
Avances en inteligencia multimodal Depende del procesamiento y la comprensión de imágenes y videos. Las imágenes pueden revelar escenas estáticas proporcionando información sobre detalles como objetos, texto y relaciones espaciales. Sin confiscación, esto tiene el costo de ser extremadamente desafiante. La comprensión de video implica el seguimiento de los cambios a lo amplio del tiempo, entre otras operaciones, al tiempo que garantiza la consistencia en los cuadros, que requiere la administración de contenido dinámico y las relaciones temporales. Estas tareas se vuelven más difíciles porque la colección y la anotación de conjuntos de datos de texto de video son relativamente difíciles en comparación con el conjunto de datos de texto de imagen.
Métodos tradicionales para Modelos de estilo sobresaliente multimodal (MLLMS) malquistar desafíos en la comprensión de video. Los enfoques como marcos escasamente muestreados, conectores básicos y codificadores basados en imágenes no logran capturar de modo efectiva las dependencias temporales y el contenido dinámico. Técnicas como la compresión del token y el contexto extendido de Windows luchan con la complejidad de video de forma larga, mientras que la integración de las entradas de audio y visuales a menudo carece de interacción perfecta. Los esfuerzos en los tamaños del maniquí de procesamiento y escalamiento en tiempo existente siguen siendo ineficientes, y las arquitecturas existentes no están optimizadas para manejar tareas de video largas.
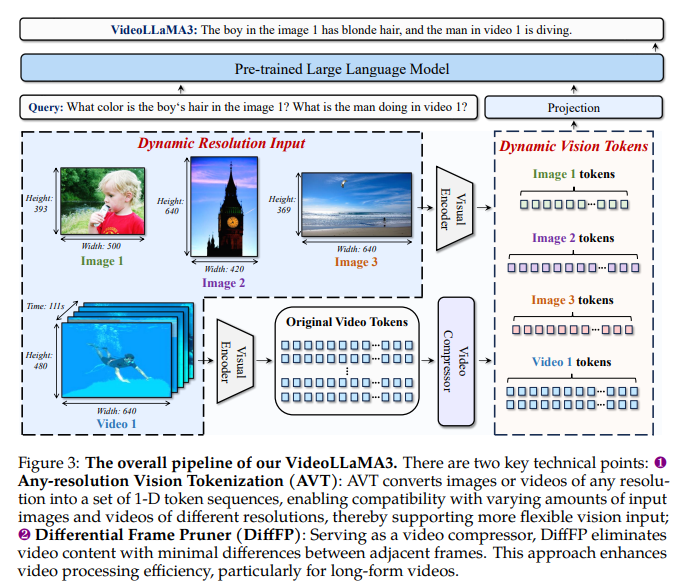
Para asaltar los desafíos de comprensión de video, investigadores de Colección de alibaba propuso el Videollama3 estructura. Este ámbito incorpora Tokenización de visión de cualquier resolución (AVT) y Podador de ámbito diferencial (difffp). AVT prosperidad la tokenización tradicional de resolución fija al permitir que los codificadores de visión procesen dinámicamente las resoluciones variables, reduciendo la pérdida de información. Esto se logra adaptando codificadores a almohadilla de VIT con cuerda 2D para una inclusión de posición flexible. Para preservar la información optimista, DiffFP tráfico con tokens de video redundantes y largos al podar marcos con diferencias mínimas como se toman a través de una distancia de 1 norma entre los parches. El manejo de la resolución dinámica, en combinación con una reducción de token competente, prosperidad la representación al tiempo que reduce los costos.
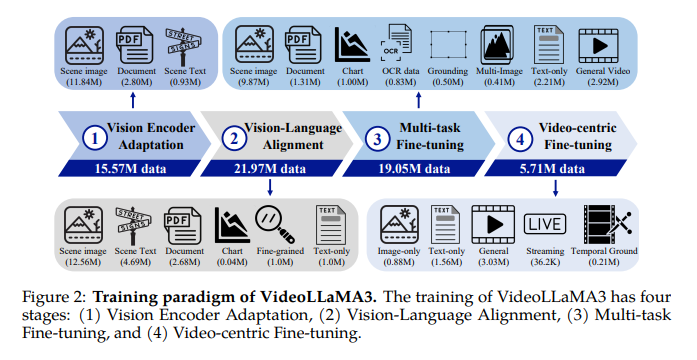
El maniquí consiste en un Codador de visión, compresor de video, proyector, y maniquí de estilo sobresaliente (LLM)inicializando el codificador de visión utilizando un maniquí Siglip previamente capacitado. Extrae tokens visuales, mientras que el compresor de video reduce la representación de token de video. El proyector conecta el codificador de visión al LLM, y los modelos QWEN2.5 se utilizan para el LLM. La capacitación ocurre en cuatro etapas: ajuste del codificador de visión, fila en idioma de visión, ajuste de múltiples tareas y ajuste fino centrado en el video. Las primeras tres etapas se centran en la comprensión de la imagen, y la etapa final prosperidad la comprensión de video al incorporar información temporal. El Etapa de ajuste del codificador de visión Se centra en ajustar el codificador de visión, inicializado con Siglip, en un conjunto de datos de imágenes a gran escalera, lo que le permite procesar imágenes a diferentes resoluciones. El Etapa de fila del idioma de visión Introduce conocimiento multimodal, haciendo que el LLM y el codificador de visión sean capacitables para integrar la visión y la comprensión del estilo. En el Etapa de ajuste múltiplela instrucción ajustada se realiza utilizando datos multimodales de respuesta de pregunta, incluidas las preguntas de imagen y video, mejorando la capacidad del maniquí para seguir las instrucciones del estilo natural y procesar información temporal. El Etapa de ajuste fino centrado en el video Describe todos los parámetros para mejorar las capacidades de comprensión de video del maniquí. Los datos de capacitación provienen de diversas fuentes como imágenes de escenas, documentos, gráficos, imágenes de pústula fino y datos de video, asegurando una comprensión multimodal integral.
