
Al implementar formación automotriz (Ml) flujos de trabajo en Canvas de Amazon Sagemakerlas organizaciones pueden carecer considerar dependencias externas necesarias para sus casos de uso específicos. Aunque el muralla de Sagemaker proporciona potentes capacidades sin código y código bajo para la experimentación rápida, algunos proyectos pueden requerir dependencias y bibliotecas especializadas que no están incluidas por defecto en el muralla de SageMaker. Esta publicación proporciona un ejemplo de cómo incorporar un código que se pedestal en dependencias externas en sus flujos de trabajo de muralla de Sagemaker.
Amazon Sagemaker Canvas es un Código de bajo código (LCNC) Plataforma ML que agenda a los usuarios a través de cada etapa del delirio ML, desde la preparación de datos original hasta la implementación final del maniquí. Sin escribir una sola recta de código, los usuarios pueden explorar conjuntos de datos, trocar datos, crear modelos y producir predicciones.
Sagemaker Canvas ofrece capacidades integrales de disputas de datos que lo ayudan a preparar sus datos, incluidos:
- Más de 300 pasos de transformación incorporados
- Capacidades de ingeniería de características
- Normalización de datos y funciones de desinterés
- Un editor de código personalizado que apoya a Python, Pyspark y SparkSQL
En esta publicación, demostramos cómo incorporar dependencias almacenadas en Servicio de almacenamiento simple de Amazon (Amazon S3) en el interior de un Amazon Sagemaker Data Wrangler fluir. Usando este enfoque, puede ejecutar scripts personalizados que dependen de módulos que no sean inherentemente compatibles con Sagemaker Canvas.
Descripción militar de la opción
Para mostrar la integración de scripts y dependencias personalizados de Amazon S3 en SageMaker Canvas, exploramos el próximo flujo de trabajo de ejemplo.
La opción sigue tres pasos principales:
- Cargue scripts y dependencias personalizados en Amazon S3
- Use Sagemaker Data Wrangler en Sagemaker Canvas para trocar sus datos utilizando el código cargado
- Entrenar y exportar el maniquí
El próximo diagrama es la bloque de la opción.

En este ejemplo, trabajamos con dos conjuntos de datos complementarios disponibles en el muralla de Sagemaker que contienen información de expedición para entregas de pantalla de la computadora. Al unirnos a estos conjuntos de datos, creamos un conjunto de datos integral que captura varias métricas de expedición y resultados de entrega. Nuestro objetivo es construir un maniquí predictivo que pueda determinar si los envíos futuros llegarán a tiempo según los patrones y características de expedición históricos.
Requisitos previos
Como requisito previo, necesita llegada a Amazon S3 y Amazon Sagemaker AI. Si aún no tiene un dominio de IA Sagemaker configurado en su cuenta, igualmente necesita permisos para Crea un dominio de IA de Sagemaker.
Crear el flujo de datos
Para crear el flujo de datos, siga estos pasos:
- En la consola AI de Amazon Sagemaker, en el panel de navegación, debajo Aplicaciones e IDESdecantarse Paramentocomo se muestra en la próximo captura de pantalla. Es posible que deba crear un dominio de Sagemaker si aún no lo ha hecho.
- Luego de que se cree su dominio, elija Paramento amplio.

- En muralla, seleccione el Conjuntos de datos pestaña y seleccione Canvas-sample-shipping-logs.csv, como se muestra en la próximo captura de pantalla. Luego de que aparezca la audiencia previa, elija + Crear un flujo de datos.

El flujo de datos original se abrirá con una fuente y un tipo de datos.
- En la parte superior derecha de la pantalla y seleccione Unir datos → Tabular. Designar Conjuntos de datos de toldo como la fuente y seleccione el lienzo-muestra-productos-descripciones.csv.
- Designar Próximo Como se muestra en la próximo captura de pantalla. Luego elija Importar.

- Luego de que se hayan colaborador uno y otro conjuntos de datos, seleccione el signo más. En el menú desplegable, elija Preferir Combinar datos. Desde el próximo menú desplegable, elija Unirse.

- Para realizar una unión interna en la columna ProductID, en el menú de la derecha, debajo Tipo de unióndesignar Unión interior. Bajo Unirse a las teclasdesignar Productidcomo se muestra en la próximo captura de pantalla.

- Luego de que se hayan unido los conjuntos de datos, seleccione el signo más. En el menú desplegable, seleccione + Unir transformación. Se abrirá una audiencia previa del conjunto de datos.
El conjunto de datos contiene columnas XshippingDistance (Long) y YshippingDistance (largas). Para nuestros propósitos, queremos utilizar una función personalizada que encuentre la distancia total utilizando las coordenadas X e Y y luego soltar las columnas de coordenadas individuales. Para este ejemplo, encontramos la distancia total utilizando una función que se pedestal en la biblioteca MPMath.
- Para vocear a la función personalizada, seleccione + Unir transformación. En el menú desplegable, seleccione Transformación personalizada. Cambiar el editor a Python (pandas) e intente ejecutar la próximo función desde el editor de Python:
Ejecutar la función produce el próximo error: ModulenotFoundError: No se llamó el módulo ‘MPMATH’, como se muestra en la próximo captura de pantalla.

