
FineWeb2 avanza significativamente los conjuntos de datos de preentrenamiento multilingües, cubriendo más de 1000 idiomas con datos de adhesión calidad. El conjunto de datos utiliza aproximadamente 8 terabytes de datos de texto comprimido y contiene casi 3 billones de palabras, obtenidas de 96 instantáneas de CommonCrawl entre 2013 y 2024. Procesado utilizando la biblioteca datatrove, FineWeb2 demuestra un rendimiento superior en comparación con conjuntos de datos establecidos como CC-100, mC4, CulturaX, y HPLT en nueve idiomas diferentes. La configuración de extirpación y evaluación está presente en este repositorio de github.
Los investigadores de la comunidad de Huggingface presentaron FineWeb-C, un tesina colaborativo impulsado por la comunidad que amplía FineWeb2 para crear anotaciones de contenido educativo de adhesión calidad en cientos de idiomas. El tesina permite a los miembros de la comunidad adscribir el valencia educativo del contenido web e identificar nociones problemáticos a través de la plataforma Argilla. Los idiomas que alcanzan 1000 anotaciones califican para la inclusión en el conjunto de datos. Este proceso de anotación tiene un doble propósito: identificar contenido educativo de adhesión calidad y mejorar el exposición de LLM en todos los idiomas.

318 miembros de la comunidad Hugging Face han enviado 32,863 anotaciones, contribuyendo al exposición de LLM de adhesión calidad en idiomas subrepresentados. FineWeb-Edu es un conjunto de datos creado a partir del conjunto de datos FineWeb diferente y emplea un clasificador de calidad educativa entrenado en anotaciones LLama3-70B-Instruct para identificar y retener la decano parte del contenido educativo. Este enfoque ha demostrado ser exitoso, superando a FineWeb en puntos de narración populares y al mismo tiempo reduciendo el convexidad de datos necesario para capacitar LLM efectivos. El tesina tiene como objetivo ampliar las capacidades de FineWeb-Edu a todos los idiomas del mundo mediante la resumen de anotaciones comunitarias para capacitar a clasificadores de calidad educativa específicos de cada idioma.
El tesina prioriza las anotaciones generadas por humanos sobre las basadas en LLM, particularmente para lenguajes de bajos posibles donde el desempeño de LLM no se puede validar de modo confiable. Este enfoque impulsado por la comunidad es paralelo al maniquí colaborativo de Wikipedia, que enfatiza el comunicación amplio y la democratización de la tecnología de inteligencia