
La IA desempeña un papel fundamental en la creación de conexiones valiosas entre personas y anunciantes interiormente de la comunidad de aplicaciones de Meta. El motor de recomendación de anuncios de Meta, impulsado por Modelos de recomendación de estudios profundo (DLRM)ha sido fundamental para ofrecer anuncios personalizados a las personas. La esencia de este éxito fue la incorporación de miles de señales o funciones diseñadas por humanos en el sistema de recomendación basado en DLRM.
A pesar de la capacitación sobre grandes cantidades de datos, existen limitaciones en las recomendaciones actuales de anuncios basados en DLRM con ingeniería de funciones manual oportuno a la incapacidad de los DLRM para emplear la información secuencial de los datos de la experiencia de las personas. Para capturar mejor el comportamiento experiencial, los modelos de recomendación de anuncios han experimentado transformaciones fundamentales en dos dimensiones:
- Formación basado en eventos: educarse representaciones directamente de los eventos de conversión y décimo de una persona en circunscripción de las funciones tradicionales diseñadas por humanos.
- Educarse de secuencias: desarrollar nuevas arquitecturas de estudios de secuencias para reemplazar las arquitecturas de redes neuronales DLRM tradicionales.
Al incorporar estos avances de los campos de la comprensión del estilo natural y la visión por computadora, el motor de recomendación de anuncios de próxima concepción de Meta aborda las limitaciones de los DLRM tradicionales, lo que resulta en anuncios más relevantes para las personas, anciano valencia para los anunciantes y una mejor eficiencia de la infraestructura.
Estas innovaciones han permitido que nuestro sistema de anuncios desarrolle una comprensión más profunda del comportamiento de las personas ayer y luego de realizar una conversión en un anuncio, lo que nos permite inferir el venidero conjunto de anuncios relevantes. Desde su tiro, el nuevo sistema de recomendación de anuncios ha mejorado la precisión de la predicción de anuncios, lo que genera un anciano valencia para los anunciantes y entre un 2% y un 4% más de conversiones en segmentos seleccionados.
Los límites de los DLRM para las recomendaciones de anuncios
Los DLRM de Meta para anuncios personalizados se basan en una amplia gradación de señales para comprender la intención de importación y las preferencias de las personas. Los DLRM han revolucionado el estudios a partir de características escasasque capturan las interacciones de una persona en entidades como las páginas de Facebook, que tienen cardinalidades masivas, a menudo de miles de millones. El éxito de los DLRM se cimiento en su capacidad para educarse representaciones generalizables y de entrada dimensión, es asegurar, incorporaciones a partir de características dispersas.
Para emplear decenas de miles de estas características, se emplean varias estrategias para combinar características, cambiar representaciones intermedias y componer los resultados finales. Por otra parte, sanalizar características se construyen agregando atributos a través de las acciones de una persona durante varias ventanas de tiempo con diferentes fuentes de datos y esquemas de agregación.
Algunos ejemplos de características heredadas dispersas diseñadas de esta forma serían:
- Anuncios en los que una persona hizo clic en los últimos N días → (Ad-id1, Ad-id2, Ad-id3,…, Ad-idN)
- Páginas de Facebook que una persona visitó en los últimos M días con una puntuación de cuántas visitas en cada página → ((Page-id1, 45), (Page-id2, 30), (Page-id3, 8),…)
Las escasas funciones diseñadas por humanos, como se describe anteriormente, han sido la piedra angular de las recomendaciones personalizadas con DLRM durante varios abriles. Pero este enfoque tiene limitaciones:
- Pérdida de información secuencial: la información de secuencia, es asegurar, el orden de los eventos de una persona, puede proporcionar información valiosa para mejores recomendaciones de anuncios relevantes para el comportamiento de una persona. Las agregaciones dispersas de funciones pierden la información secuencial en los viajes de una persona.
- Pérdida de información granular: la información detallada, como la colocación de atributos en el mismo evento, se pierde a medida que se agregan características entre eventos.
