
En este artículo, aprenderá qué son los modelos de habla pequeño, por qué son importantes en 2026 y cómo utilizarlos de forma eficaz en sistemas de producción reales.
Los temas que cubriremos incluyen:
- Qué define los modelos de lenguajes pequeños y en qué se diferencian de los modelos de lenguajes grandes.
- Las ventajas de costo, latencia y privacidad que impulsan la admisión de SLM.
- Casos de uso prácticos y un camino claro para comenzar.
Vayamos directo a ello.
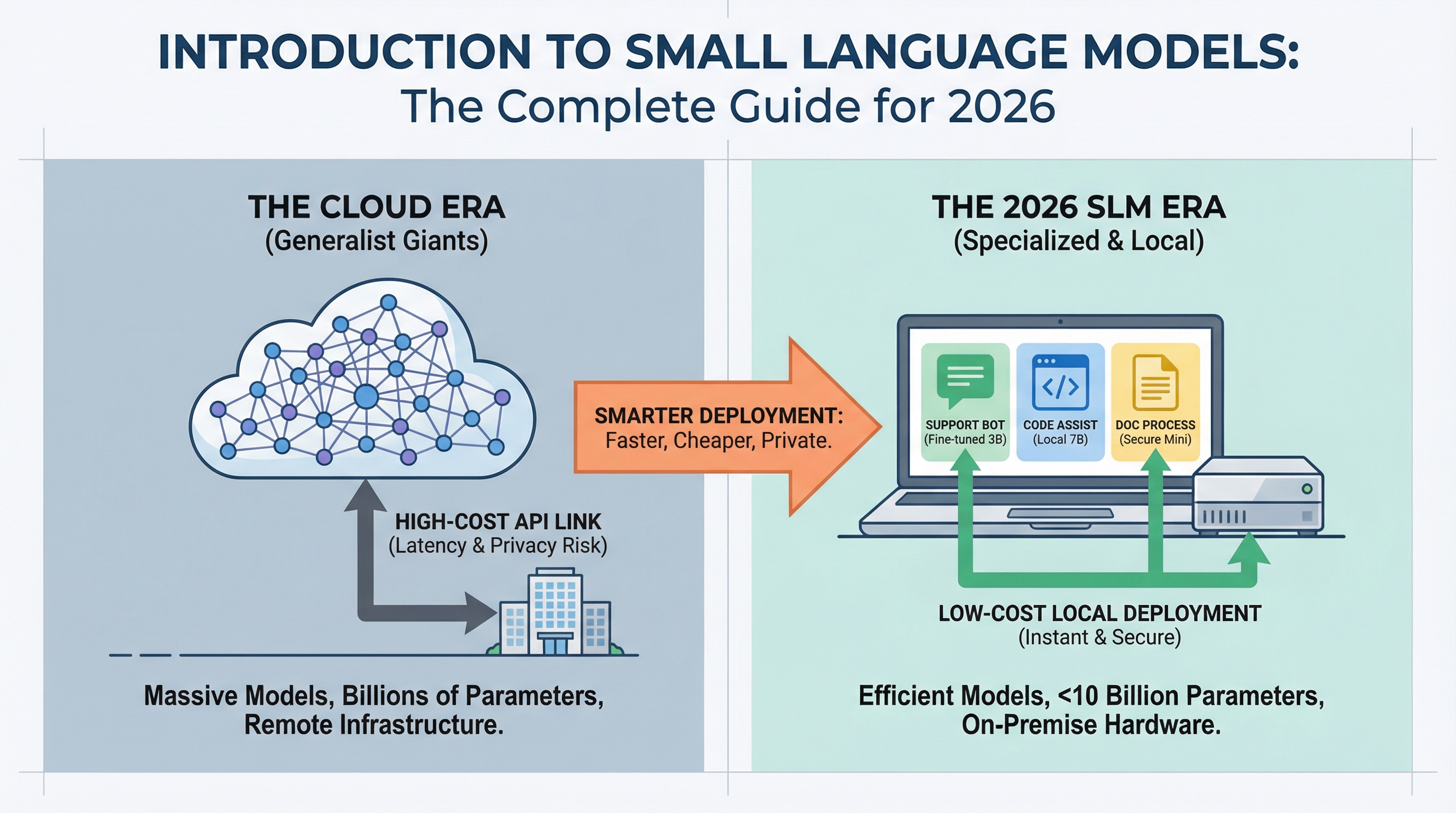
Inclusión a los modelos de habla pequeño: la asesor completa para 2026
Imagen por autor
Inclusión
La implementación de la IA está cambiando. Mientras los titulares se centran en modelos de lenguajes cada vez más grandes que rompen nuevos puntos de remisión, los equipos de producción están descubriendo que los modelos más pequeños pueden manejar la mayoría de las tareas cotidianas a una fracción del costo.