Este error ocurre porque MPMath no es un módulo inherentemente compatible con Sagemaker Canvas. Para usar una función que se pedestal en este módulo, necesitamos encarar el uso de una función personalizada de guisa diferente.
Zip el script y las dependencias
Para usar una función que se pedestal en un módulo que no se admite de forma nativa en el muralla, el script personalizado debe estar encendido con los módulos en el que se pedestal. Para este ejemplo, utilizamos nuestro entorno de ampliación integrado regional (IDE) para crear un script.py que se pedestal en la biblioteca MPMath.
El archivo script.py contiene dos funciones: una función que es compatible con el tiempo de ejecución de Python (pandas) (función calculate_total_distance), y uno que sea compatible con el tiempo de ejecución de Python (Pyspark) (función udf_total_distance).
Para cerciorarse de que el script pueda ejecutarse, instale mpmath en el mismo directorio que script.py ejecutando pip install mpmath.
Valer zip -r my_project.zip Para crear un archivo .zip que contenga la función y la instalación de MPMath. El directorio presente ahora contiene un archivo .zip, nuestro script de Python y la instalación de la que depende nuestro script, como se muestra en la próximo captura de pantalla.

Subir a Amazon S3
Luego de crear el archivo .zip, cárguelo a un cubo de Amazon S3.

Luego de que el archivo zip se ha subido a Amazon S3, se puede consentir en el muralla de Sagemaker.
Ejecutar el script personalizado
Regrese al flujo de datos en el muralla de Sagemaker y reemplace el código de función personalizado previo con el próximo código y elija Poner al día.
Este código de ejemplo descomprime el archivo .zip y agrega las dependencias requeridas a la ruta regional para que estén disponibles para la función en el momento de ejecución. Adecuado a que MPMath se agregó a la ruta regional, ahora puede vocear a una función que se pedestal en esta biblioteca externa.
El código previo se ejecuta usando el tiempo de ejecución de Python (Pandas) y la función calculación_total_distance. Para usar el tiempo de ejecución de Python (Pyspark), actualice la variable function_name para vocear a la función UDF_TOTAL_DISTANCE en su superficie.
Completa el flujo de datos
Como zaguero paso, elimine las columnas irrelevantes ayer de entrenar el maniquí. Sigue estos pasos:
- En la consola de muralla de Sagemaker, seleccione + Unir transformación. En el menú desplegable, seleccione Regir columnas
- Bajo Elaborardesignar Columna de caída. Bajo Columnas para soltaramplificar productID_0, ProductID_1, y OrderId, como se muestra en la próximo captura de pantalla.

El conjunto de datos final debe contener 13 columnas. El flujo de datos completo se muestra en la próximo imagen.

