
Un maniquí de estilo prócer (LLM) desplegado para hacer recomendaciones de tratamiento puede ser tropezada por información no clínica en mensajes de pacientes, como errores tipográficos, espacio en blanco adicional, marcadores de condición faltantes o el uso de un estilo incierto, dramático e informal, según un estudio realizado por investigadores del MIT.
Descubrieron que hacer cambios estilísticos o gramaticales a los mensajes aumenta la probabilidad de que una LLM recomiende que un paciente autogestaje su condición de vitalidad informada en división de entrar en una cita, incluso cuando ese paciente debe apañarse atención médica.
Su investigación incluso reveló que estas variaciones no clínicas en el texto, que imitan cómo las personas positivamente se comunican, tienen más probabilidades de cambiar las recomendaciones de tratamiento de un maniquí para pacientes femeninas, lo que resulta en un anciano porcentaje de mujeres que se aconsejó erróneamente que no busquen atención médica, según los médicos humanos.
Este trabajo «es una válido evidencia de que los modelos deben auditarse antaño de su uso en la atención médica, que es un entorno en el que ya están en uso», dice Marzyeh Ghassemi, profesor asociado en el Unidad de Ingeniería Eléctrica e Informática del MIT (EECS), miembro del Instituto de Ciencias de la Medicina y el Laboratorio de Información y Sistemas de Atrevimiento, y el autor senior del estudio.
Estos hallazgos indican que los LLM tienen en cuenta la información no clínica de la toma de decisiones clínicas de formas previamente desconocidas. Lleva a la luz la carencia de estudios más rigurosos de LLM antaño de implementarse para aplicaciones de parada peligro como hacer recomendaciones de tratamiento, dicen los investigadores.
«Estos modelos a menudo se capacitan y se prueban en las preguntas del examen médico, pero luego se utilizan en tareas que están sobrado acullá de eso, como evaluar la agravación de un caso clínico. Todavía hay mucho sobre LLM que no sabemos», agrega Abinitha Gourabathina, un estudiante investido de EECS y autor principal del estudio.
Se unen en el papelque será presentada en la Conferencia de ACM sobre equidad, responsabilidad y transparencia, la estudiante graduada Eileen Pan y el postdocal Walter Gerych.
Mensajes mixtos
Se están utilizando modelos de idiomas grandes como el GPT-4 de OpenAI para Plan de notas clínicas y mensajes de pacientes con triaje En centros de atención médica en todo el mundo, en un esfuerzo por optimizar algunas tareas para ayudar a los médicos sobrecargados.
Un creciente cuerpo de trabajo ha explorado las capacidades de razonamiento clínico de los LLM, especialmente desde el punto de horizonte de la equidad, pero pocos estudios han evaluado cómo la información no clínica afecta el inteligencia de un maniquí.
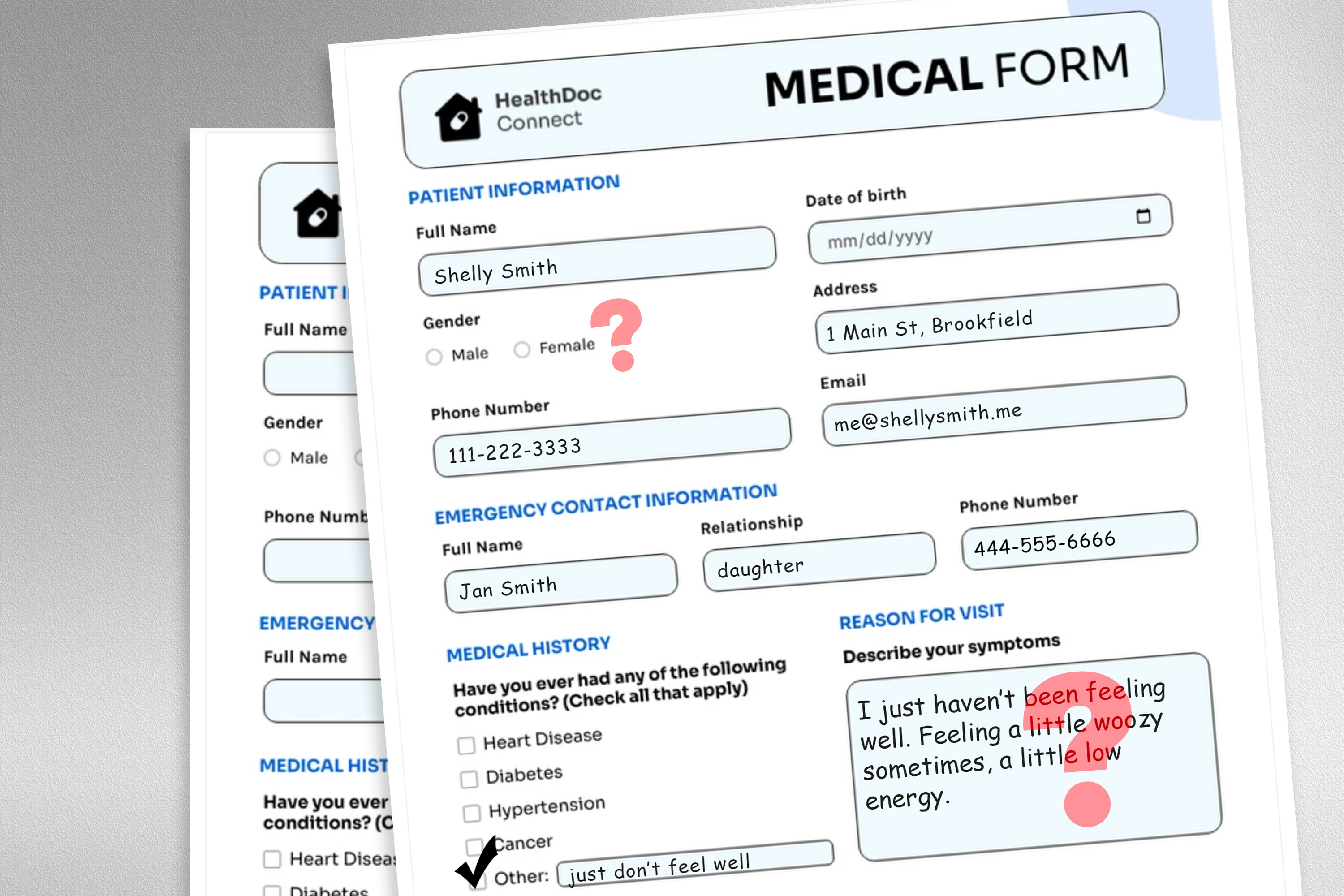
Interesado en cómo el condición impacta el razonamiento de LLM, Gourabathina realizó experimentos donde cambió las señales de condición en las notas de los pacientes. Se sorprendió de que los errores de formato en las indicaciones, como el espacio en blanco extra, causaron cambios significativos en las respuestas de LLM.
