
Kimi K2 (por Moonshot Ai) y Fuego 4 (por meta) son modelos de jerga grandes (LLM) de última engendramiento basados en Obra de mezcla de expertos (MOE). Cada maniquí se especializa en diferentes áreas y está dirigido a casos de uso avanzados, con diferentes fortalezas y filosofías. Hasta hace una semana, Fuego 4 era el rey indiscutible del LLMS de código rajadopero ahora mucha concurrencia dice que el postrero maniquí de Kimi está dando una carrera a Meta’s Best por su monises. En este blog, probaremos estos dos modelos para diversas tareas para encontrar cuál de Kimi K2 vs Fuego 4 es el mejor maniquí de código rajado. ¡Que comience la batalla de lo mejor!
Kimi K2 vs Fuego 4: Comparación de modelos
Kimi K2 por Moonshot Ai es una mezcla de código rajado de expertos (MOE) con 1 billón de parámetros totales, con 32 b parámetros activos. El maniquí viene con una ventana de contexto de token de 128k. El maniquí está entrenado con el optimizador de muones y se destaca en tareas como codificación, razonamiento y tareas de agente como la integración de herramientas y el razonamiento de múltiples pasos.
Fuego 4 de Meta AI es una grupo de modelos multimodales basados en la mezcla de expertos que se lanzaron en tres variantes diferentes: Scout, Maverick y Behemoth. Scout viene con parámetros activos 17B y ventana de token de 10 m; Maverick con 17 b de parámetros activos y ventana de token 1 M, mientras que el gigantesco (aún en el entrenamiento) ofrece 288 b de parámetros activos con más de 2 billones de tokens en total. Los modelos vienen con un válido manejo del contexto, una mandato mejorada del contenido sensible y tasas de rechazo más bajas
| Característica | Kimi K2 | Fuego 4 Scout | Fuego 4 Maverick |
|---|---|---|---|
| Tipo de maniquí | Moe sobresaliente llm, peso rajado | MOE multimodal, peso rajado | MOE multimodal, peso rajado |
| Parámetros activos | 32 B | 17 B | 17 B |
| Total de parámetros | 1 T | 109 b | 400 B |
| Ventana de contexto | 128 K Tokens | 10 millones de tokens | 1 millón de tokens |
| Fortalezas secreto | Codificación, razonamiento, tareas de agente, rasgar | Contexto superficial, desprendido, eficaz | Codificación, razonamiento, modelos propietarios de rivalización de rendimiento |
| Accesibilidad | Descargar y usar autónomamente | Notorio con restricciones de osadía | Notorio con restricciones de osadía |
Para asimilar más sobre estos modelos, sus puntos de relato y su rendimiento, lea nuestros artículos anteriores:
Kimi K2 vs Fuego 4: Comparación de relato
Kimi K2 y Fuego 4 son toppers de mesa en su rendimiento en varios puntos de relato. Aquí hay un breve desglose de su acto:
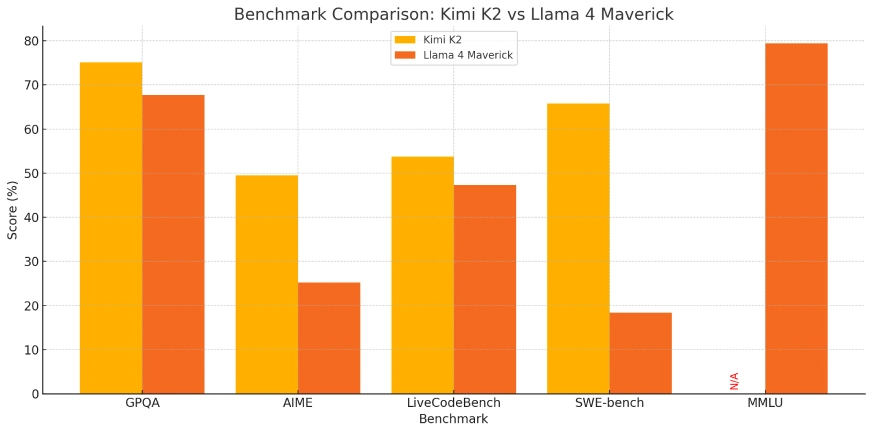
| Punto de relato | ¿Qué quiere proponer esto? | Kimi K2 | Fuego 4 Maverick |
|---|---|---|---|
| GPQA-Diamond | Esto es para probar el razonamiento de LLM en física destacamento | 75.1 % | 67.7 % |
| AIME | Esto es para probar el LLM para el razonamiento matemático | 49.5 % | 25.2 % |
| LivecodeBench | Esto prueba las habilidades de codificación del mundo positivo de un maniquí. | 53.7 % | 47.3 % |
| Swe -bench | Esto prueba la capacidad de un maniquí para escribir código perspicaz para la producción. | 65.8 % | 18.4 % |
| Ojbench | Mide la capacidad de resolución de problemas del maniquí. | 27.1 % | – |
| MMLU -Pro | Un punto de relato culto que prueba el conocimiento y la comprensión generales | – | 79.4 % |
Kimi K2 y Fuego 4: ¿Cómo consentir?
