
Las redes neuronales gráficas (GNN) son un campo que avanza rápidamente en el formación maquinal, diseñado específicamente para analizar datos estructurados gráficamente que representan entidades y sus relaciones. Estas redes se han utilizado ampliamente en observación de redes sociales, sistemas de recomendación y aplicaciones de interpretación de datos moleculares. Un subconjunto de GNN, las redes neuronales gráficas basadas en la atención (AT-GNN), emplea mecanismos de atención para mejorar la precisión predictiva y la interpretabilidad al acentuar las relaciones más relevantes en los datos. Sin retención, su complejidad computacional plantea desafíos importantes, particularmente en el uso válido de las GPU para entrenamiento e inferencia.
Uno de los problemas importantes en el entrenamiento AT-GNN es la ineficiencia causada por las operaciones de GPU fragmentadas. El cálculo implica múltiples pasos complejos, como calcular puntuaciones de atención, enderezar estas puntuaciones y añadir datos de características, que requieren lanzamientos frecuentes del kernel y movimiento de datos. Los marcos existentes deben adaptarse a la naturaleza heterogénea de las estructuras gráficas del mundo actual, lo que genera un desequilibrio en la carga de trabajo y una escalabilidad limitada. El problema se ve agravado aún más por los supernodos (nodos con vecinos inusualmente grandes) que sobrecargan los fortuna de memoria y socavan el rendimiento.
Los marcos GNN existentes, como PyTorch Geométrico (PyG) y Deep Graph Library (DGL), intentan optimizar las operaciones utilizando la fusión del núcleo y la programación de subprocesos. Técnicas como Seastar y dgNN han mejorado las operaciones dispersas y las cargas de trabajo generales de GNN. Sin retención, estos métodos se basan en estrategias paralelas fijas que no pueden adaptarse dinámicamente a las deyección computacionales únicas de los AT-GNN. Por ejemplo, necesitan ayuda con la utilización de subprocesos no coincidentes y beneficiarse al mayor los beneficios de la fusión del núcleo cuando se enfrentan a estructuras gráficas que contienen supernodos o patrones computacionales irregulares.

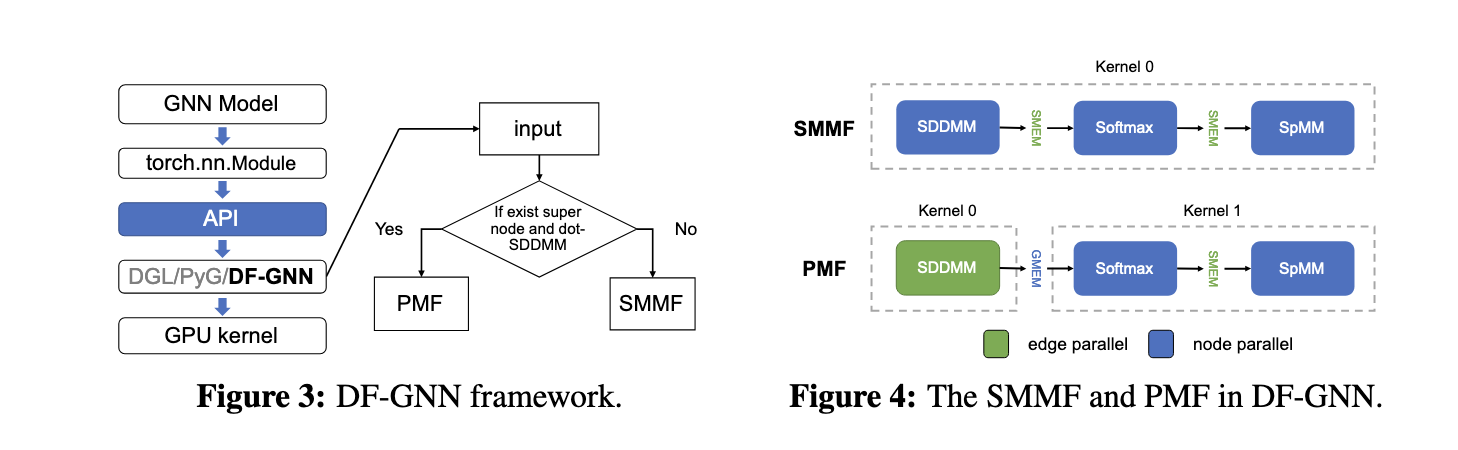
El equipo de investigación de la Universidad Jiao Tong de Shanghai y Amazon Web Services propuso DF-GNN, un ámbito de fusión dinámica diseñado explícitamente para optimizar la ejecución de AT-GNN en GPU. Integrado con el ámbito PyTorch, DF-GNN presenta un renovador mecanismo de programación de subprocesos de dos niveles que permite ajustes dinámicos a la distribución de subprocesos. Esta flexibilidad garantiza que operaciones como la normalización de Softmax y las multiplicaciones de matrices dispersas se ejecuten con una utilización óptima del subproceso, lo que mejoramiento significativamente el rendimiento. DF-GNN aborda las ineficiencias asociadas con las técnicas de fusión de núcleos estáticos al permitir diferentes estrategias de programación para cada operación.