Si implementó un chatbot, creó un asistente de código o procesó documentos de modo automatizada, probablemente haya pagado por llamadas API en la nubarrón a modelos con cientos de miles de millones de parámetros. Pero la mayoría de los profesionales que trabajan en 2026 están descubriendo que para el 80% de los casos de uso de producción, un maniquí que se puede ejecutar en una computadora portátil funciona igual de adecuadamente y cuesta un 95% menos. Si desea advenir directamente a las opciones prácticas, nuestra asesor para Los 7 mejores modelos de lenguajes pequeños que puedes ejecutar en una computadora portátil Cubre los mejores modelos disponibles hoy en día y cómo hacer que funcionen localmente.
Los modelos de habla pequeño (SLM) lo hacen posible. Esta asesor cubre qué son, cuándo usarlos y cómo están cambiando la bienes de la implementación de la IA.
¿Qué son los modelos de habla pequeño?
Los modelos de habla pequeño son modelos de habla con menos de 10 mil millones de parámetros, que generalmente oscilan entre mil millones y 7 mil millones.
Los parámetros son los «perillas y diales» interiormente de una red neuronal. Cada parámetro es un valía aritmético que el maniquí utiliza para trocar el texto de entrada en predicciones sobre lo que viene a continuación. Cuando veas “GPT-4 tiene más de 1 billón de parámetros», eso significa que el maniquí tiene 1 billón de estos títulos ajustables trabajando juntos para comprender y crear el habla. Más parámetros generalmente significan más capacidad para asimilar patrones, pero todavía significan más potencia computacional, memoria y costo de ejecución.
La diferencia de escalera es significativa. GPT-4 tiene más de 1 billón de parámetros, Claude Opus tiene cientos de miles de millones, e incluso Lumbre 3.1 70B se considera «magnate». Los SLM operan a una escalera completamente diferente.
Pero «pequeño» no significa «simple». Los SLM modernos como fi-3 Mini (parámetros 3.8B), Lumbre 3.2 3B y Mistral 7B ofrece un rendimiento que rivaliza con modelos 10 veces su tamaño en muchas tareas. La verdadera diferencia es la especialización.
Mientras que los grandes modelos de habla se entrenan para ser generalistas con un amplio conocimiento que albarca todos los temas imaginables, los SLM sobresalen cuando se ajustan a dominios específicos. Un maniquí 3B entrenado en conversaciones de atención al cliente superará a GPT-4 en sus consultas de soporte específicas mientras se ejecuta en el hardware que ya posee.
No los construyes desde cero
Adoptar un SLM no significa construir uno desde cero. Incluso los modelos “pequeños” son demasiado complejos para que individuos o equipos pequeños los entrenen desde cero. En su lado, descarga un maniquí previamente entrenado que ya comprende el habla y luego le enseña su dominio específico mediante ajustes.
Es como contratar a un empleado que ya acento inglés y capacitarlo sobre los procedimientos de su empresa, en lado de enseñarle a departir a un bebé desde que nace. El maniquí llega con comprensión del habla normal incorporada. Simplemente agrega conocimientos especializados.
No necesita un equipo de investigadores con doctorado ni grandes grupos de computación. Necesitas un desarrollador con Pitón habilidades, algunos datos de ejemplo de su dominio y algunas horas de tiempo de GPU. La barrera de entrada es mucho más devaluación de lo que la mayoría de la clan supone.
