
La navegación por visión y lengua (VLN) combina la percepción visual con la comprensión del lengua natural para indicar a los agentes a través de entornos 3D. El objetivo es permitir que los agentes sigan instrucciones similares a las humanas y naveguen por espacios complejos de forma eficaz. Estos avances tienen potencial en la robótica, la efectividad aumentada y las tecnologías de asistentes inteligentes, donde las instrucciones lingüísticas guían la interacción con los espacios físicos.
El problema central en la investigación de VLN es la error de conjuntos de datos anotados de ingreso calidad que combinen trayectorias de navegación con instrucciones precisas en lengua natural. Anotar estos conjuntos de datos manualmente requiere importantes posibles, experiencia y esfuerzo, lo que hace que el proceso sea costoso y requiera mucho tiempo. Encima, estas anotaciones a menudo no proporcionan la riqueza filología y la fidelidad necesarias para universalizar los modelos en diversos entornos, lo que limita su aptitud en aplicaciones del mundo existente.
Las soluciones existentes se basan en la procreación de datos sintéticos y el aumento del entorno. Los datos sintéticos se generan utilizando modelos de trayectoria a instrucción, mientras que los simuladores diversifican los entornos. Sin incautación, estos métodos a menudo deben mejorar la calidad, lo que produce datos mal alineados entre el idioma y las trayectorias de navegación. Esta desalineación da como resultado un rendimiento