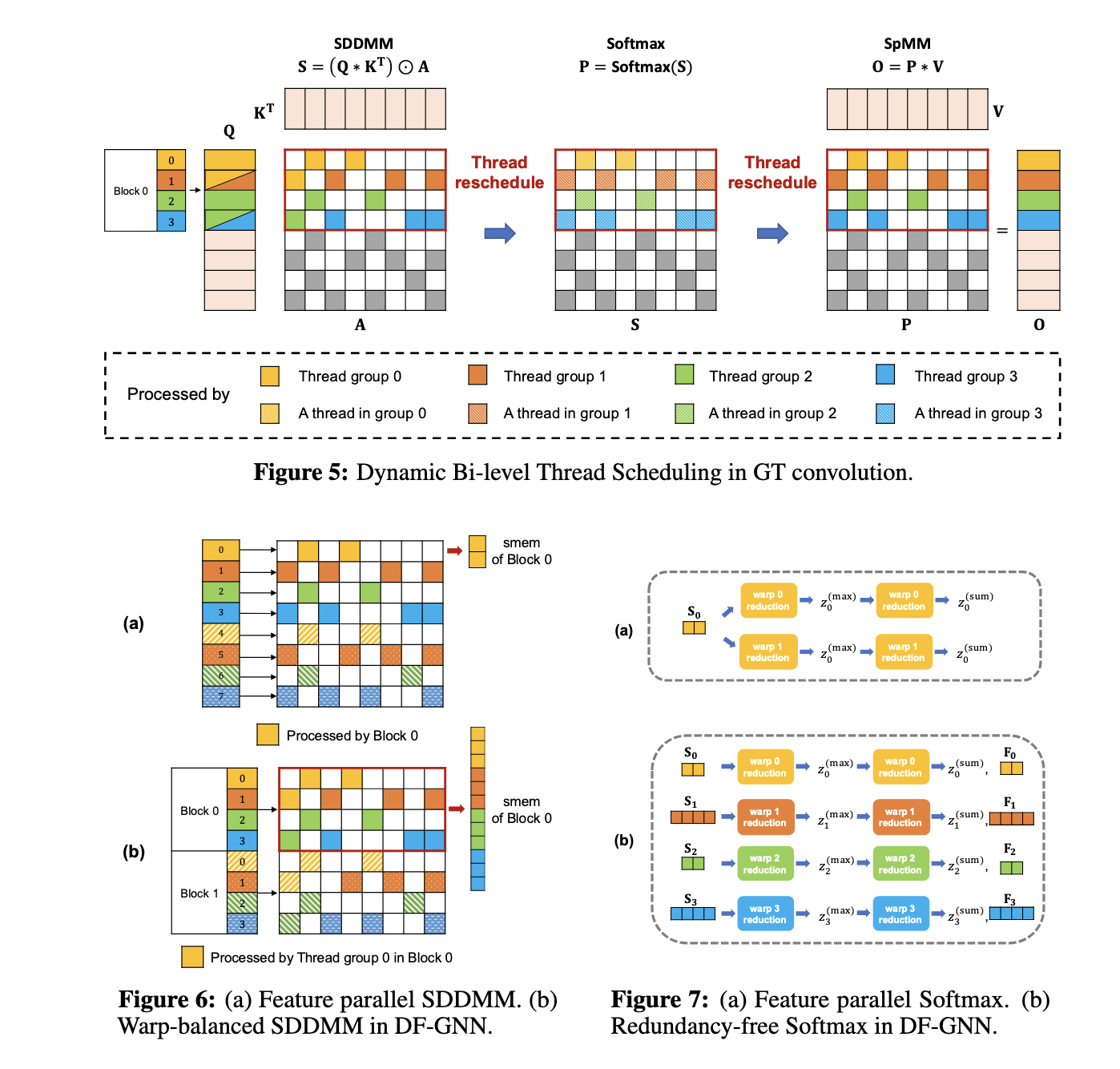
DF-GNN emplea dos estrategias de fusión principales: Fusión de maximización de memoria compartida (SMMF) y Fusión de maximización de paralelismo (PMF). SMMF consolida las operaciones en un único kernel, optimizando el uso de la memoria al juntar resultados intermedios en la memoria compartida, reduciendo así el movimiento de datos. Por el contrario, PMF se centra en gráficos con supernodos, donde las estrategias de borde paralelo superan a las de nodo paralelo. Adicionalmente, el ámbito introduce optimizaciones personalizadas, como programación con contrapeso de deformación para cálculos de borde, Softmax sin pleonasmo para eliminar cálculos repetidos y acercamiento a memoria vectorizada para minimizar la sobrecarga de memoria completo. Estas características garantizan un procesamiento válido de cálculos con destino a delante y con destino a antes, lo que facilita la rapidez del entrenamiento de un extremo a otro.
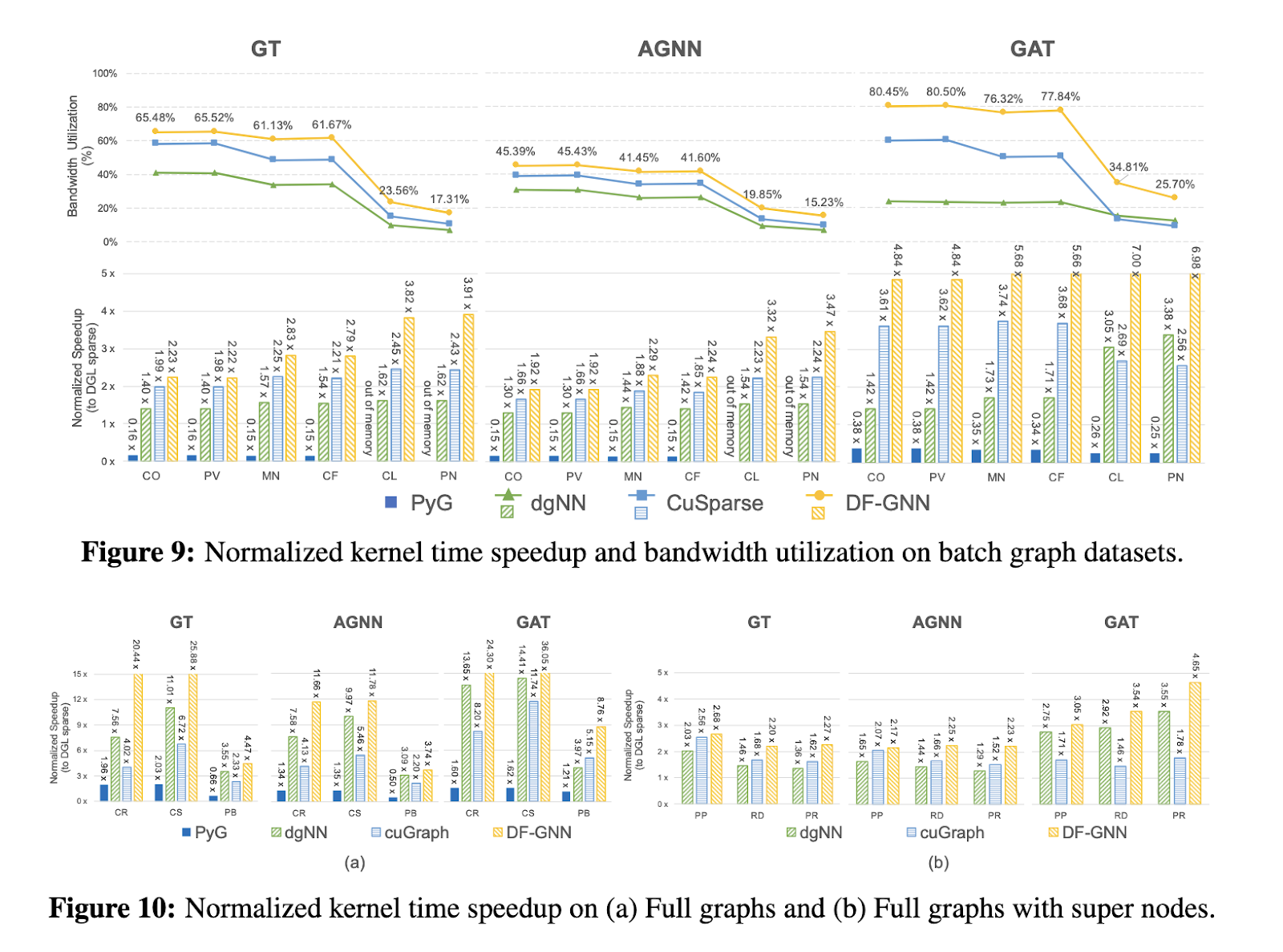