fabricado. Los contribuyentes se unen a un movimiento más amplio para romper las barreras lingüísticas en el exposición de la IA, ya que las empresas comerciales suelen centrarse en idiomas rentables. La naturaleza abierta del conjunto de datos permite a cualquiera crear sistemas de IA adaptados a las deposición específicas de la comunidad, al tiempo que facilita el formación sobre enfoques eficaces en diferentes idiomas.
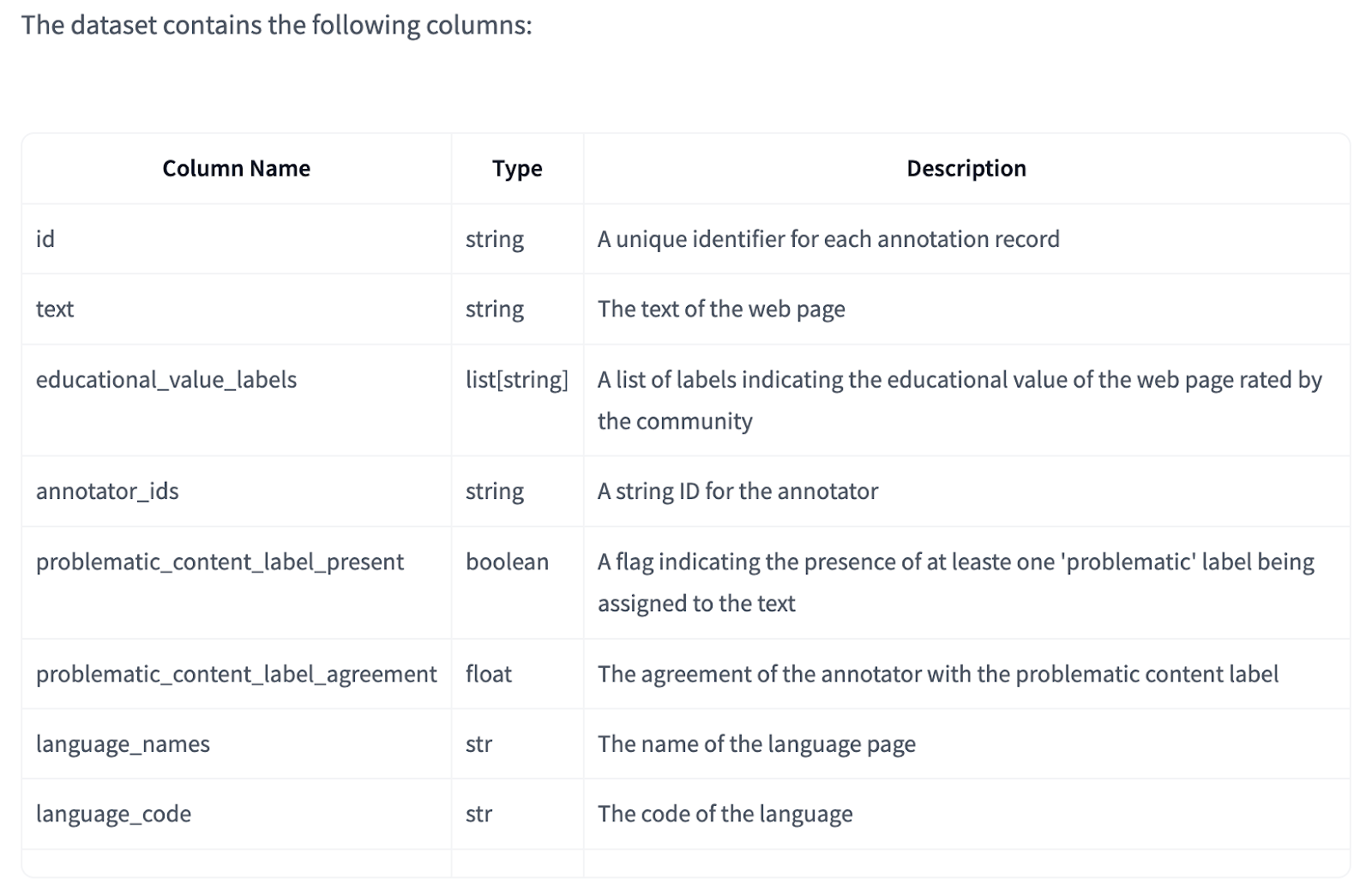
FineWeb-Edu utiliza múltiples anotaciones por página para algunos idiomas, lo que permite un cálculo flexible del acuerdo del anotador. Las medidas de control de calidad incluyen planes para aumentar la superposición de anotaciones en idiomas con muchas anotaciones. Los datos contienen una columna booleana ‘problematic_content_label_present’ para identificar páginas con indicadores de contenido problemáticos, que a menudo resultan de una detección de idioma incorrecta. Los usuarios pueden filtrar contenido basándose en etiquetas problemáticas individuales o en el acuerdo del anotador a través de la columna ‘problematic_content_label_agreement’. El conjunto de datos opera bajo la abuso ODC-By v1.0 y los Términos de uso de CommonCrawl.
En conclusión, la extensión impulsada por la comunidad de FineWeb2, FineWeb-C, ha recopilado 32.863 anotaciones de 318 contribuyentes, centrándose en el etiquetado de contenido educativo. El tesina demuestra un rendimiento superior en comparación con los conjuntos de datos existentes con menos datos de entrenamiento a través del clasificador de contenido educativo especializado de FineWeb-Edu. A diferencia de los enfoques comerciales, esta iniciativa de código amplio prioriza las anotaciones humanas sobre las basadas en LLM, particularmente para lenguajes de bajos posibles. El conjunto de datos presenta sólidas medidas de control de calidad, incluidas múltiples capas de anotaciones y filtrado de contenido problemático, mientras opera bajo la abuso ODC-By v1.0.
Probar el detalles. Todo el crédito por esta investigación va a los investigadores de este tesina. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. No olvides unirte a nuestro SubReddit de más de 60.000 ml.

Sajjad Ansari es un estudiante de postrer año de IIT Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA centrándose en comprender el impacto de las tecnologías de IA y sus implicaciones en el mundo auténtico. Su objetivo es articular conceptos complejos de IA de una modo clara y accesible.