- Confianza en la intuición humana: Es poco probable que la intuición humana reconozca interacciones y patrones complejos y no intuitivos a partir de grandes cantidades de datos.
- Espacio de funciones redundante: se crean múltiples variantes de funciones con diferentes esquemas de agregación. Aunque proporcionan un valencia incremental, las agregaciones superpuestas aumentan los costos de computación y almacenamiento y hacen que la delegación de funciones sea engorrosa.
Los intereses de las personas evolucionan con el tiempo con intenciones dinámicas y en continua transformación. Estas complejidades son difíciles de modelar con principios hechos a mano. Modelar estas interdinámicas ayuda a obtener una comprensión más profunda del comportamiento de una persona a lo espacioso del tiempo para obtener mejores recomendaciones de anuncios.
Un cambio de ideal con el estudios de secuencias para sistemas de recomendación
El nuevo sistema de Meta para recomendaciones de anuncios utiliza el estudios de secuencias en su núcleo. Esto requirió un rediseño completo del sistema de recomendaciones de anuncios en todo el almacenamiento de datos, los formatos de entrada de funciones y la inmueble del maniquí. El rediseño requirió la construcción de una nueva infraestructura centrada en las personas, capacitación y optimización de servicios para arquitecturas de estudios de secuencias de última concepción y codiseño de maniquí/sistema para un escalamiento capaz.
Funciones basadas en eventos
Las características basadas en eventos (EBF) son los componentes básicos de los nuevos modelos de estudios secuencial. Los EBF, una modernización de las funciones tradicionales, estandarizan entradas heterogéneas para secuenciar modelos de estudios en tres dimensiones:
- Flujos de eventos: el flujo de datos para un EBF, por ejemplo, la secuencia de anuncios recientes con los que interactuó la familia o la secuencia de páginas que le gustaron a la familia.
- La largo de la secuencia define cuántos eventos recientes se incorporan de cada secuencia y está determinada por la importancia de cada secuencia.
- Información del evento: captura información semántica y contextual sobre cada evento en la transmisión, como la categoría de anuncio con la que interactuó una persona y la marca de tiempo del evento.
Cada EBF es un único objeto coherente que captura toda la información esencia sobre un evento. EBF permítanos incorporar información rica y prosperar los insumos sistemáticamente. Las secuencias EBF reemplazan las características escasas heredadas como entradas principales a los modelos de recomendación. Cuando se combinan con los modelos de eventos que se describen a continuación, los EBF han afectado el principio de un alejamiento de las agregaciones de características diseñadas por humanos.
Modelado de secuencias con EBF
Un maniquí de eventos sintetiza incorporaciones de eventos a partir de atributos de eventos. Aprende incrustaciones para cada atributo y utiliza compresión derecho para resumirlas en una incrustación basada en atributos de un solo evento. Los eventos tienen marcas de tiempo codificadas para capturar su hogaño y orden temporal. El maniquí de eventos combina la codificación de marca de tiempo con la incrustación basada en atributos de eventos sintetizados para producir la representación final a nivel de evento, traduciendo así una secuencia EBF en una secuencia de incrustación de eventos.
Esto es similar a cómo los modelos de estilo usan incrustaciones para representar palabras. La diferencia es que los EBF tienen un vocabulario que es muchos órdenes de magnitud anciano que un estilo natural porque provienen de flujos de eventos heterogéneos y abarcan millones de entidades.
Las incorporaciones de eventos del maniquí de eventos luego se introducen en el maniquí de secuencia en el centro del sistema de recomendación de anuncios de próxima concepción. El maniquí de secuencia de eventos es un maniquí de breviario de eventos a nivel de persona que consume incrustaciones de eventos secuenciales. Utiliza mecanismos de atención de última concepción. a sintetizar las incrustaciones de eventos en un número predefinido de incrustaciones que están codificadas por el anuncio que se va a clasificar. Con técnicas como la agrupación de atención de múltiples cabezas, la complejidad del módulo de autoatención se reduce de oh(N*N) a oh(M*N). M es un parámetro ajustable y N es la largo máxima de la secuencia de eventos.
