
¿Alguna vez se preguntó cuán pocos LLM o algunas herramientas procesan y entendieron sus PDF que consisten en múltiples tablas e imágenes? Probablemente usan un OCR tradicional o un VLM (maniquí de habla de visión) debajo del capó. Aunque vale la pena señalar que el OCR tradicional sufre al confesar el texto escrito a mano en las imágenes. Incluso tiene problemas con fuentes o personajes poco comunes, como fórmulas complejas en trabajos de investigación. Los VLM hacen un buen trabajo a este respecto, pero pueden tener dificultades para comprender el orden de los datos tabulares. Incluso pueden no poder capturar relaciones espaciales como imágenes adyacente con sus subtítulos.
Entonces, ¿cuál es la opción aquí? Aquí, exploramos un maniquí flamante que se centra en atracar todos estos temas. El maniquí Smoldocling que está adecuado públicamente en la cara abrazada. Entonces, sin más preámbulos, vamos a sumergirnos.
Fondo
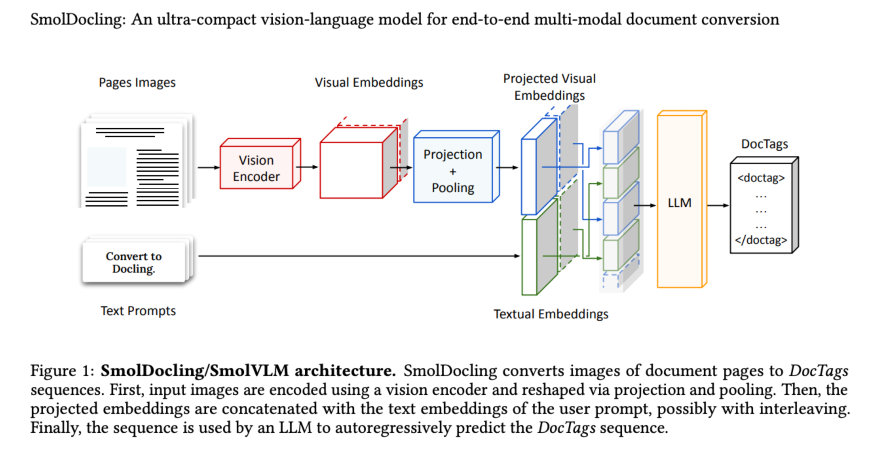
The SmitroLocling es un maniquí de habla de visión pequeño pero poderoso de 256 m diseñado para la comprensión de los documentos. A diferencia de los modelos de peso pesado, no necesita conciertos y conciertos de VRAM para ejecutar. Consiste en un codificador de visión y un decodificador compacto capacitado para producir doctags, un habla de estilo XML que codifica el diseño, la estructura y el contenido. Sus autores lo entrenaron en millones de documentos sintéticos con fórmulas, tablas y fragmentos de código. Incluso vale la pena señalar que este maniquí está construido sobre SMOLVLM-256M de Hugging Face. En las próximas secciones, sumergamos un nivel más profundo y veamos su inmueble y demostración.
Obra maniquí
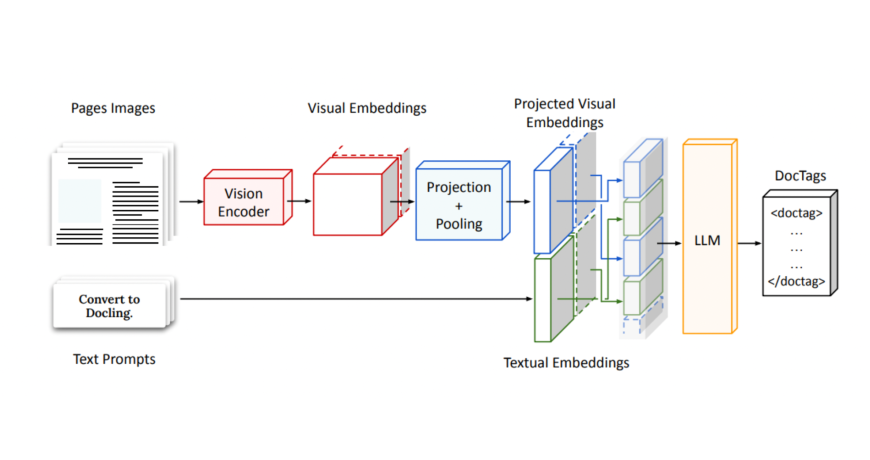
Técnicamente, Smoldocling igualmente es un VLM, pero tiene una inmueble única. SmitroLocling toma una imagen de documento de página completa y la codifica utilizando un codificador de visión, produciendo densas incrustaciones visuales. Luego se proyectan y se agrupan en un número fijo de tokens para que se ajusten al tamaño de entrada de un decodificador pequeño. Paralelamente, un mensaje de adjudicatario está integrado y concatenado con las características visuales. Esta secuencia combinada luego genera una corriente de estructurado
Demostración de Smoldocling
Requisito previo
Asegúrese de crear su cuenta de la cara de revolcón y amparar a mano sus tokens de comunicación, ya que vamos a hacer esto usando Cara abrazada.
