
En los últimos primaveras, la ingeniería rápida ha sido el apretón de manos secreto del mundo de la IA. La redacción correcta podría hacer que un maniquí suene poético, divertido o revelador; el erróneo lo volvió plano y robótico. Pero un nuevo artículo dirigido por Stanford sostiene que la veterano parte de este “arte” ha estado compensando poco más profundo, un sesgo oculto en la forma en que entrenamos estos sistemas.
Su afirmación es simple: los modelos nunca fueron aburridos. Fueron entrenados para desempeñarse de esa guisa.
Y la opción propuesta, llamamiento Muestreo verbalizadopodría no solo cambiar la forma en que incitamos a los modelos; podría reescribir nuestra forma de pensar sobre la alineamiento y la creatividad en la IA.
El problema central: la alineamiento hizo que la IA fuera predecible
Para comprender el avance, comience con un prueba simple. Pregúntale a un maniquí de IA, “c”. Hazlo cinco veces. Casi siempre obtendrás la misma respuesta:

Esto no es holgazanería; es colapso del modoun estrechamiento de la distribución de salida del maniquí posteriormente del entrenamiento de alineamiento. En lado de explorar todas las respuestas válidas que podría producir, el maniquí gravita cerca de la más segura y típica.
El equipo de Stanford rastreó esto hasta sesgo de tipicidad en los datos de feedback humana utilizados durante el educación por refuerzo. Cuando los anotadores juzgan las respuestas del maniquí, siempre prefieren texto que les resulte llano. Con el tiempo, los modelos de remuneración entrenados en esa preferencia aprenden a galardonar. normalidad en lado de novedad.
Matemáticamente, este sesgo añade un “peso de tipicidad” (α) a la función de remuneración, amplificando lo que parezca estadísticamente más promedio. Es una lenta restricción de la creatividad, la razón por la que la mayoría de los modelos alineados suenan parecidos.
El viraje: la creatividad nunca se perdió
Aquí está el truco: la multiplicidad no ha desaparecido. Está enterrado.
Cuando solicita una única respuesta, está obligando al maniquí a nominar la finalización más probable. Pero si se lo pides verbalizar múltiples respuestas yuxtapuesto con sus probabilidadesde repente abre su distribución interna, la escala de ideas que verdaderamente «conoce».
Eso es Muestreo verbalizado (VS) en actividad.
En lado de:
Cuéntame un chiste sobre el café.
Preguntas:
Genera cinco chistes sobre el café con sus probabilidades
Este pequeño cambio desbloquea la multiplicidad que el entrenamiento de alineamiento había comprimido. No está reentrenando el maniquí, cambiando la temperatura ni pirateando los parámetros de muestreo. Simplemente estás incitando de guisa diferente: pidiendo al maniquí que muestre su incertidumbre en lado de ocultarla.
El aviso del café: prueba en actividad
Para demostrarlo, los investigadores ejecutaron el mismo mensaje de broma sobre el café utilizando mensajes tradicionales y muestreo verbalizado.