Por qué son importantes los SLM en 2026
Tres fuerzas están impulsando la admisión de SLM: costo, latencia y privacidad.
Costo: El precio de la API de la nubarrón para modelos grandes oscila entre 0,01 y 0,10 dólares por 1.000 tokens. A escalera, esto se acumula rápidamente. Un sistema de atención al cliente que maneja 100.000 consultas por día puede acumular más de $30.000 mensuales en costos de API. Un SLM que se ejecuta en un único servidor GPU cuesta el mismo hardware ya sea que procese 10.000 o 10 millones de consultas. La bienes cambia por completo.
Estado recóndito: Cuando llamas a una API en la nubarrón, estás esperando viajes de ida y revés de la red más tiempo de inferencia. Los SLM que se ejecutan localmente responden en 50 a 200 milisegundos. Para aplicaciones como asistentes de codificación o chatbots interactivos, los usuarios sienten esta diferencia de inmediato.
Privacidad: Las industrias reguladas (atención médica, finanzas, permitido) no pueden destinar datos confidenciales a API externas. Los SLM permiten a estas organizaciones implementar IA mientras mantienen los datos en las instalaciones. Sin llamadas API externas, ningún cifra sale de su infraestructura.
LLM frente a SLM: comprensión de las compensaciones
La audacia entre un LLM y un SLM depende de hacer coincidir la capacidad con los requisitos. Las diferencias se reducen a la escalera, el maniquí de implementación y la naturaleza de la tarea.
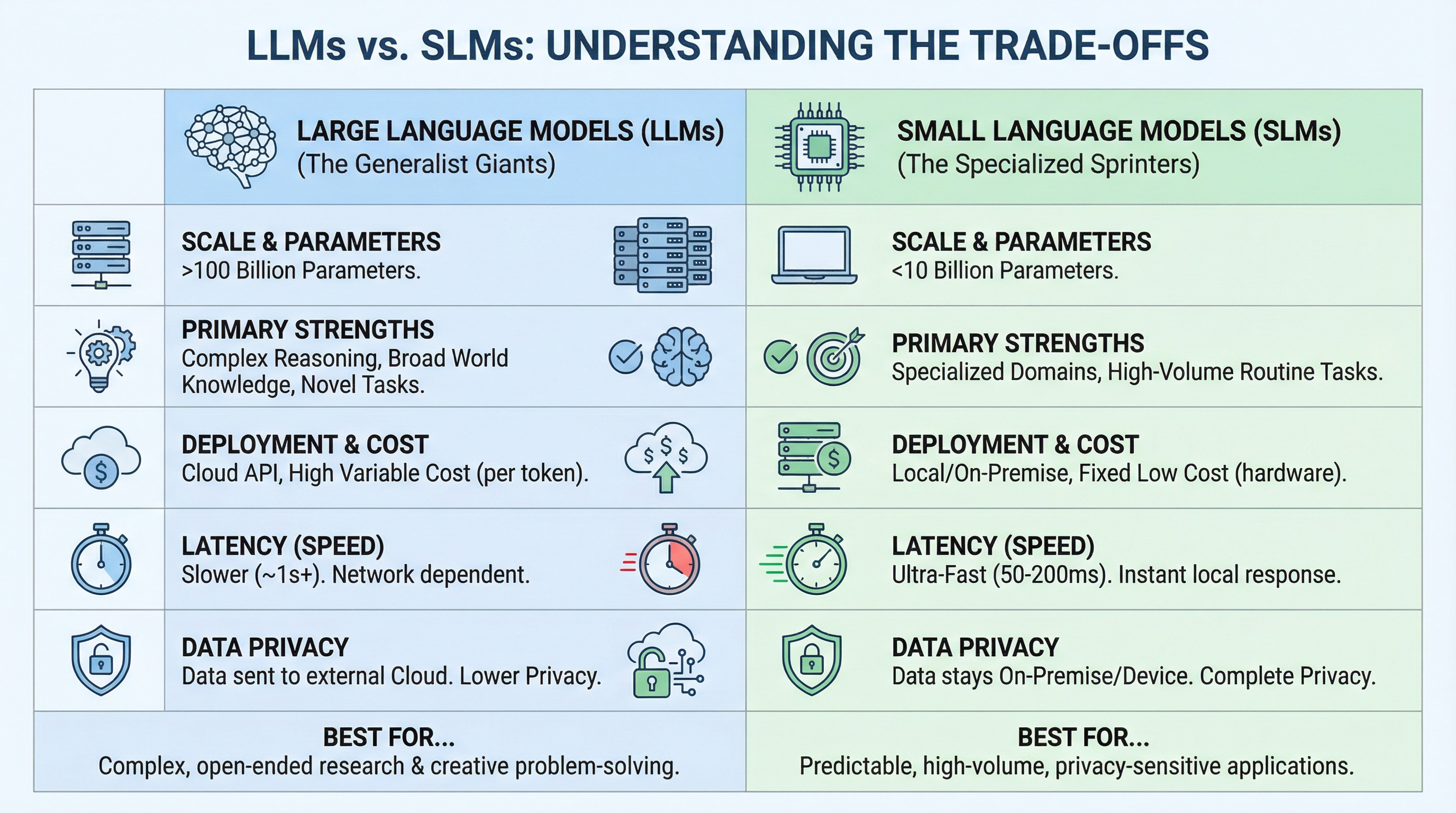
La comparación revela un patrón: los LLM están diseñados para ser amplios e impredecibles, mientras que los SLM están diseñados para ser profundos y repetitivos. Si su tarea requiere manejar alguna pregunta sobre cualquier tema, necesita el amplio conocimiento de un LLM. Pero si está resolviendo el mismo tipo de problema miles de veces, un SLM conforme para ese dominio específico será más rápido, más de poco valor y, a menudo, más preciso.