subóptimo del agente. El problema se ve agravado aún más por las métricas que evalúan inadecuadamente la línea semántica y direccional de las instrucciones con sus trayectorias correspondientes, desafiando así el control de calidad.
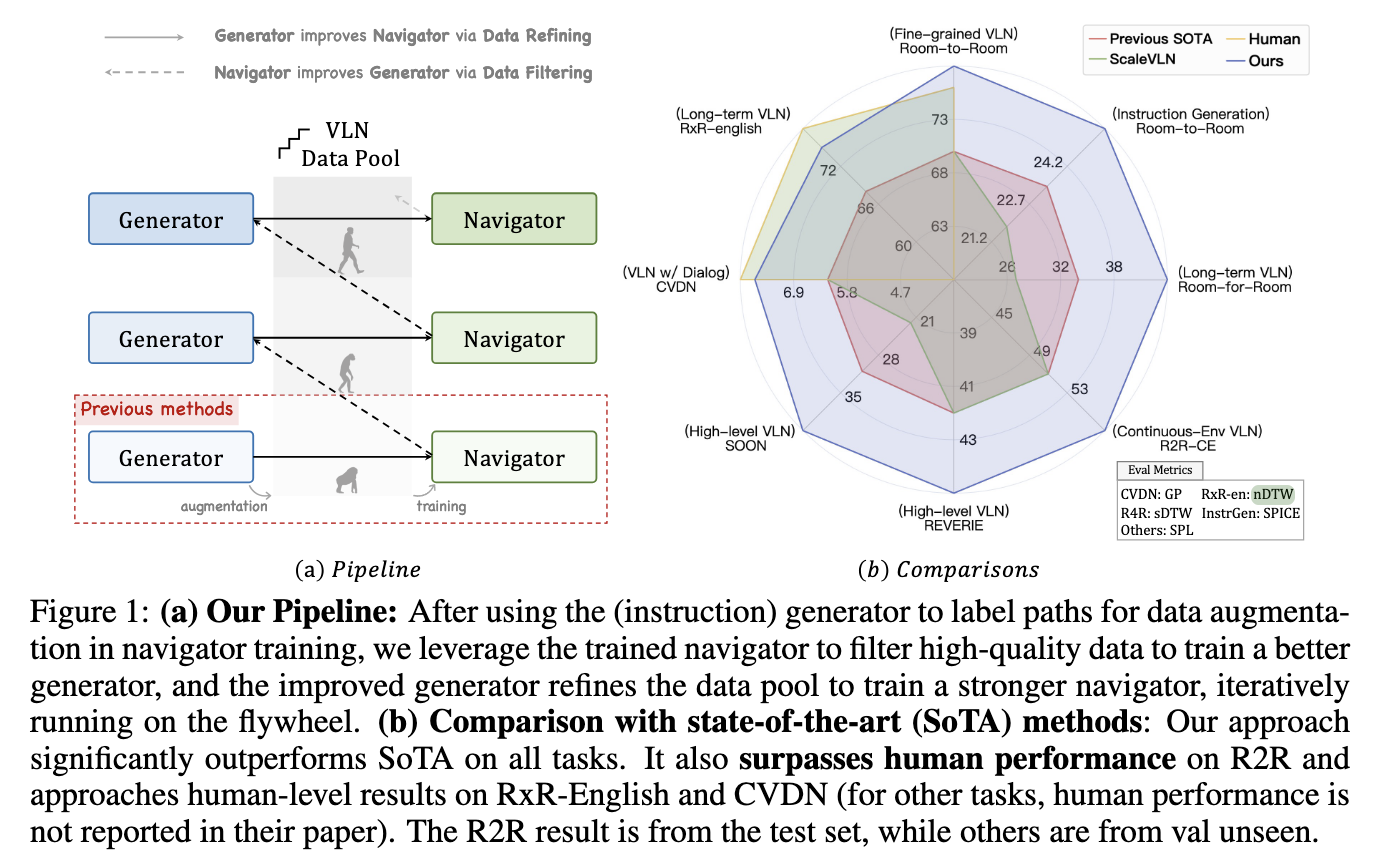
Investigadores del Laboratorio de IA de Shanghai, la UNC Chapel Hill, Adobe Research y la Universidad de Nanjing propusieron el Self-Refining Data Flywheel (SRDF), un sistema diseñado para mejorar iterativamente tanto el conjunto de datos como los modelos mediante la colaboración mutua entre un dinamo de instrucciones y un navegador. Este método totalmente automatizado elimina la carencia de anotaciones realizadas por una persona. A partir de un pequeño conjunto de datos de ingreso calidad anotados por humanos, el sistema SRDF genera instrucciones sintéticas y las utiliza para entrenar a un navegador saco. Luego, el navegador evalúa la fidelidad de estas instrucciones y filtra los datos de desvaloración calidad para entrenar un mejor dinamo en iteraciones posteriores. Este refinamiento iterativo garantiza una prosperidad continua tanto en la calidad de los datos como en el rendimiento de los modelos.
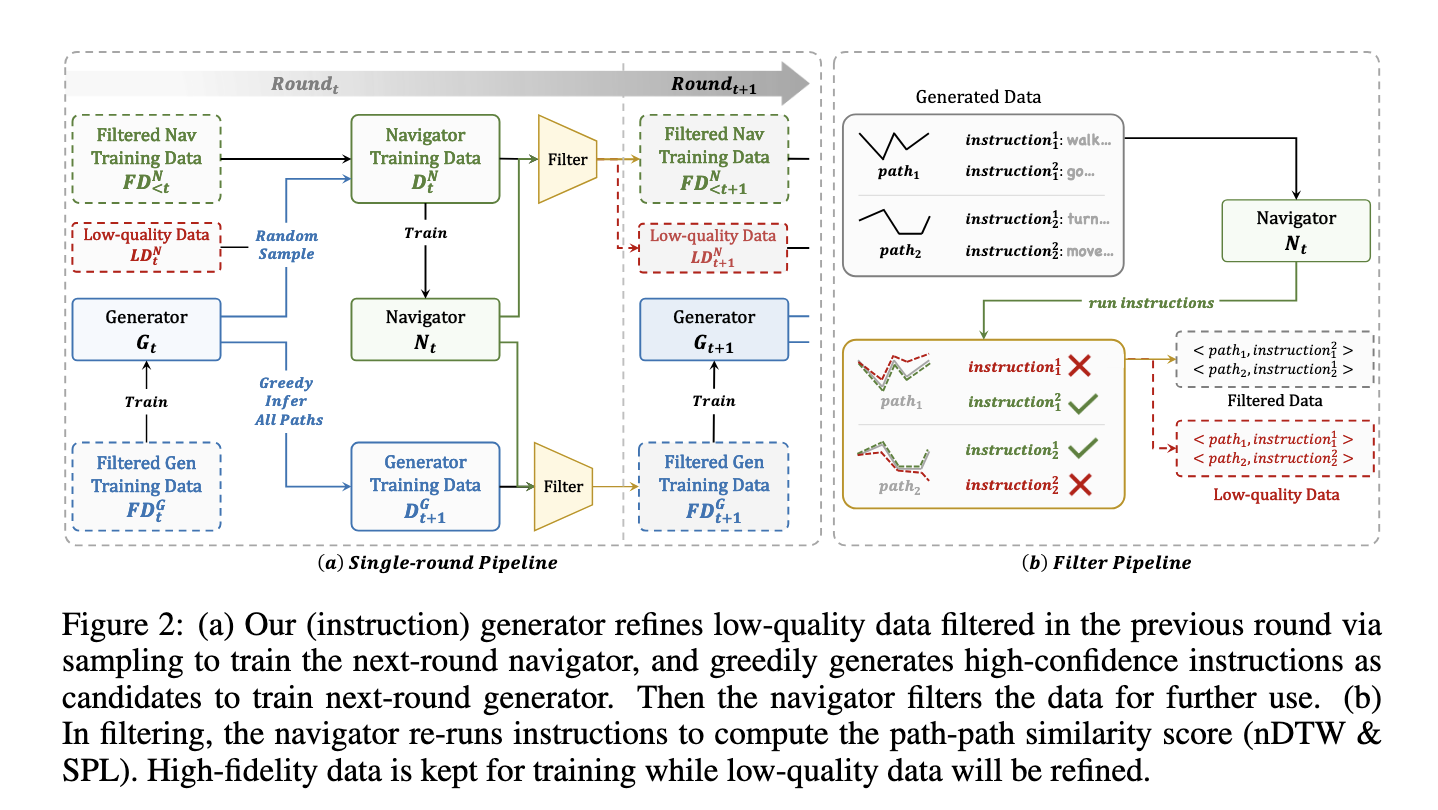
El sistema SRDF consta de dos componentes esencia: un dinamo de instrucciones y un navegador. El dinamo crea instrucciones de navegación sintéticas a partir de trayectorias utilizando modelos de lengua multimodal avanzados. El navegador, a su vez, evalúa estas instrucciones