
La construcción de una plataforma AI o ML de extremo a extremo a menudo requiere múltiples capas tecnológicas para el almacenamiento, el examen, las herramientas de inteligencia empresarial (BI) y los modelos ML para analizar datos y compartir aprendizajes con funciones comerciales. El desafío es implementar controles de gobernanza consistentes y efectivos en diferentes partes con diferentes equipos.
Unity Catálogo es la capa de metadatos centralizadas y de Databricks diseñada para tener la llave de la despensa el acercamiento a los datos, la seguridad y el clase. Igualmente sirve como almohadilla para la búsqueda y el descubrimiento en el interior de la plataforma. El catálogo de Unity facilita la colaboración entre los equipos al ofrecer características robustas como el control de acercamiento basado en roles (RBAC), los senderos de auditoría y el enmascaramiento de datos, asegurando que la información confidencial esté protegida sin obstaculizar la productividad. Igualmente admite los ciclos de vida de extremo a extremo para modelos ML.
Esta folleto proporcionará una descripción caudillo y directrices sobre cómo utilizar catálogos de Unity para casos de uso de formación involuntario y colaborar entre los equipos al compartir capital de cuenta.
Esta publicación de blog lo lleva a través de los pasos para el ciclo de vida de extremo a extremo del formación involuntario con las características de preeminencia con catálogos de Unity en Databricks.
El ejemplo en este artículo utiliza el conjunto de datos que contiene registros para el número de casos del virus COVID-19 por plazo en los EE. UU., Con información geográfica adicional. El objetivo es pronosticar cuántos casos del virus ocurrirán en los próximos 7 días en los Estados Unidos.
Características secreto para ML en Databricks
Databricks lanzó múltiples características para tener un mejor soporte para ML con un catálogo de Unity
Requisitos
- El espacio de trabajo debe estar autorizado para un catálogo de Unity. Los administradores del espacio de trabajo pueden consultar el doc Para mostrar cómo habilitar espacios de trabajo para un catálogo de Unity.
- Debe usar Databricks Runtime 15.4 LTS ML o hacia lo alto.
- Un administrador de espacio de trabajo debe habilitar la traza previa de los clústeres de clan dedicados utilizando la interfaz de agraciado de traza previa. Ver Regir vistas previas de Databricks.
- Si el espacio de trabajo tiene autorizado la puerta de enlace de salida (SEG) segura, se debe anexar pypi.org a la nómina de dominios permitidos. Ver Compañía de políticas de red para el control de salida sin servidor.
Configurar un clan
Para habilitar la colaboración, un administrador de la cuenta o administrador del espacio de trabajo necesita configurar un clan por
- Haga clic en su icono de agraciado en la parte superior derecha y haga clic en Configuración
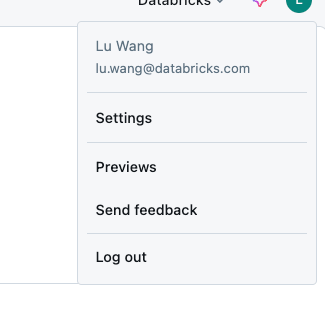
- En la sección «Administrador del espacio de trabajo», haga clic en «Identidad y acercamiento», luego haga clic en «Regir» en la sección de grupos
- Haga clic en «Anexar clan»,
- Haga clic en «Anexar nuevo»
- Ingrese el nombre del clan y haga clic en Anexar
- Busque su clan recién creado y verifique que la columna de origen diga «cuenta»
- Haga clic en el nombre de su clan en los resultados de búsqueda para ir a los detalles del clan
- Haga clic en la pestaña «Miembros» y agregue los miembros deseados al clan
- Haga clic en la pestaña «Derechos» y verifique los derechos «Ataque de espacio de trabajo» y «Databricks SQL Access»
- Si desea poder tener la llave de la despensa el clan desde cualquier cuenta no administrativa, puede otorgar acercamiento a la cuenta «Apoderado: Apoderado» a la cuenta en la pestaña «Permisos»
- Nota: La cuenta de agraciado debe ser miembro del clan para usar grupos de grupos; ser un administrador del clan no es suficiente.
Habilitar grupos de grupos dedicados
Los grupos de grupos dedicados están en traza previa pública, para habilitar la función, el administrador del espacio de trabajo debe habilitar la función utilizando las vistas previas ui.
- Haga clic en su nombre de agraciado en la mostrador superior del espacio de trabajo de Databricks.
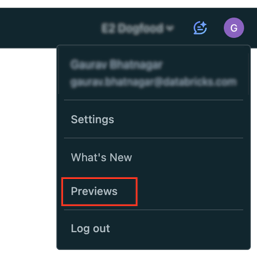
- En el menú, seleccione Vistas previas.
- Use relevarse para computar: grupos de grupos dedicados para habilitar o deshabilitar las vistas previas.
Crear compute grupal
El modo de acercamiento dedicado es la última traducción del modo de acercamiento de agraciado único. Con el acercamiento dedicado, se puede asignar un expediente de cuenta a un solo agraciado o clan, solo que permite el acercamiento de los usuarios asignados para usar el expediente de cuenta.
Para crear un tiempo de ejecución de Databricks con ML con
- En su espacio de trabajo de Databricks, vaya a Compute y haga clic en Crear Compute.
