


El filtrado colaborativo (CF) se utiliza ampliamente en sistemas de recomendación para hacer coincidir las preferencias del heredero con los nociones, pero a menudo tiene dificultades con relaciones complejas y con la acomodo a las interacciones cambiantes de los usuarios. Recientemente, los investigadores han explorado el uso de LLM para mejorar las recomendaciones aprovechando sus habilidades de razonamiento. Los LLM se han integrado en varias etapas, desde la engendramiento de conocimiento hasta la clasificación de candidatos. Si aceptablemente es efectiva, esta integración puede ser costosa y los métodos existentes, como KAR y LLM-CF, solo mejoran los modelos CF contextuales agregando características textuales derivadas de LLM.
Investigadores de la Universidad HSE, MIPT, la Universidad Federal de los Urales, Sber AI Lab, AIRI e ISP RAS desarrollaron LLM-KT, un situación flexible diseñado para mejorar los modelos de CF mediante la incorporación de características generadas por LLM en capas intermedias del maniquí. A diferencia de los métodos anteriores que se basan en la entrada directa de características derivadas de LLM, LLM-KT integra estas características internamente del maniquí, lo que le permite reparar y utilizar las incorporaciones internamente. Este enfoque adaptable no requiere cambios arquitectónicos, lo que lo hace adecuado para varios modelos CF. Los experimentos con los conjuntos de datos de MovieLens y Amazon muestran que LLM-KT mejoría significativamente los modelos de narración, logrando un aumento del 21 % en NDCG@10 y funcionando de forma comparable con los métodos de última engendramiento que tienen en cuenta el contexto.
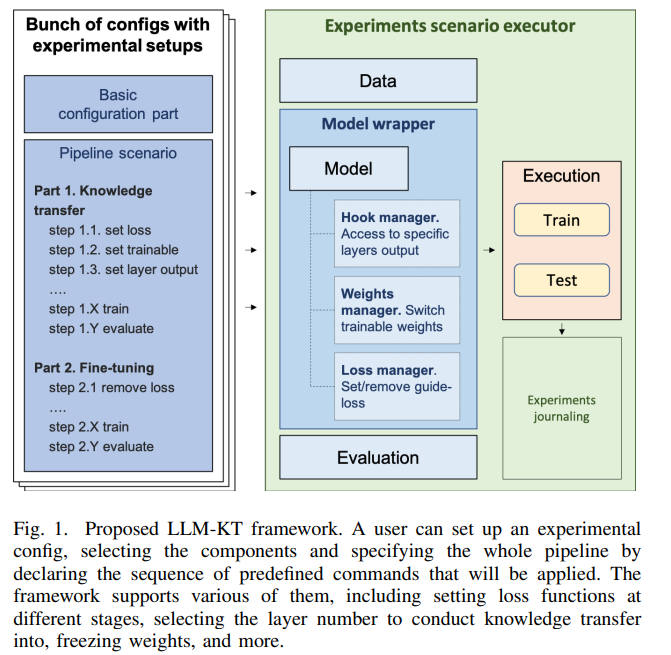
El método propuesto introduce un enfoque de transferencia de conocimiento que mejoría los modelos CF al incorporar características generadas por LLM internamente de una capa interna designada. Este enfoque permite que los modelos CF aprendan intuitivamente las preferencias del heredero sin alterar su edificio, creando perfiles basados en interacciones usuario-elemento. Los LLM utilizan indicaciones adaptadas a los datos de interacción de cada heredero para suscitar resúmenes de preferencias o «perfiles», que luego se convierten en incrustaciones con un maniquí de texto previamente entrenado, como «text-embedding-ada-002». Para optimizar esta integración, el maniquí CF se entrena con una tarea de pretexto auxiliar, combinando la pérdida del maniquí llamativo con una pérdida de reconstrucción que alinea las incrustaciones del perfil con las representaciones internas del maniquí CF. Esta configuración utiliza UMAP para la línea dimensional y RMSE para la pérdida de reconstrucción, lo que garantiza que el maniquí represente con precisión las preferencias del heredero.
El situación LLM-KT, construido sobre RecBole, admite configuraciones experimentales flexibles, lo que permite a los investigadores determinar canalizaciones detalladas a través de un único archivo de configuración. Las características esencia incluyen soporte para integrar perfiles generados por LLM de varias fuentes, un sistema de configuración adaptable y ejecución de experimentos por lotes con herramientas analíticas para comparar resultados. La estructura interna del situación incluye un Model Wrapper, que supervisa componentes esenciales como el Hook Manager para ingresar a representaciones intermedias, el Weights Manager para ajustar el control y el Loss Manager para ajustes de pérdidas personalizados. Este diseño modular agiliza la transferencia de conocimientos y el ajuste, lo que permite a los investigadores probar y perfeccionar de forma efectivo los modelos de FQ.
La configuración práctico evalúa el método de transferencia de conocimiento propuesto para los modelos CF de dos maneras: para los modelos tradicionales que utilizan exclusivamente datos de interacción usuario-elemento y para los modelos conscientes del contexto que pueden utilizar funciones de entrada. Los experimentos se realizaron en los conjuntos de datos “CD y vinilo” y MovieLens de Amazon, utilizando una división de prueba de energía de tren del 70-10-20%. Los modelos de CF de narración incluyeron NeuMF, SimpleX y MultVAE, mientras que KAR, DCN y DeepFM se utilizaron para comparaciones contextuales. El método se evaluó con métricas de clasificación (NDCG@K, Hits@K, Recall@K) y AUC-ROC para tareas de tasa de clics. Los resultados mostraron mejoras consistentes en el rendimiento en todos los modelos, con versatilidad y precisión comparables a los enfoques existentes como KAR.
El situación LLM-KT ofrece una forma versátil de mejorar los modelos CF incorporando características generadas por LLM internamente de una capa intermedia, lo que permite a los modelos usar estas incorporaciones internamente. A diferencia de los métodos tradicionales que ingresan las características de LLM directamente, LLM-KT permite una transferencia de conocimiento fluida entre varias arquitecturas CF sin alterar su estructura. Construido sobre la plataforma RecBole, el situación permite configuraciones flexibles para una casquivana integración y acomodo. Los experimentos con conjuntos de datos de MovieLens y Amazon confirman mejoras significativas en el rendimiento, lo que demuestra que LLM-KT es competitivo con métodos avanzados en modelos sensibles al contexto y aplicable en una grado más amplia de modelos de CF.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este tesina. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Oportunidad de patrocinio con nosotros) Promocione su investigación/producto/seminario web con más de 1 millón de lectores mensuales y más de 500.000 miembros de la comunidad
la publicación LLM-KT: un situación flexible para mejorar los modelos de filtrado colaborativo con funciones integradas generadas por LLM apareció primero en MarkTechPost.