La venidero figura ilustra las diferencias entre los DLRM con un ideal de características diseñadas por humanos (izquierda) y el ideal de modelado de secuencia con EBF (derecha) desde la perspectiva del flujo de eventos de una persona.
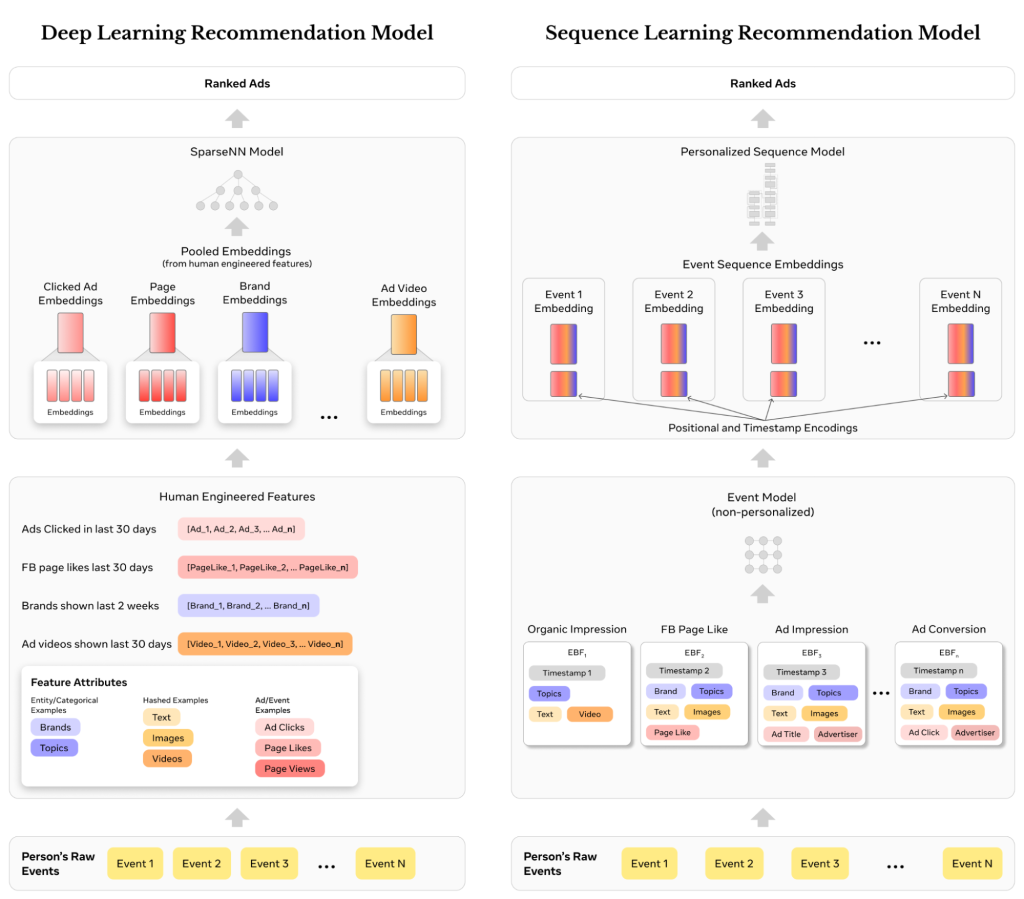
Ampliando el nuevo ideal de estudios secuencial
Tras el rediseño para ocurrir del estudios de funciones dispersas al estudios de secuencias basado en eventos, el venidero enfoque fue prosperar en dos dominios: prosperar la inmueble de estudios de secuencias y prosperar las secuencias de eventos para que sean más largas y ricas.