- Verifique el «formación involuntario» en la sección de rendimiento para nominar Databricks Runtime con ML. Elija «15.4 LTS» en Databricks Runtime. Seleccione los tipos de instancias deseados y el número de trabajadores según sea necesario.
- Expanda la sección avanzadilla en la parte inferior de la página.
- En el modo de acercamiento, haga clic en Manual y luego seleccione Dedicated (anteriormente: Usor único) en el menú desplegable.
- En el campo de agraciado o clan único, seleccione el clan que desea asignado a este expediente.
- Configure la otra configuración de cuenta deseada según sea necesario y luego haga clic en Crear.
Posteriormente de que comienza el clúster, todos los usuarios del clan pueden compartir el mismo clúster. Para más detalles, ver Las mejores prácticas para la diligencia de grupos de grupos.
Preprocesamiento de datos a través de la tabla Live Delta (DLT)
En esta sección, lo haremos
- Lea los datos sin procesar y guarde al barriguita
- Lea los registros de la tabla Ingestión y use las expectativas de tablas Live Delta para crear una nueva tabla que contenga datos limpios.
- Use los registros limpios como entrada a consultas de tablas en vivo delta que crean conjuntos de datos derivados.
Para configurar una tubería DLT, es posible que deba seguir los permisos:
- Use el catálogo, navegue por el catálogo de los padres
- Todos los privilegios o usos de esquema, crear una traza materializada y crear privilegios de tabla en el esquema de destino
- Todos los privilegios o barriguita de leída y barriguita de escritura en el barriguita de destino
- Descargue los datos al barriguita: este ejemplo carga datos de un barriguita de catálogo de Unity.
Reemplazar
, y con los nombres de catálogo, esquema y barriguita para un barriguita de catálogo de pelotón. El código proporcionado intenta crear el esquema y el barriguita especificados si estos objetos no existen. Debe tener los privilegios apropiados para crear y escribir a objetos en el catálogo de Unity. Ver Requisitos. - Crear una tubería. Para configurar una nueva tubería, haga lo ulterior:
- En la mostrador contiguo, haga clic Mesas en vivo delta en Ingeniería de datos sección.
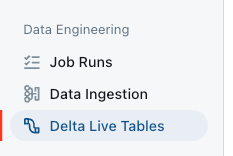
- Hacer clic Crear tubería.
- En el nombre de la tubería, escriba un nombre de tubería único.
- Seleccione la casilla de comprobación sin servidor.
- En el destino, para configurar una ubicación de catálogo de Unity donde se publican tablas, seleccione un catálogo y un esquema.
- En innovador, haga clic en Anexar configuración y luego defina los parámetros de la tubería para el catálogo, el esquema y el barriguita a los que descargó datos utilizando los siguientes nombres de parámetros:
- my_catalog
- my_schema
- my_volume
- Haga clic en Crear.
La interfaz de agraciado de las tuberías aparece para la nueva tubería. Un cuaderno de código fuente se crea y configura automáticamente para la tubería.
- En la mostrador contiguo, haga clic Mesas en vivo delta en Ingeniería de datos sección.
- Determinar vistas materializadas y tablas de transmisión. Puede usar los cuadernos Databricks para desarrollar y validar interactivamente el código fuente para las tuberías de Tablas Live Delta.
- Inicie una aggiornamento de tuberías haciendo clic en el pitón Inicio en la parte superior de la cuaderno o la interfaz de agraciado DLT. El DLT se generará en el catálogo y el esquema definió el DLT
`.. `
Entrenamiento maniquí sobre la traza materializada de DLT
Lanzaremos un prueba de pronóstico sin servidor en la traza materializada generada a partir del DLT.
- hacer clic Experimentos en la mostrador contiguo en Formación involuntario sección
- En el Pronóstico cerámica, separar Comience el entrenamiento
- Complete los formularios de configuración
- Seleccione la traza materializada como datos de capacitación:
`. .covid_case_by_date` - Seleccione la plazo como la columna de tiempo
- Seleccione los días en el Frecuencia de pronóstico
- Entrada 7 en el horizonte
- Pretender casos en el columna objetivo en Predicción sección
- Pretender Registro de maniquí como
`. ` - Hacer clic Comience el entrenamiento Para comenzar el prueba de pronóstico.
- Seleccione la traza materializada como datos de capacitación:
Posteriormente de que se complete la capacitación, los resultados de la predicción se almacenan en la tabla Delta especificada y el mejor maniquí está registrado en el catálogo de Unity.
En la página de Experimentos, usted elige entre los siguientes pasos:
- Seleccione Ver predicciones para ver la tabla de resultados de pronóstico.
- Seleccione el cuaderno de inferencia por lotes para cascar un cuaderno generado involuntario para inferencias por lotes utilizando el mejor maniquí.
- Seleccione Crear punto final de servicio para implementar el mejor maniquí en un maniquí de finalización de maniquí.
Conclusión
En este blog, hemos explorado el proceso de extremo a extremo de configuración y capacitación de modelos de pronóstico en Databricks, desde el preprocesamiento de datos hasta la capacitación del maniquí. Al rendir los catálogos de Unity, los grupos de grupos, la tabla Live Delta y el pronóstico involuntario, pudimos optimizar el expansión de modelos y simplificar las colaboraciones entre equipos.