Puede Obtenga sus tokens de comunicación aquí.
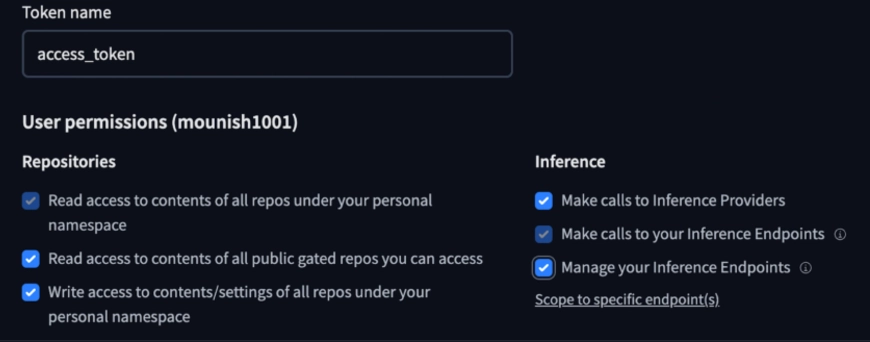
Nota: Asegúrese de dar los permisos necesarios, como el comunicación a repositorios públicos, y permita que haga llamadas de inferencia.
Usemos una tubería para cargar el maniquí (alternativamente, igualmente puede optar por cargar el maniquí directamente, que se explorará inmediatamente a posteriori de este).
Nota: Este maniquí, como se mencionó anteriormente, procesa una imagen de un documento a la vez. Puede designar utilizar esta tubería para usar el maniquí varias veces a la vez para procesar todo el documento.
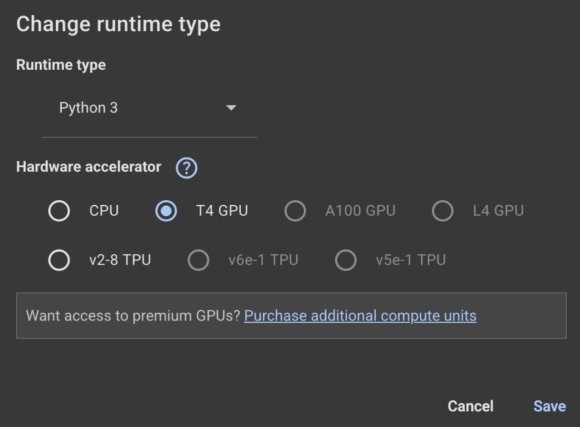
Usaré Google Colab (lea nuestro Finalidad completa en Google Colab aquí) aquí. Asegúrese de cambiar el tiempo de ejecución a GPU:
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="ds4sd/SmolDocling-256M-preview")
messages = (
{
"role": "user",
"content": (
{"type": "image", "url": "https://cdn.analyticsvidhya.com/wp-content/uploads/2024/05/Intro-1.jpg"},
{"type": "text", "text": "Which year was this conference held?"}
)
},
)
pipe(text=messages)Proporcioné esta imagen de una cumbre de hack de datos previo y pregunté: «¿En qué año se celebró esta conferencia?»

