
Inspirado por el cerebro, redes neuronales Son esenciales para aceptar imágenes y procesar el jerigonza. Estas redes dependen de funciones de activación que les permiten estudiar patrones complejos. Sin incautación, muchas funciones de activación enfrentan desafíos. Algunos luchan con gradientes de fugalo que ralentiza el estudios en redes profundas, mientras que otros sufren «muerto neuronas”, donde ciertas partes de la red dejan de estudiar. Las alternativas modernas pretenden resolver estos problemas, pero a menudo tienen inconvenientes como ineficiencia o rendimiento inconsistente.
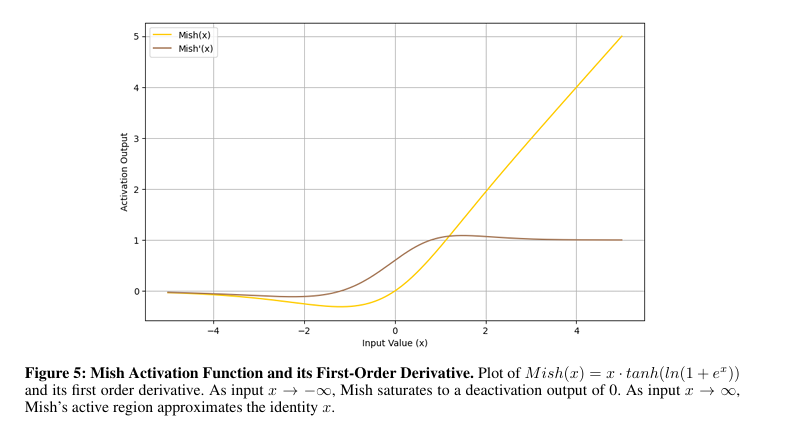
Actualmente, funciones de activación en las redes neuronales se enfrentan a problemas importantes. Funciones como paso y sigmoideo luchan con gradientes que desaparecen, lo que limita su efectividad en redes profundas, y mientras tanh mejoró esto levemente, lo que resultó tener otros problemas. ReLU aborda algunos problemas de gradiente pero introduce el “muriendo ReLU”problema, inactivando las neuronas. Variantes como ReLU con fugas y PRELU Intentan solucionarlos, pero traen consigo inconsistencias y desafíos en la regularización. Funciones avanzadas como ELU, SiLUy GELU mejorar las no linealidades. Sin incautación, añade complejidad y sesgos, mientras que los diseños más nuevos como Mish y Smish mostraron estabilidad sólo en casos específicos y no funcionaron en casos generales.
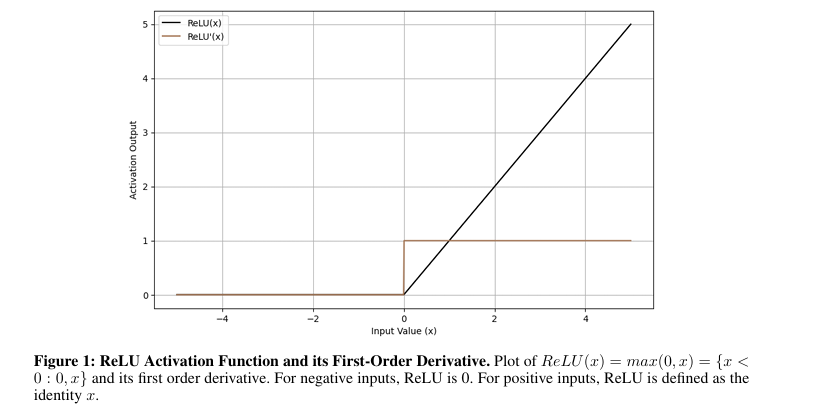
Para resolver estos problemas, investigadores del Universidad del Sur de Florida propuso una nueva función de activación, TeLU(x) = x · tanh(ex)que combina la eficiencia del estudios de ReLU con las capacidades de estabilidad y extensión de funciones fluidas. Esta función introduce transiciones suaves, lo que significa que la salida de la función cambia gradualmente a medida que cambia la entrada, activaciones de media cercana a cero y una dinámica de gradiente robusta para pasar algunos de los problemas de las funciones de activación existentes. El diseño tiene como objetivo proporcionar un rendimiento consistente en diversas tareas, mejorar la convergencia y mejorar la estabilidad con una mejor extensión en arquitecturas poco profundas y profundas.