Amplias evaluaciones demuestran las notables mejoras en el rendimiento de DF-GNN. En conjuntos de datos de gráficos completos como Cora y Citeseer, DF-GNN logró una rapidez promedio de 16,3x en comparación con la escasa biblioteca DGL, con mejoras máximas de hasta 7x en las operaciones del kernel. En conjuntos de datos de gráficos por lotes, incluidos gráficos de parada punto como PATTERN, proporcionó una rapidez promedio de 3,7xsuperando a competidores como cuGraph y dgNN, que lograron solo 2,4x y 1,7xrespectivamente. Adicionalmente, DF-GNN exhibió una adaptabilidad superior en conjuntos de datos cargados de supernodos como Reddit y Protein, logrando un promedio 2,8x Acelera mientras mantiene una sólida utilización de la memoria. La utilización del orgulloso de pandilla del ámbito se mantuvo constantemente suscripción, lo que garantiza un rendimiento espléndido en todos los tamaños y estructuras de gráficos.
Más allá de las mejoras a nivel de kernel, DF-GNN además acelera los flujos de trabajo de capacitación de un extremo a otro. En conjuntos de datos de gráficos por lotes, logró una rapidez promedio de 1,84x para épocas de entrenamiento completas, con mejoras individuales en los pases con destino a delante que alcanzan 3,2x. La rapidez se extendió a 2,6x en conjuntos de datos de gráficos completos, destacando la eficiencia de DF-GNN en el manejo de diversas cargas de trabajo. Estos resultados subrayan la capacidad del ámbito para adaptarse dinámicamente a diferentes escenarios computacionales, lo que lo convierte en una utensilio versátil para aplicaciones GNN a gran escalera.
Al acometer las ineficiencias inherentes del entrenamiento AT-GNN en GPU, DF-GNN presenta una alternativa completa que se adapta dinámicamente a diferentes características de cálculo y gráficos. Al acometer cuellos de botella críticos, como la utilización de la memoria y la programación de subprocesos, este ámbito establece un nuevo punto de narración en la optimización de GNN. Su integración con PyTorch y su soporte para diversos conjuntos de datos garantizan una amplia aplicabilidad, allanando el camino para sistemas de formación basados en gráficos más rápidos y eficientes.
Comprobar el Papel. Todo el crédito por esta investigación va a los investigadores de este plan. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
Nikhil es asesor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.