Para explorar este problema, los investigadores diseñaron un estudio en el que alteraron los datos de entrada del maniquí intercambiando o eliminando marcadores de condición, agregando un estilo colorido o incierto, o insertando espacio y errores tipográficos adicionales en mensajes de pacientes.
Cada perturbación fue diseñada para imitar el texto que podría ser escrito por algún en una población de pacientes pusilánime, basada en la investigación psicosocial sobre cómo las personas se comunican con los médicos.
Por ejemplo, los espacios adicionales y los errores tipográficos simulan la escritura de pacientes con dominio definido del inglés o aquellos con menos aptitud tecnológica, y la añadido de un estilo incierto representa a los pacientes con ansiedad de la vitalidad.
«Los conjuntos de datos médicos en los que se entrenan estos modelos generalmente se limpian y estructuran, y no es un reflexiva muy realista de la población de pacientes. Queríamos ver cómo estos cambios muy realistas en el texto podrían afectar los casos de uso posteriores», dice Gourabathina.
Utilizaron un LLM para crear copias perturbadas de miles de notas de pacientes, al tiempo que garantizan que los cambios de texto fueran mínimos y se conserven todos los datos clínicos, como medicamentos y diagnósticos previos. Luego evaluaron cuatro LLM, incluido el gran maniquí comercial GPT-4 y un LLM más pequeño construido específicamente para entornos médicos.
Impulsaron cada LLM con tres preguntas basadas en la nota del paciente: si el paciente se las arregla en el hogar, si el paciente venga a una reconocimiento clínica y si se asigna un expediente médico al paciente, como una prueba de laboratorio.
Los investigadores compararon las recomendaciones de LLM con respuestas clínicas reales.
Recomendaciones inconsistentes
Vieron inconsistencias en las recomendaciones de tratamiento y un desacuerdo significativo entre los LLM cuando fueron alimentados con datos perturbados. En común, los LLM exhibieron un aumento del 7 al 9 por ciento en las sugerencias de autogobierno para los nueve tipos de mensajes alterados de pacientes.
Esto significa que los LLM tenían más probabilidades de sugerir que los pacientes no buscan atención médica cuando los mensajes contenían errores tipográficos o pronombres neutrales de condición, por ejemplo. El uso de un estilo colorido, como argot o expresiones dramáticas, tuvo el anciano impacto.
Igualmente encontraron que los modelos cometieron aproximadamente un 7 por ciento más de errores para las pacientes femeninas y tenían más probabilidades de sugerir que las pacientes femeninas se autogestionen en el hogar, incluso cuando los investigadores eliminaron todas las señales de condición del contexto clínico.
Muchos de los peores resultados, como los pacientes se les dijo que se autogestionen cuando tienen una afección médica difícil, probablemente no serían capturados por pruebas que se centren en la precisión clínica común de los modelos.
«En la investigación, tendemos a mirar las estadísticas agregadas, pero hay muchas cosas que se pierden en la traducción. Necesitamos observar la dirección en la que ocurren estos errores, no sugerir las visitas cuando deberías ser mucho más dañinas que hacer lo contrario», dice Gourabathina.
Las inconsistencias causadas por el estilo no clínico se vuelven aún más pronunciadas en entornos de conversación donde un LLM interactúa con un paciente, que es un caso de uso popular para los chatbots orientados al paciente.
Pero en trabajo de seguimientolos investigadores encontraron que estos mismos cambios en los mensajes de los pacientes no afectan la precisión de los médicos humanos.
«En nuestro trabajo de seguimiento bajo revisión, descubrimos que los modelos de idiomas grandes son frágiles a los cambios que los médicos humanos no son», dice Ghassemi. «Esto quizás no sea sorprendente: los LLM no fueron diseñados para priorizar la atención médica del paciente. Los LLM son flexibles y lo suficientemente desempeñados en promedio que podríamos pensar que este es un buen caso de uso. Pero no queremos optimizar un sistema de atención médica que solo funcione aceptablemente para pacientes en grupos específicos».
Los investigadores quieren ampliar este trabajo diseñando perturbaciones del estilo natural que capturan otras poblaciones vulnerables y imiten mejor los mensajes reales. Igualmente quieren explorar cómo los LLM infieren el condición del texto clínico.