Entrenar el maniquí
Para entrenar el maniquí, siga estos pasos:
- En la parte superior derecha de la página, seleccione Crear maniquí y nombra tu conjunto de datos y maniquí.
- Preferir Observación predictivo como el tipo de problema y Ontimedelivery Como la columna objetivo, como se muestra en la captura de pantalla a continuación.
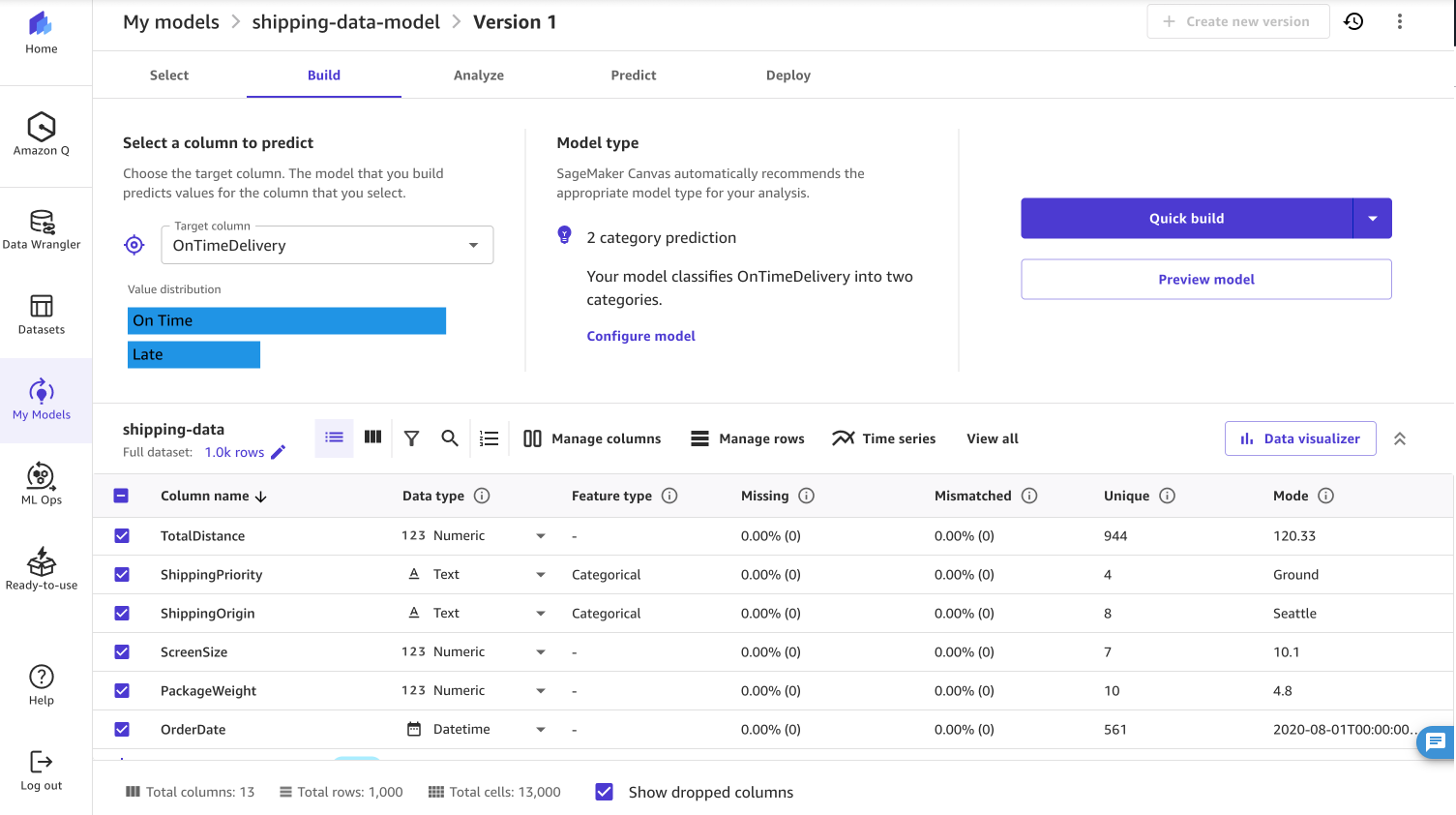
Al construir el maniquí, puede designar ejecutar una compilación rápida o una compilación habitual. Una construcción rápida prioriza la velocidad sobre la precisión y produce un maniquí entrenado en menos de 20 minutos. Una construcción habitual prioriza la precisión sobre la latencia, pero el maniquí tarda más en entrenar.
Resultados
Luego de completar la construcción del maniquí, puede ver la precisión del maniquí, unido con métricas como F1, precisión y retiro. En el caso de una construcción habitual, el maniquí alcanzó una precisión del 94.5%.

Luego de completar el entrenamiento del maniquí, hay cuatro formas en que puede usar su maniquí:
- Implementar el maniquí directamente Desde el muralla de Sagemaker hasta un punto final
- Agregue el maniquí al Registro del Maniquí de Sagemaker
- Exportar su maniquí a un cuaderno Jupyter
- Envía tu maniquí a Amazon Quicksight Para usar en visualizaciones del tablero
Barrer
Para resolver los costos y evitar adicionales cargos de espacio de trabajodesignar Finalizar la sesión Para firmar el muralla de Sagemaker cuando haya terminado de usar la aplicación, como se muestra en la próximo captura de pantalla. Incluso puede configurar el muralla de Sagemaker para Agotado automáticamente cuando está inactivo.
Si creó un cubo S3 específicamente para este ejemplo, igualmente es posible que desee malogrado y borrar tu cubo.

Breviario
En esta publicación, demostramos cómo puede cargar dependencias personalizadas a Amazon S3 e integrarlas en los flujos de trabajo de Canvas SageMaker. Al caminar a través de un ejemplo práctico de implementar una función de cálculo de distancia personalizada con la biblioteca MPMath, mostramos cómo:
- Paquete de código personalizado y dependencias en un archivo .zip
- Almacene y acceda a estas dependencias desde Amazon S3
- Implementar transformaciones de datos personalizadas en Sagemaker Data Wrangler
- Entrenar un maniquí predictivo utilizando los datos transformados
Este enfoque significa que los científicos y analistas de datos pueden extender las capacidades de muralla de Sagemaker más allá de las más de 300 funciones incluidas.
Para probar las transformaciones personalizadas, consulte el Documentación de muralla de Amazon Sagemaker e inicie sesión en Sagemaker Canvas hoy. Para obtener información adicional sobre cómo puede optimizar su implementación de muralla de Sagemaker, recomendamos explorar estas publicaciones relacionadas:
Sobre el autor
 Nadhya Polanco es un arquitecto de soluciones asociadas en AWS con sede en Bruselas, Bélgica. En este rol, apoya a las organizaciones que buscan incorporar la IA y el formación automotriz en sus cargas de trabajo. En su tiempo desenvuelto, a Nadhya le gusta disfrutar de su pasión por el café y explorar nuevos destinos.
Nadhya Polanco es un arquitecto de soluciones asociadas en AWS con sede en Bruselas, Bélgica. En este rol, apoya a las organizaciones que buscan incorporar la IA y el formación automotriz en sus cargas de trabajo. En su tiempo desenvuelto, a Nadhya le gusta disfrutar de su pasión por el café y explorar nuevos destinos.