Incitación directa
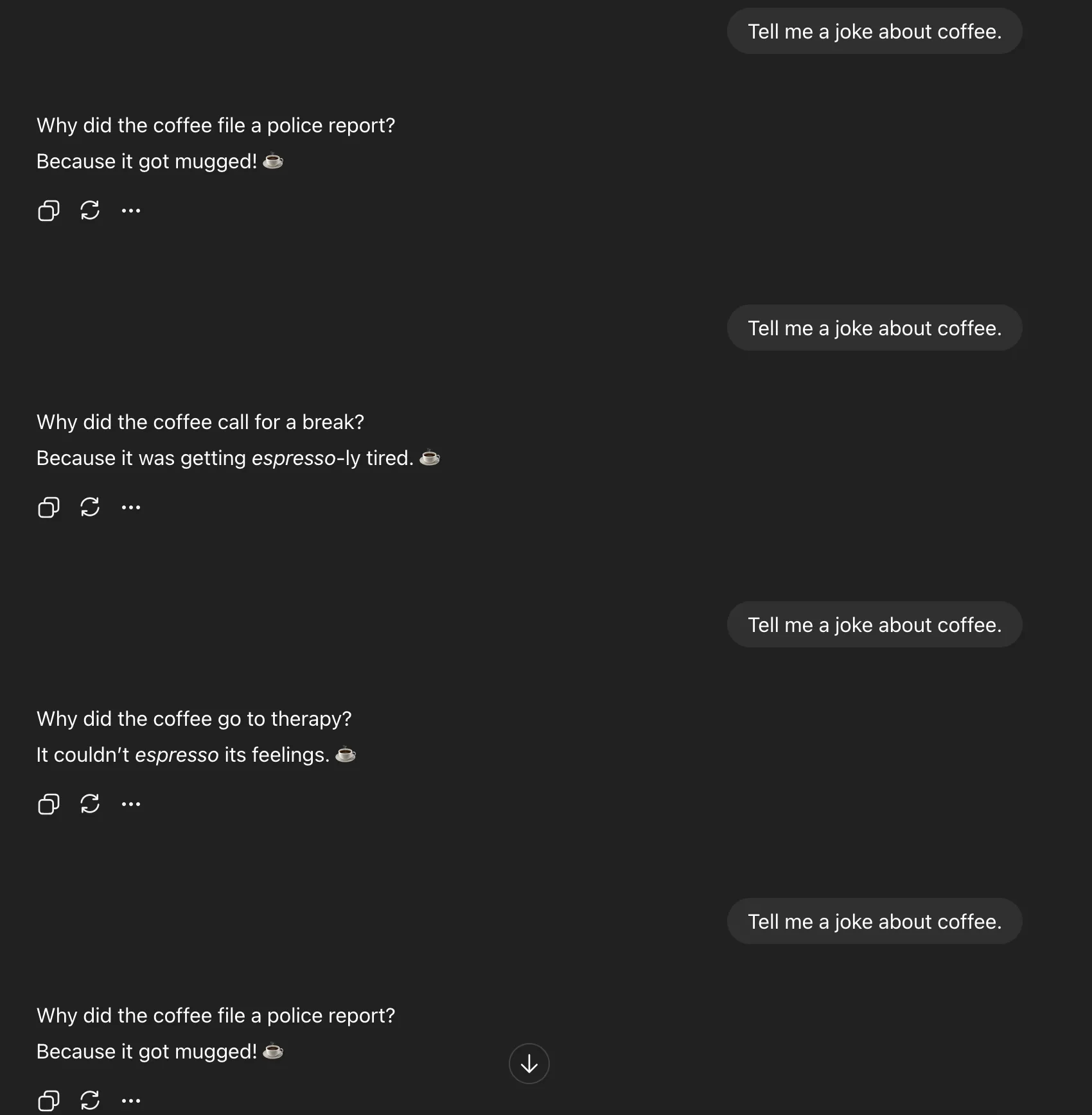
Muestreo verbalizado
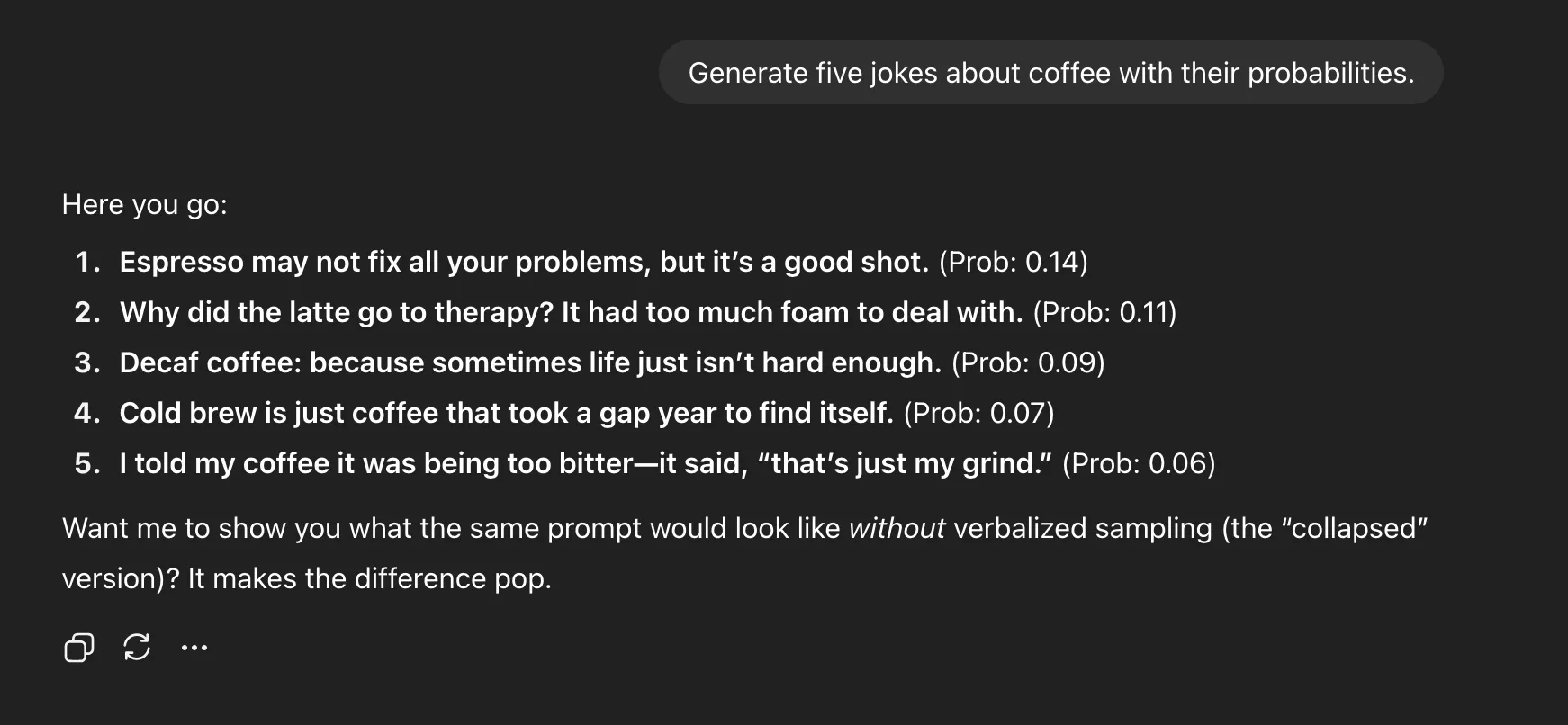
Por qué funciona
Durante la coexistentes, un maniquí de estilo muestrea internamente tokens de una distribución de probabilidad, pero generalmente solo vemos la mejor opción. Cuando le pide que genere varios candidatos con probabilidades adjuntas, le está haciendo razonar explícitamente sobre su propia incertidumbre.
Esta “autoverbalización” expone la multiplicidad subyacente del maniquí. En lado de colapsar en un único modo de incorporación probabilidad, le muestra varios modos plausibles.
En la maña, eso significa «Cuéntame un chiste» produce un encaje de palabras sobre un atraco, mientras que «Genera cinco chistes con probabilidades» produce juegos de palabras sobre espresso, chistes de terapia, líneas de cerveza fría y más. No es sólo variedad, es interpretabilidad. Puedes ver cuál es el maniquí. piensa podría funcionar.
Los datos y las ganancias
A través de múltiples puntos de remisión, escritura creativa, simulación de diálogo y control de calidad campechano, los resultados fueron consistentes:
- Aumento de 1,6 a 2,1 veces en la multiplicidad para tareas de escritura creativa
- 66,8% de recuperación de la multiplicidad previa a la alineamiento
- No hay caída en la precisión o seguridad de los hechos (tasas de rechazo superiores al 97%)
Los modelos más grandes se beneficiaron aún más. Los sistemas de clase GPT-4 mostraron el doble de mejoría en la multiplicidad en comparación con los más pequeños, lo que sugiere que los modelos grandes tienen una profunda creatividad velado esperando ser accedida.
El sesgo detrás de todo
Para confirmar que el sesgo de tipicidad verdaderamente impulsa el colapso modal, los investigadores analizaron casi siete mil pares de respuestas del conjunto de datos HelpSteer. Los anotadores humanos prefirieron respuestas «típicas» entre un 17% y un 19% más a menudo, incluso cuando ambas eran igualmente correctas.