midiendo con qué precisión puede seguir las rutas generadas. Los datos de ingreso calidad se identifican en función de estrictas métricas de fidelidad, como el éxito ponderado por la distancia de la ruta (SPL) y la distorsión dinámica del tiempo normalizada (nDTW). Los datos de mala calidad se regeneran o se excluyen, lo que garantiza que solo se utilicen datos confiables y enormemente alineados para la capacitación. A lo espacioso de tres iteraciones, el sistema refina el conjunto de datos, que en última instancia contiene 20 millones de pares de trayectorias de instrucciones de ingreso fidelidad que abarcan 860 entornos diversos.
El sistema SRDF demostró mejoras de rendimiento excepcionales en varias métricas y puntos de relato. En el conjunto de datos Room-to-Room (R2R), la métrica SPL para el navegador aumentó del 70% a un 78% sin precedentes, superando el punto de relato humano del 76%. Este es el primer caso en el que un agente VLN supera la precisión de navegación a nivel humano. El dinamo de instrucciones igualmente logró resultados impresionantes, con puntuaciones SPICE que aumentaron de 23,5 a 26,2, superando todos los métodos anteriores de procreación de instrucciones de navegación por visión y lengua. Encima, los datos generados por SRDF facilitaron una extensión superior en las tareas posteriores, incluida la navegación a espacioso plazo (R4R) y la navegación basada en diálogo (CVDN), logrando un rendimiento de vanguardia en todos los conjuntos de datos probados.