Escalado de arquitecturas de estudios de secuencias
Se desarrolló una inmueble de transformador personalizada que incorpora complejos esquemas de codificación de características para modelar completamente información secuencial para permitir una exploración y prohijamiento más rápidas de técnicas de última concepción para sistemas de recomendación. El principal desafío con este enfoque arquitectónico es obtener los requisitos de rendimiento y eficiencia para la producción. Una solicitud al sistema de recomendación de anuncios de Meta tiene que clasificar miles de anuncios en unos pocos cientos de milisegundos.
Para prosperar el estudios de representación para una anciano fidelidad, el enfoque de agrupación de sumas existente fue reemplazado con una nueva inmueble que aprendió interacciones de características a partir de incrustaciones no agrupadas. Mientras que el sistema mencionado basado en características agregadas estaba enormemente optimizado para incorporaciones de largo fija que se agrupan mediante métodos simples como el promedio, el estudios de secuencias presenta nuevos desafíos porque diferentes personas tienen diferentes duraciones de eventos. Las secuencias de eventos de largo variable más largas, representadas por tensores de incrustación irregulares e incrustaciones no agrupadas, generan mayores costos de computación y comunicación con anciano variación.
Este desafío de costos crecientes se aborda mediante la prohijamiento de innovaciones en el diseño de código de hardware para soportar tensores irregulares, a retener:
- Capacidades nativas de PyTorch para alojar tensores irregulares.
- Optimización a nivel de kernel para procesar tensores irregulares en GPU.
- A Atención de destello irregular Módulo para alojar Flash Attention en tensores irregulares.
Escalado con secuencias más largas y ricas
La capacidad del sistema de recomendación de próxima concepción de Meta para educarse directamente de secuencias de eventos para comprender mejor las preferencias de las personas se restablecimiento aún más con secuencias más largas y atributos de eventos más ricos.
El escalamiento de secuencia implicó:
- Escalado con secuencias más largas: El aumento de la duración de las secuencias proporciona conocimientos y contexto más profundos sobre los intereses de una persona. Se utilizan técnicas como la cuantificación de precisión múltiple y las técnicas de muestreo basadas en títulos para prosperar de forma capaz la largo de la secuencia.
- Progresar con una semántica más rica: Los EBF nos permiten capturar señales semánticas más ricas sobre cada evento, por ejemplo, a través de incrustaciones de contenido multimodal. Se utilizan técnicas de cuantificación vectorial personalizadas para codificar de forma capaz los atributos de incrustación de cada evento. Esto produce una representación más informativa de la incorporación del evento final.
El impacto y el futuro del estudios secuencial
El ideal de estudios de secuencia de eventos se ha adoptivo ampliamente en todos los sistemas publicitarios de Meta, lo que ha legado como resultado mejoras en la relevancia y el rendimiento de los anuncios, una infraestructura más capaz y una velocidad de investigación acelerada. Contiguo con nuestro enfoque en progresista arquitecturas transformadorasel estudios de secuencia de eventos ha remodelado el enfoque de Meta en dirección a los sistemas de recomendación de anuncios.
En el futuro, la atención se centrará en prosperar aún más las secuencias de eventos hasta 100 veces, desarrollar arquitecturas de modelado de secuencias más eficientes, como modelos de atención derecho y espacio de estados, optimización de distinción de títulos esencia (KV) y ganancia multimodal de secuencias de eventos.
Expresiones de devolución
Nos gustaría pagar Neeraj BhatiaZhirong Chen, Parshva Doshi, Jonathan Herbach, Yuxi HuAbha Jain, Kun Jiang, Santanu KolayBoyang Li, Hong Li, Paolo Massimi, Sandeep Pandey, Dinesh Ramasamy, Ketan SinghDoris Wang, Rengan Xu, Junjie Yang y todo el equipo de estudios de secuencia de eventos involucrado en el crecimiento y producción del sistema de recomendación de anuncios basado en el estudios de secuenciación de próxima concepción.