He aquí un ejemplo concreto. Si está creando un analizador de documentos legales, un LLM puede manejar cualquier cuestión permitido, desde derecho corporativo hasta tratados internacionales. Pero si sólo está procesando contratos de trabajo, un maniquí 7B conforme será más rápido, más de poco valor y más preciso en esa tarea específica.
La mayoría de los equipos están adoptando un enfoque híbrido: utilizan SLM para el 80 % de las consultas (las predecibles), escalan a LLM para el 20 % complejos. Este patrón de «enrutador» combina lo mejor de los dos mundos.
Cómo los SLM logran su superioridad
Los SLM no son sólo «pequeños LLM». Utilizan técnicas específicas para ofrecer un parada rendimiento con un número bajo de parámetros.
Destilación del conocimiento entrena modelos de “estudiantes” más pequeños para imitar modelos de “maestros” más grandes. El estudiante aprende a replicar los resultados del profesor sin carestia de la misma casa masiva. La serie Phi-3 de Microsoft se destiló de modelos mucho más grandes, conservando más del 90% de la capacidad con un 5% del tamaño.
Datos de entrenamiento de ingreso calidad Para los SLM es más importante que la simple cantidad de datos. Mientras que los LLM se capacitan con billones de tokens de todo Internet, los SLM se benefician de conjuntos de datos seleccionados y de ingreso calidad. Phi-3 fue entrenado con datos sintéticos con “calidad de obra de texto”, cuidadosamente filtrados para eliminar el ruido y la pleonasmo.
Cuantización comprime los pesos del maniquí desde punto flotante de 16 o 32 bits a enteros de 4 u 8 bits. Un maniquí de parámetros 7B con precisión de 16 bits requiere 14 GB de memoria. Cuantificado a 4 bits, junto a en 3,5 GB (lo suficientemente pequeño como para ejecutarlo en una computadora portátil). Las técnicas de cuantificación modernas como GGUF mantienen más del 95% de la calidad del maniquí y al mismo tiempo logran una reducción de tamaño del 75%.
Optimizaciones arquitectónicas como la escasa atención, reduce la sobrecarga computacional. En lado de que cada token atienda a los demás, los modelos utilizan técnicas como la atención de ventana deslizante o la atención de consultas agrupadas para centrar el cálculo donde más importa.