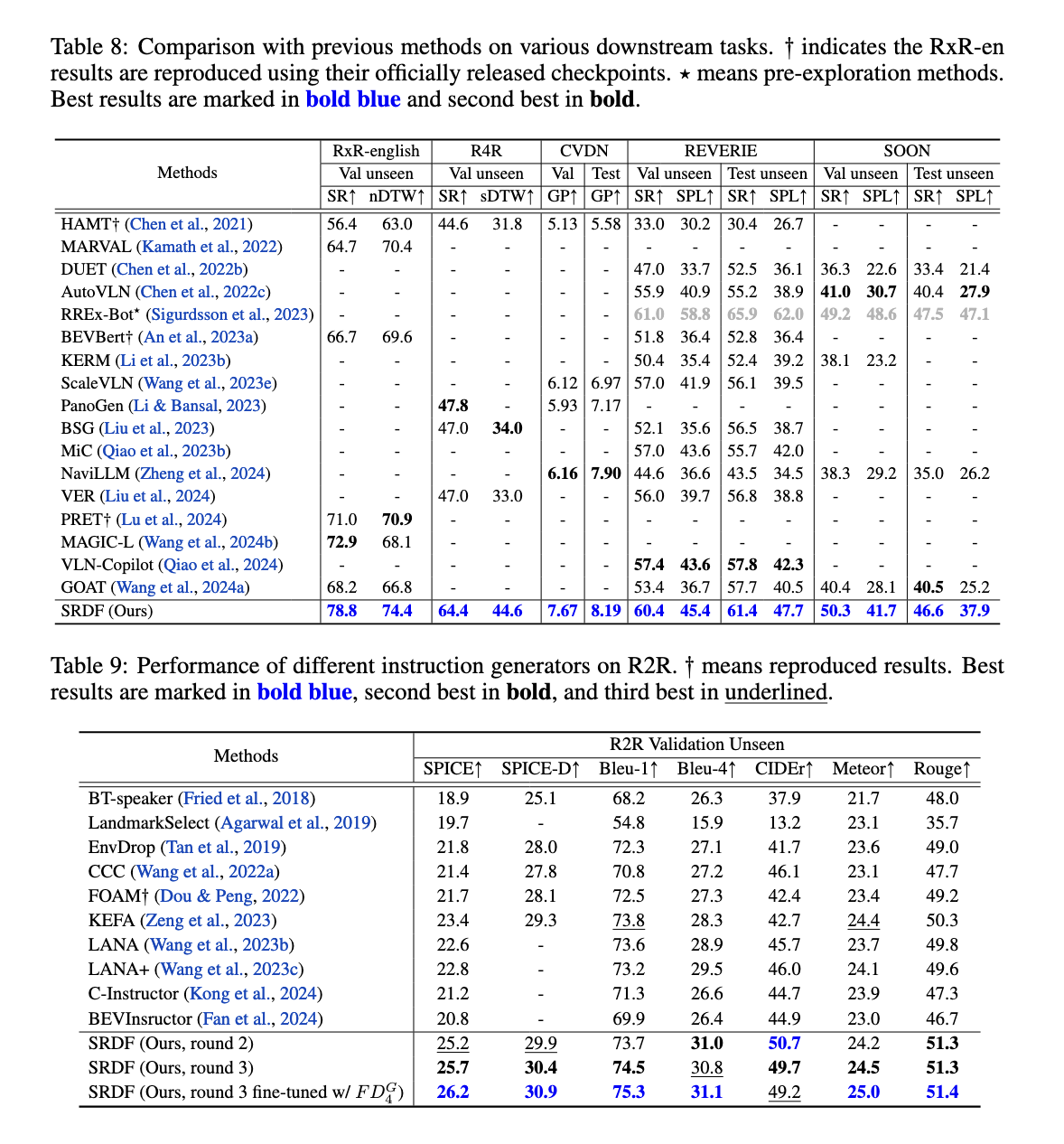
Específicamente, el sistema destacó en la navegación de espacioso horizonte, logrando una prosperidad del 16,6 % en la tasa de éxito en el conjunto de datos R4R. El conjunto de datos CVDN mejoró significativamente la métrica de Progreso del objetivo, superando a todos los modelos anteriores. Encima, la escalabilidad de SRDF fue evidente a medida que el dinamo de instrucciones mejoró constantemente con conjuntos de datos más grandes y entornos diversos, lo que garantizó un rendimiento sólido en diversas tareas y puntos de relato. Los investigadores igualmente informaron una decano pluralidad y riqueza de la instrucción, con más de 10,000 palabras únicas incorporadas en el conjunto de datos generado por SRDF, abordando las limitaciones de vocabulario de los conjuntos de datos anteriores.
El enfoque SRDF aborda el desafío de larga data de la escasez de datos en VLN mediante la automatización del refinamiento del conjunto de datos. La colaboración iterativa entre el navegador y el dinamo de instrucciones garantiza la prosperidad continua de uno y otro componentes, lo que genera conjuntos de datos enormemente alineados y de ingreso calidad. Este método renovador ha establecido un nuevo estereotipado en la investigación de VLN, mostrando el papel fundamental de la calidad y la línea de los datos en el avance de la IA incorporada. Con su capacidad para aventajar el desempeño humano y generalizarse en diversas tareas, SRDF está preparado para impulsar un progreso significativo en el crecimiento de sistemas de navegación inteligentes.
Compulsar el Papel y Página de GitHub. Todo el crédito por esta investigación va a los investigadores de este plan. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. No olvides unirte a nuestro SubReddit de más de 60.000 ml.
Nikhil es consejero interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.