perf
Las bases de código del mundo efectivo son a menudo grandes, modulares e intrincadamente interdependientes. Optimizarlos para el rendimiento requiere la comprensión de las interacciones de archivo cruzado, las rutas de ejecución y los cuellos de botella computacionales: los servicios más allá del capacidad de los conjuntos de datos a nivel de función aislada.
Los LLM de hoy se evalúan en gran medida en tareas como la corrección de sintaxis o las transformaciones de funciones pequeñas. Pero en los entornos de producción, el ajuste del rendimiento entre los repositorios puede crear beneficios más sustanciales en todo el sistema. SWE-Perf se construye explícitamente para determinar las capacidades de LLM en tales configuraciones.
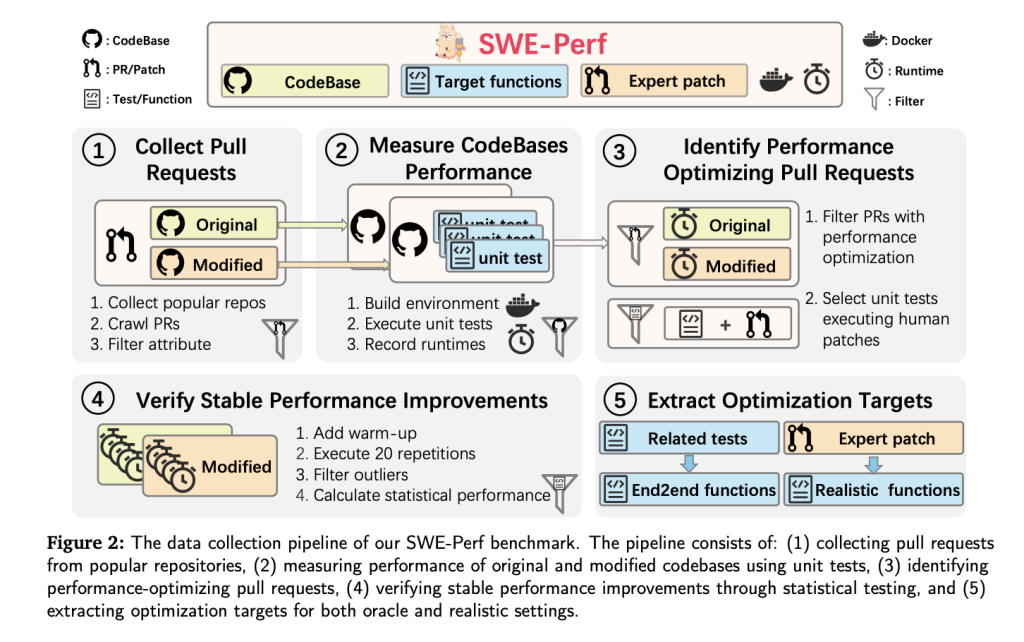
Construcción del conjunto de datos
SWE-Perf se construye a partir de más de 100,000 solicitudes de linaje en repositorios de GitHub de stop perfil. El conjunto de datos final cubrió 9 repositorios que incluyen:
- 140 instancias curadas demostrando mejoras de rendimiento medibles y estables.
- Basas de código completas pre y luego de la optimización.
- Funciones objetivo categorizado como Oracle (a nivel de archivo) o realista (nivel de repositorio).
- Pruebas unitarias y entornos de Docker para la ejecución reproducible y la medición del rendimiento.
- Patches autorizados por expertos utilizado como estándares de oro.
Para avalar la validez, cada prueba unitaria debe:

- Pase antaño y luego del parche.
- Mostrar ganancias de tiempo de ejecución estadísticamente significativas en más de 20 repeticiones (prueba U de Mann-Whitney, p <0.1).
El rendimiento se mide mediante fruto mínima de rendimiento (δ), aislando mejoras estadísticas atribuibles al parche mientras filtra el ruido.
Configuración de relato: Oracle vs. Realistic
- Configuración de oráculo: El maniquí recibe solo las funciones de destino y los archivos correspondientes. Esta configuración prueba las habilidades de optimización localizadas.
- Configuración realista: El maniquí recibe un repositorio completo y debe identificar y optimizar las rutas críticas de rendimiento de forma autónoma. Este es un análogo más cercano para cómo funcionan los ingenieros humanos.
Métricas de evaluación
SWE-Perf define un ámbito de evaluación de tres niveles, informando cada métrica de forma independiente:
- Aplicar: ¿Se puede aplicar limpiamente el parche generado por el maniquí?
- Exactitud: ¿La integridad sencillo de la conservación del parche (todas las pruebas unitarias pasan)?
- Concierto: ¿El parche produce una prosperidad de tiempo de ejecución medible?
Las métricas no se agregan en una sola puntuación, lo que permite una evaluación más matizada de las compensaciones entre la corrección sintáctica y las ganancias de rendimiento.
Resultados experimentales
El punto de relato evalúa varios LLM de nivel superior en la configuración de Oracle y realista:
| Maniquí | Configuración | Concierto (%) |
|---|---|---|
| Claude-4-opus | Oráculo | 1.28 |
| GPT-4O | Oráculo | 0.60 |
| Gemini-2.5-pro | Oráculo | 1.48 |
| Claude-3.7 (sin agente) | Realista | 0.41 |
| Claude-3.7 (OpenHands) | Realista | 2.26 |
| Diestro (parche humano) | – | 10.85 |
En particular, incluso las configuraciones de LLM de mejor rendimiento están significativamente debajo del rendimiento a nivel humano. El método basado en agentes OpenHands, basado en Claude-3.7-Sonnet, supera a otras configuraciones en la configuración realista, pero aún se queda a espaldas de las optimizaciones hechas de expertos.
Observaciones esencia
- Marcos basados en agentes como OpenHands son más adecuados para la optimización compleja de varios pasos, superan las indicaciones del maniquí directo y los enfoques basados en la tubería como el sin agente.
- El rendimiento se degrada A medida que aumenta el número de funciones objetivo: los LLM luchan con alcances de optimización más amplios.
- LLMS exhiben escalabilidad limitada En escenarios de larga duración, donde los sistemas expertos continúan mostrando ganancias de rendimiento.
- Examen de parches Muestra el enfoque de LLM más en estructuras de código de bajo nivel (por ejemplo, importaciones, configuración del entorno), mientras que los expertos se dirigen a abstracciones semánticas de stop nivel para el ajuste del rendimiento.
Conclusión
SWE-Perf representa un paso fundamental para determinar y mejorar las capacidades de optimización del rendimiento de los LLM en flujos de trabajo de ingeniería de software realistas. Descubre una brecha de capacidad significativa entre los modelos existentes y los expertos humanos, que ofrece una almohadilla sólida para futuras investigaciones en el ajuste de rendimiento a escalera de repositorio. A medida que los LLM evolucionan, SWE-Perf puede servir como una sino del ártico que los folleto con destino a la prosperidad experiencia de software inventario para la producción a escalera.
Mira el Papel, Página de Github y Esquema. Todo el crédito por esta investigación va a los investigadores de este plan.
Oportunidad de patrocinio: Llegue a los desarrolladores de IA más influyentes en Estados Unidos y Europa. 1M+ lectores mensuales, 500k+ constructores comunitarios, infinitas posibilidades. (Explore el patrocinio)
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero fantasioso, ASIF se compromete a usar el potencial de la inteligencia sintético para el perfectamente social. Su esfuerzo más fresco es el impulso de una plataforma de medios de inteligencia sintético, MarktechPost, que se destaca por su cobertura profunda de noticiario de educación inevitable y de educación profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el notorio.