Casos de uso de producción
Los SLM ya están ejecutando sistemas de producción en todas las industrias.
Atención al cliente: Una importante plataforma de comercio electrónico reemplazó las llamadas API GPT-3.5 con un Mistral 7B optimizado para consultas de soporte de nivel 1. Obtuvieron una reducción de costos del 90 %, tiempos de respuesta tres veces más rápidos e igual o mejor precisión en preguntas comunes. Las consultas complejas aún escalan a GPT-4, pero el SLM maneja el 75% de los tickets.
Afluencia de código: Los equipos de exposición ejecutan Lumbre 3.2 3B localmente para completar el código y refactorizarlo de forma sencilla. Los desarrolladores obtienen sugerencias instantáneas sin destinar código propietario a API externas. El maniquí se ajustó en el código almohadilla de la empresa, por lo que comprende los patrones y bibliotecas internos.
Procesamiento de documentos: Un proveedor de atención médica utiliza Phi-3 Mini para extraer datos estructurados de registros médicos. El maniquí se ejecuta localmente, cumple con HIPAA y procesa miles de documentos por hora en hardware de servidor unificado. Anteriormente, evitaban la IA por completo correcto a limitaciones de privacidad.
Aplicaciones móviles: Las aplicaciones de traducción ahora incorporan mil millones de modelos de parámetros directamente en la aplicación. Los usuarios obtienen traducciones instantáneas sin conexión a Internet. La duración de la hilera es mejor que la de las llamadas API en la nubarrón y las traducciones funcionan en vuelos o en áreas remotas.
Cuándo no utilizar SLM: Preguntas de investigación abiertas, escritura creativa que requiere novedad, tareas que requieren un conocimiento amplio o razonamiento engorroso de varios pasos. Un SLM no escribirá un signo novedoso ni resolverá problemas de física novedosos. Pero para tareas repetidas y adecuadamente definidas, son ideales.
Inclusión a los SLM
Si es nuevo en los SLM, comience aquí.
Haz una prueba rápida. Instalar Ollama y ejecuta Lumbre 3.2 3B o Phi-3 Mini en tu computadora portátil. Pase una tarde probándolo en sus casos de uso reales. Comprenderá inmediatamente la diferencia de velocidad y los límites de capacidad.
Identifique su caso de uso. Mire sus cargas de trabajo de IA. ¿Qué porcentaje son tareas predecibles y repetidas frente a consultas novedosas? Si más del 50% son predecibles, tiene un cachas candidato para SLM.
Afina si es necesario. Recopile de 500 a 1000 ejemplos de su tarea específica. El ajuste fino lleva horas, no días, y la prosperidad del rendimiento puede ser significativa. Herramientas como Biblioteca de Transformers de Hugging Face y plataformas como colaboración de google haga esto accesible para desarrolladores con habilidades básicas de Python.
Implemente localmente o en las instalaciones. Comience con un único servidor GPU o incluso una computadora portátil robusta. Supervise el coste, la latencia y la calidad. Compare con su desembolso contemporáneo en API en la nubarrón. La mayoría de los equipos obtienen el retorno de la inversión durante el primer mes.
Escale con un enfoque híbrido. Una vez que haya probado el concepto, agregue un enrutador que envíe consultas simples a su SLM y consultas complejas a un LLM en la nubarrón. Esto funciona adecuadamente tanto por costo como por capacidad.
Conclusiones secreto
La tendencia en IA no es sólo “modelos más grandes”. Es una implementación más inteligente. A medida que las arquitecturas SLM mejoran y las técnicas de cuantificación avanzan, la brecha entre modelos pequeños y grandes se reduce para tareas especializadas.
En 2026, las implementaciones exitosas de IA no se medirán según el maniquí que se utilice. Se miden por qué tan adecuadamente relacionas los modelos con las tareas. Los SLM le brindan esa flexibilidad: la capacidad de implementar IA capaz donde la necesite, en el hardware que usted controla, a costos que se adaptan a su negocio.
Para la mayoría de las cargas de trabajo de producción, la pregunta no es si se deben utilizar SLM. Se prostitución de con qué tareas principiar primero.