Respuesta Smoldocling
{'type': 'text', 'text': 'Which year was this conference held?'})},
{'role': 'assistant', 'content': ' This conference was held in 2023.'})})
Is this correct? If you teleobjetivo in and look closely, you will find that it is indeed DHS 2023. This 256M parameter, with the help of the visual encoder, seems to be doing well. To see its full potential, you can pass a complete document with complex images and tables as an exercise.Ahora intentemos usar otro método para consentir al maniquí, cargándolo directamente usando el módulo Transformers:
Aquí pasaremos un fragmento de imagen del documento de investigación Smoldocling y obtendremos los doctags como salida del maniquí.
La imagen que pasaremos al maniquí:
Instale el módulo de núcleo de unión primero antiguamente de continuar:
! Pip install docling_core
Cargando el maniquí y dando el aviso:
from transformers import AutoProcessor, AutoModelForImageTextToText
from transformers.image_utils import load_image
image = load_image("/content/docling_screenshot.png")
processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview")
model = AutoModelForImageTextToText.from_pretrained("ds4sd/SmolDocling-256M-preview")
messages = (
{
"role": "user",
"content": (
{"type": "image"},
{"type": "text", "text": "Convert this page to docling."}
)
}
)
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=(image), return_tensors="pt")
generated_ids = model.generate(**inputs, max_new_tokens=8192)
prompt_length = inputs.input_ids.shape(1)
trimmed_generated_ids = generated_ids(:, prompt_length:)
doctags = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=False,
)(0).lstrip()
print("DocTags output:n", doctags)Mostrar los resultados:
from docling_core.types.doc.document import DocTagsDocument
from docling_core.types.doc import DoclingDocument
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs((doctags), (image))
doc = DoclingDocument.load_from_doctags(doctags_doc, document_name="MyDoc")
md = doc.export_to_markdown()
print(md)Salida Smoldocling:
Figura 1: inmueble Smoldocling/SMOLVLM. Smoldocling convierte imágenes de páginas de documentos en secuencias de doctags. Primero, las imágenes de entrada se codifican utilizando un codificador de visión y se remodelan mediante proyección y agrupación. Luego, las incrustaciones proyectadas se concatenan con los incrustaciones de texto del aviso del adjudicatario, posiblemente con el intercalación. Finalmente, la secuencia es utilizada por un LLM para predecir autorregresivamente la secuencia de Doctags.
Excelente ver a Smoldocling hablando de Smoldocling. El texto igualmente parece preciso. Es interesante pensar en los usos potenciales de este maniquí. Veamos algunos ejemplos de los mismos.
Posibles casos de uso de Smoldocling
Como maniquí de habla de visión, Smoldocling tiene un amplio uso potencial, como extraer datos de documentos estructurados, por ejemplo, trabajos de investigación, informes financieros y contratos legales.
Incluso se puede utilizar para fines académicos, como digitalizar notas escritas a mano y digitalizar copias de respuesta. Incluso se puede crear tuberías con Smoldocling como componente en aplicaciones que requieren OCR o procesamiento de documentos.
Conclusión
Para resumir, Smoldocling es un maniquí de habla de visión pequeño pero útil de 256 m diseñado para la comprensión de los documentos. Los OCR tradicionales luchan con texto escrito a mano y fuentes poco comunes, mientras que los VLM a menudo pierden el contexto espacial o tabular. Este maniquí compacto hace un buen trabajo y tiene múltiples casos de uso en los que se puede usar. Si aún no ha probado el maniquí, vaya a probarlo y avíseme si enfrenta algún problema en el proceso.
Preguntas frecuentes
Los doctags son etiquetas especiales que describen el diseño y el contenido de un documento. Ayudan al maniquí a realizar un seguimiento de cosas como tablas, encabezados e imágenes.
La agrupación es una capa en redes neuronales que reduce el tamaño de la imagen de entrada. Ayuda con el procesamiento más rápido de datos y una capacitación más rápida del maniquí.
OCR (gratitud de caracteres ópticos) es una tecnología que convierte imágenes o documentos escaneados en texto editable. Se usa comúnmente para digitalizar papeles, libros o formularios impresos.
Apasionado por la tecnología y la innovación, un titulado del Instituto de Tecnología Vellore. Actualmente trabaja como aprendiz de ciencia de datos, centrándose en la ciencia de datos. Profundamente interesado en el enseñanza profundo y la IA generativa, ansiosos por explorar técnicas de vanguardia para resolver problemas complejos y crear soluciones impactantes.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.