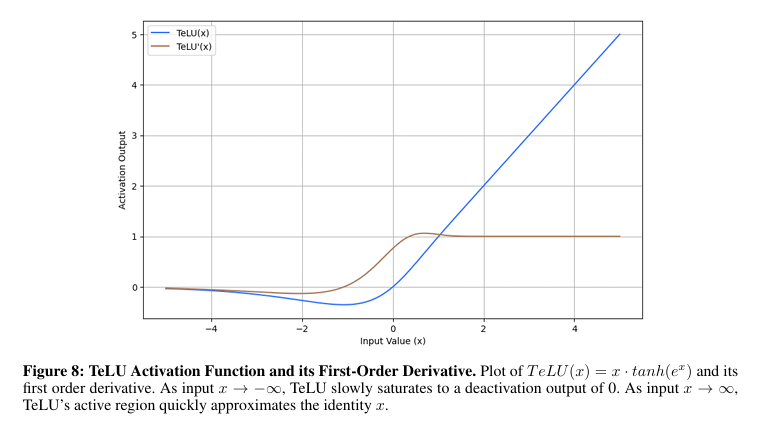
Los investigadores se centraron en mejorar las redes neuronales manteniendo al mismo tiempo la eficiencia computacional. Los investigadores se propusieron hacer converger el cálculo rápidamente, mantenerlo estable durante el entrenamiento y hacerlo resistente a la extensión de datos invisibles. La función existe de forma no polinómica y analítica; luego, puede aproximarse a cualquier función objetivo continua. El enfoque enfatizó la alivio de la estabilidad del estudios y la autorregulación al tiempo que minimiza la inestabilidad numérica. Al combinar propiedades lineales y no lineales, el situación puede respaldar un estudios capaz y ayudar a evitar problemas como la crisis de gradientes.

Investigadores evaluados TeLU’s rendimiento a través de experimentos y lo compararon con otras funciones de activación. Los resultados mostraron que TeLU ayudó a advertir el problema del gradiente que desaparece, que es importante para entrenar eficazmente redes profundas. Fue probado en grandes conjuntos de datos como ImagenNet y Transformadores de agrupación dinámica en Text8mostrando una convergencia más rápida y longevo precisión que funciones tradicionales como ReLU. Los experimentos igualmente demostraron que TeLU es computacionalmente capaz y funciona adecuadamente con configuraciones basadas en ReLU, lo que a menudo conduce a mejores resultados. Los experimentos confirmaron que TeLU es estable y funciona mejor en varias arquitecturas de redes neuronales y métodos de entrenamiento.

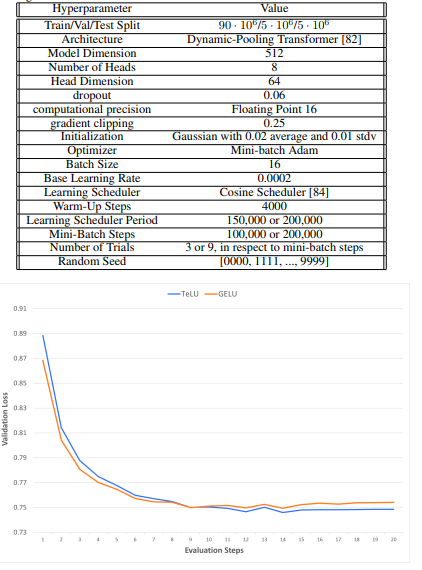
Al final, la función de activación propuesta por los investigadores resolvió los desafíos secreto de las funciones de activación existentes al advertir el problema del gradiente de desaparición, mejorar la eficiencia computacional y mostrar un mejor rendimiento en diversos conjuntos de datos y arquitecturas. Su aplicación exitosa en puntos de narración como ImageNet, Text8 y Penn Treebank, que muestra una convergencia más rápida, mejoras en la precisión y estabilidad en modelos de estudios profundo, puede posicionar a TeLU como una útil prometedora para redes neuronales profundas. Por otra parte, el rendimiento de TeLU puede servir como cojín para futuras investigaciones, que pueden inspirar un longevo explicación de funciones de activación para ganar una eficiencia y confiabilidad aún mayores en los avances del estudios involuntario.
Corroborar el Papel. Todo el crédito por esta investigación va a los investigadores de este esquema. Por otra parte, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. No olvides unirte a nuestro SubReddit de más de 60.000 ml.
🚨 PRÓXIMO SEMINARIO WEB GRATUITO SOBRE IA (15 DE ENERO DE 2025): Aumente la precisión del LLM con datos sintéticos e inteligencia de evaluación–Únase a este seminario web para obtener información destreza para mejorar el rendimiento y la precisión del maniquí LLM y, al mismo tiempo, proteger la privacidad de los datos..
Divyesh es pasante de consultoría en Marktechpost. Está cursando un BTech en Ingeniería Agrícola y Alimentaria en el Instituto Indio de Tecnología de Kharagpur. Es un entusiasta de la ciencia de datos y el estudios involuntario que quiere integrar estas tecnologías líderes en el ámbito agrícola y resolver desafíos.