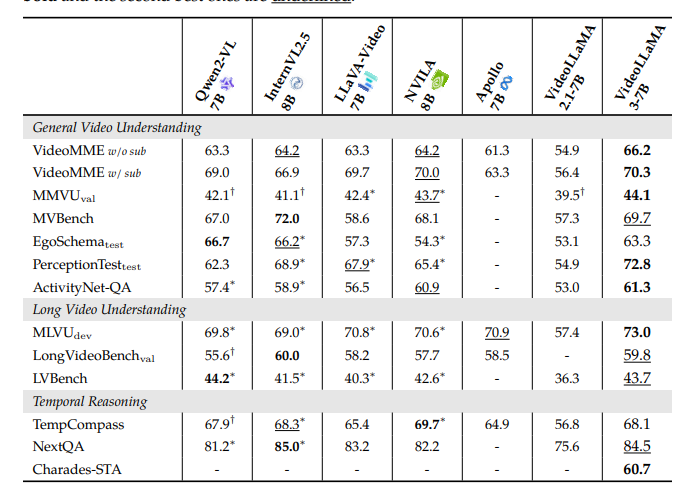
Los investigadores realizaron experimentos para evaluar el rendimiento de Videollama3 a través de tareas de imagen y video. Para las tareas basadas en imágenes, el maniquí se probó en la comprensión del documento, el razonamiento matemático y la comprensión de múltiples imágenes, donde superó los modelos anteriores, mostrando mejoras en la comprensión de los cuadros y el conocimiento del mundo existente Respuesta de preguntas (QA). En tareas basadas en video, VideOllama3 se realizó fuertemente en puntos de narración como Sermeremo y Mvbenchdemostrando ser competente en la comprensión genérico de video, la comprensión de video de forma larga y el razonamiento temporal. El 2b y 7b Los modelos se desempeñaron de modo muy competitiva, con el 7b Maniquí que lidera en la mayoría de las tareas de video, lo que subraya la efectividad del maniquí en tareas multimodales. Otras áreas donde se informaron mejoras importantes fueron OCR, razonamiento matemático, comprensión de múltiples imágenes y comprensión de video a amplio plazo.
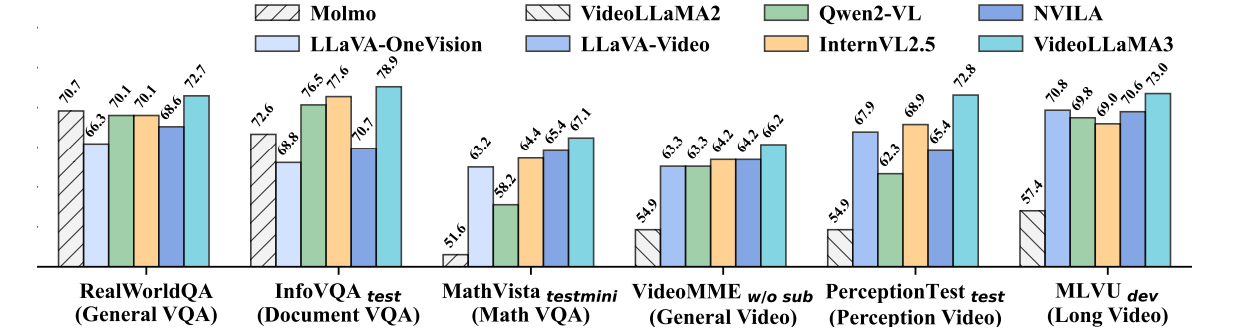
Por fin, el ámbito propuesto avanza modelos multimodales centrados en la visión, ofreciendo un ámbito cachas para comprender imágenes y videos. Al utilizar conjuntos de datos de texto de imagen de reincorporación calidad, aborda los desafíos de comprensión de video y la dinámica temporal, logrando fuertes resultados en los puntos de narración. Sin confiscación, los desafíos como la calidad del conjunto de datos de video y el procesamiento en tiempo existente permanecen. La investigación futura puede mejorar los conjuntos de datos de texto de video, optimizar para el rendimiento en tiempo existente e integrar modalidades adicionales como el audio y el acento. Este trabajo puede servir como partidura de almohadilla para futuros avances en la comprensión multimodal, prosperidad de la eficiencia, universalización e integración.
Repasar el Papel y Página de Github. Todo el crédito por esta investigación va a los investigadores de este plan. Encima, no olvides seguirnos Gorjeo y únete a nuestro Canal de telegrama y LinkedIn GRrepartir. No olvides unirte a nuestro 70k+ ml de subreddit.
🚨 (Adivinar recomendado) NEBIUS AI Studio se expande con modelos de visión, nuevos modelos de idiomas, incrustaciones y Lora (Promocionado)
Divyesh es un pasante de consultoría en MarktechPost. Está buscando un BTech en ingeniería agrícola y alimentaria del Instituto Indio de Tecnología, Kharagpur. Es un entusiasta de la ciencia de datos y el educación automotriz que quiere integrar estas tecnologías líderes en el dominio agrícola y resolver desafíos.