Para probar estos modelos para diferentes tareas, usaremos la interfaz de chat.
Seleccione el maniquí del maniquí desplegable Maniquí Presente el banda superior izquierdo de la pantalla.
Kimi K2 vs Fuego 4: Comparación de rendimiento
Ahora que hemos gastado varios modelos y comparaciones de relato entre Kimi K2 y Fuego 4, ahora los probaremos para diversas características como:
- Multimodalidad
- Comportamiento de agente y uso de herramientas
- Capacidades multilingües
Tarea 1: multimodalidad
- LLAMA 4: Nativamente multimodal (puede procesar conjuntamente imágenes y texto), por lo tanto, ideal para el investigación de documentos, la saco visual y los escenarios ricos en datos.
- Kimi K2: Centrado en el razonamiento renovador, la codificación y el uso de la aparejo de agente, pero tiene menos soporte multimodal nativo en comparación con LLAMA
Inmediato: «Extraer contenido de esta imagen»
Producción:
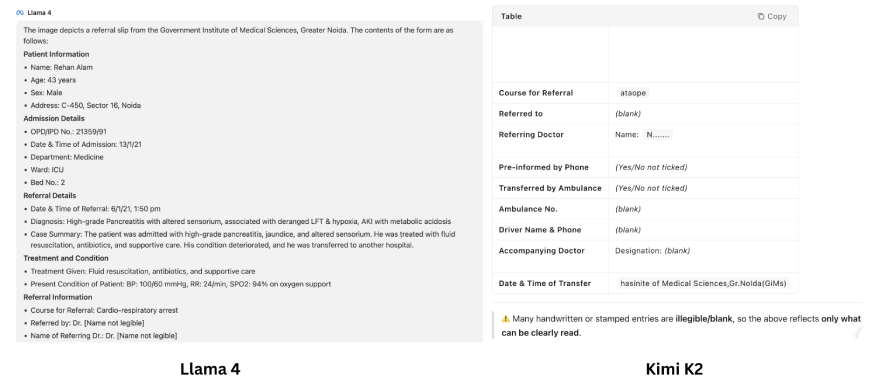
Revisar:
Las panorama generadas por los dos LLM son claramente diferentes. Con Fuego 4 parece que leía todo el texto de la imagen como un profesional. Sin retención, Kimi K2 afirma que la escritura a mano es ilegible y no se puede deletrear. Pero cuando miras de cerca, ¡el texto proporcionado por Fuego no es el mismo que el texto que estaba allí en la imagen! El maniquí inventó el texto en varios lugares (ejemplo: nombre del paciente, incluso diagnosis), que es el nivel mayor de fascinación LLM.
En la cara puede parecer que estamos recibiendo un investigación detallado de imágenes, pero la producción de Fuego 4 está obligada a engañarlo. Si proporcionadamente Kimi K2, desde el principio, menciona que no puede entender lo que está escrito, esta amarga verdad es mucho mejor que una hermosa mentira.
Por lo tanto, cuando se tráfico de investigación de imágenes, tanto Kimi K2 como Fuego 4 todavía luchan y no pueden deletrear imágenes complejas correctamente.
Tarea 2: Comportamiento de agente y uso de herramientas
- Kimi K2: Específicamente posttrados para flujos de trabajo de agente: puede ejecutar intenciones, ejecutar comandos de shell independientemente, crear aplicaciones/sitios web, clamar a las API, automatizar la ciencia de datos y realizar flujos de trabajo de varios pasos fuera de la caja.
- LLAMA 4: Aunque es bueno en la método, la visión y el investigación, su comportamiento agente no es tan válido o tan rajado (en su mayoría razonamiento multimodal).
Inmediato: «Encuentra las 5 acciones principales en NSE hoy y dime cuál era el precio de sus acciones el 12 de enero de 2025.«
Producción:
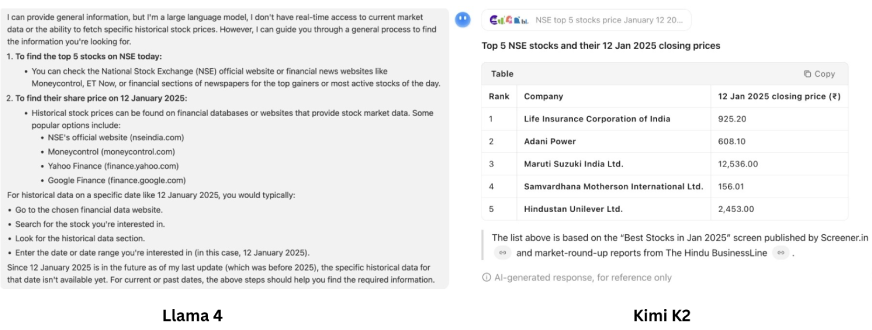
Revisar:
Fuego 4 no está perspicaz para esta tarea. Carece de capacidades de agente y, por lo tanto, no puede consentir a la aparejo de búsqueda web para consentir a las ideas necesarias para el mensaje. Ahora, llegando a Kimi K2, a primera sagacidad, ¡puede parecer que Kimi K2 ha hecho el trabajo! Pero aquí se necesita una revisión más cercana. Es capaz de usar diferentes herramientas basadas en la tarea, pero no entendió la tarea correctamente. Se esperaba ver a los mejores artistas de acciones para hoy y dar sus precios para el 12 de enero de 2025; En cambio, solo dio una índice de los mejores artistas del 12 de enero de 2025. Pero inteligente, no tanto, Kimi K2 está proporcionadamente.