Modelaron esto como:
r(x, y) = r_true(x, y) + α log π_ref(y | x)
Ese término α es el peso del sesgo de tipicidad. A medida que α aumenta, la distribución del maniquí se agudiza, empujándolo cerca de el centro. Con el tiempo, esto hace que las respuestas sean seguras, predecibles y repetitivas.
¿Qué significa para la ingeniería rápida??
Entonces, ¿está muerta la ingeniería rápida? No exactamente. Pero está evolucionando.
El muestreo verbalizado no elimina la carencia de dar indicaciones reflexivas: cambia la apariencia de las indicaciones hábiles. El nuevo encaje no se alcahuetería de engañar a un maniquí para que sea creativo; se alcahuetería de diseñar meta-indicaciones que exponen su espacio de probabilidad completo.
Incluso puedes tratarlo como un «esfera de creatividad». Establezca un inicio de probabilidad para controlar qué tan salvajes o seguras desea que sean las respuestas. Bájelo para obtener más sorpresa, súbalo para veterano estabilidad.
Las verdaderas implicaciones
El veterano cambio aquí no se alcahuetería de chistes o historias. Se alcahuetería de replantear la alineamiento misma.
Durante primaveras, hemos aceptado que la alineamiento hace que los modelos sean más seguros pero más suaves. Esta investigación sugiere lo contrario: la alineamiento los hizo demasiado educado, no roto. Al incitar de guisa diferente, podemos recuperar la creatividad sin tocar las mancuerna del maniquí.
Esto tiene consecuencias mucho más allá de la escritura creativa: desde simulaciones sociales más realistas hasta datos sintéticos más ricos para el entrenamiento de modelos. Insinúa un nuevo tipo de sistema de inteligencia fabricado: uno que puede hacer una introspección sobre su propia incertidumbre y ofrecer múltiples respuestas plausibles en lado de pretender que solo hay una.
Las advertencias
No todo el mundo está creyendo las exageraciones. Los críticos señalan que algunos modelos pueden delirar puntuaciones de probabilidad en lado de reverberar probabilidades verdaderas. Otros argumentan que esto no soluciona el convencionalismo humano subyacente, sino que simplemente lo evita.
Y si perfectamente los resultados parecen sólidos en pruebas controladas, la implementación en el mundo positivo implica compensaciones de costo, latencia e interpretabilidad. Como lo expresó secamente un investigador sobre X: «Si funcionara perfectamente, OpenAI ya lo estaría haciendo».
Aún así, es difícil no pasmar la elegancia. Sin reentrenamiento, sin datos nuevos, solo una instrucción revisada:
Genera cinco respuestas con sus probabilidades.
Conclusión
La aviso del trabajo de Stanford es veterano que cualquier técnica individual. Los modelos que hemos construido nunca carecieron de imaginación; estaban demasiado alineados, entrenados para suprimir la multiplicidad que los hacía poderosos.
El muestreo verbalizado no los reescribe; simplemente les devuelve las llaves.
Si el entrenamiento previo construyó una vasta biblioteca interna, la alineamiento cerró la mayoría de sus puertas. VS es como empezamos a pedir ver las cinco versiones de la verdad.
La ingeniería rápida no está muerta. Finalmente se está convirtiendo en una ciencia.
Preguntas frecuentes
A. El muestreo verbalizado es un método de incitación que pide a los modelos de IA que generen múltiples respuestas con sus probabilidades, revelando su multiplicidad interna sin reentrenamiento ni ajustes de parámetros.
A. Correcto a sesgo de tipicidad En los datos de feedback humana, los modelos aprenden a ayudar respuestas seguras y familiares, lo que lleva al colapso del modo y a la pérdida de variedad creativa.
A. No. Lo redefine. La nueva diplomacia radica en crear metaindicaciones que expongan las distribuciones y controlen la creatividad, en lado de afinar el fraseo de una sola vez.
Me especializo en revisar y perfeccionar investigaciones impulsadas por IA, documentación técnica y contenido relacionado con tecnologías de IA emergentes. Mi experiencia alpargata el entrenamiento de modelos de IA, el disección de datos y la recuperación de información, lo que me permite crear contenido técnicamente preciso y accesible.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.