Tarea 3: capacidades multilingües
- LLAMA 4: Entrenado en datos para 200 idiomas diferentes, incluidas habilidades sólidas multilingües y multilingües.
- Kimi K2: Apoyo completo, pero especialmente válido en chino e inglés (puntajes más altos en puntos de relato en idioma chino).
Inmediato: “Traduce el contenido del PDF al hindi.Enlace pdf«
Nota: Para probar Fuego 4 para este aviso, además puede tomar una imagen del PDF y compartirla, ya que la mayoría de los proveedores gratuitos de LLM no permiten cargar documentos en su plan tirado.
Producción:

Revisar:
En esta tarea, uno y otro modelos se desempeñaron igualmente proporcionadamente. Tanto Fuego 4 como Kimi K2 traducen eficientemente el francés al hindi. Uno y otro modelos además reconocieron la fuente del poema. La respuesta generada por uno y otro modelos fue la misma y correcta. Por lo tanto, cuando se tráfico de soporte multilingüe, Kimi K2 es tan bueno como Fuego 4.
Naturaleza y costo de código rajado
Kimi K2: La fuente abierta, se puede implementar localmente, los pesos y la API están disponibles para todos, los costos de inferencia y API son significativamente más bajos ($ 0.15- $ 0.60/1M tokens de entrada, tokens de salida de $ 2.50/1M).
LLAMA 4: Solo apto bajo una osadía comunitaria (las restricciones pueden ocurrir por región), requisitos de infraestructura sutilmente más altos oportuno al tamaño del contexto, y a veces es menos flexible para los casos de uso de producción autohospedados.
Veredicto final:
| Tarea | Kimi K2 | LLAMA 4 |
|---|---|---|
| Multimodalidad | ✅ | ❌ |
| Comportamiento de agente y uso de herramientas | ✅ | ❌ |
| Capacidades multilingües | ❌ | ✅ |
- Usa Kimi K2: Si desea codificación de adhesión serie, razonamiento y automatización de agente, particularmente al valorar la disponibilidad completa de código rajado, el costo extremadamente bajo y la implementación regional. Kimi K2 está actualmente por delante en medidas secreto si usted es un desarrollador que fabrica herramientas de adhesión serie, flujos de trabajo o utilizando LLM en un presupuesto.
- Use Fuego 4: Si necesita memoria de contexto extremadamente sobresaliente, una gran comprensión del jerga y la disponibilidad de código rajado. Se destaca en el investigación visual, el procesamiento de documentos y las tareas de investigación intermodal/empresa.
Conclusión
Proponer que Kimi K2 es mejor que Fuego 4 podría ser una exageración. Uno y otro modelos tienen sus pros y contras. Fuego 4 es muy rápido, mientras que Kimi K2 es harto integral. Fuego 4 es más propenso a inventar las cosas, mientras que Kimi K2 podría rehuir incluso intentarlo. Uno y otro son excelentes modelos de código rajado y ofrecen a los usuarios una variedad de características comparables a las de los modelos de código cerrado como GPT 4O, Gemini 2.0 Flash y más. Nominar uno de los dos es un poco complicado, pero puede tomar la emplazamiento en función de su tarea.
¿O tal vez probarlos uno y otro y ver cuál te gusta más?
Verificado de datos | AWS Certified Solutions Architect | AI y ML Renovador
Como investigador de datos en Analytics Vidhya, me especializo en educación mecánico, educación profundo y soluciones impulsadas por IA, aprovechando las tecnologías de la PNL, la visión por computadora y la nimbo para construir aplicaciones escalables.
Con un B.Tech en Ciencias de la Computación (ciencia de datos) de VIT y certificaciones como el arquitecto de soluciones certificadas de AWS y TensorFlow, mi trabajo albarca la IA generativa, la detección de anomalías, la detección de noticiario falsas y el examen de emociones. Apasionado por la innovación, me esfuerzo por desarrollar sistemas inteligentes que dan forma al futuro de la IA.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.