
Los modelos de idiomas grandes (LLM) dependen de las técnicas de enseñanza de refuerzo para mejorar las capacidades de engendramiento de respuesta. Un aspecto crítico de su progreso es el modelado de recompensas, que ayuda a capacitar a los modelos para alinearse mejor con las expectativas humanas. Los modelos de recompensas evalúan las respuestas basadas en las preferencias humanas, pero los enfoques existentes a menudo sufren subjetividad y limitaciones en la corrección de objetivos. Esto puede conducir a un rendimiento subóptimo, ya que los modelos pueden priorizar la fluidez sobre la precisión. Mejorar el modelado de recompensas con señales de corrección verificables puede ayudar a mejorar la confiabilidad de los LLM en aplicaciones del mundo positivo.
Un desafío importante en los sistemas de modelado de recompensas actuales es su gran dependencia de las preferencias humanas, que son inherentemente subjetivas y propensas a los prejuicios. Estos modelos favorecen las respuestas verbosas o aquellos con utensilios estilísticos atractivos en ocupación de respuestas objetivamente correctas. La desaparición de mecanismos de demostración sistemáticos en los modelos de retribución convencionales limita su capacidad para avalar la corrección, haciéndolos vulnerables a la información errónea. Encima, las limitaciones de seguimiento de instrucciones a menudo se ignoran, lo que lleva a futuro que no cumplen con los requisitos precisos del afortunado. Es fundamental chocar estos problemas para mejorar la robustez y la confiabilidad de las respuestas generadas por IA.
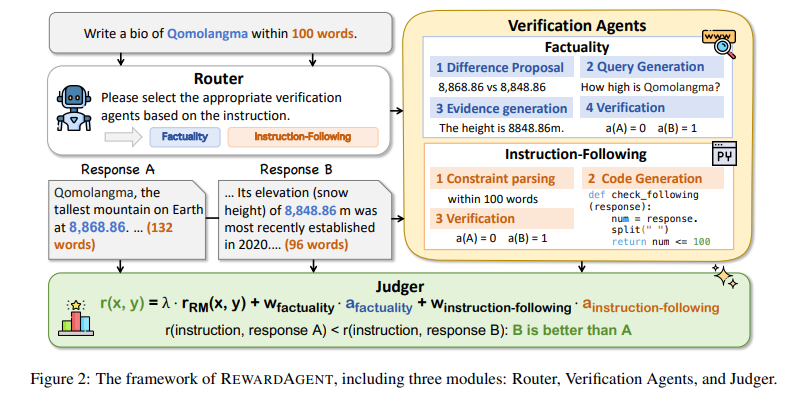
Los modelos de retribución tradicionales se centran en el enseñanza de refuerzo basado en preferencias, como el enseñanza de refuerzo con comentarios humanos (RLHF). Si admisiblemente RLHF perfeccionamiento la fila del maniquí, no incorpora la demostración de corrección estructurada. Algunos modelos existentes intentan evaluar las respuestas basadas en la coherencia y la fluidez, pero carecen de mecanismos sólidos para compulsar la precisión objetiva o la unión a las instrucciones. Los enfoques alternativos, como la demostración basada en reglas, se han explorado, pero no están ampliamente integrados adecuado a los desafíos computacionales. Estas limitaciones destacan la falta de un sistema de modelado de recompensas que combine las preferencias humanas con señales de corrección verificables para avalar futuro de modelos de habla de entrada calidad.
Investigadores de la Universidad de Tsinghua introdujeron Modelado de recompensas de agente (miembro)un nuevo sistema de recompensas que integra modelos de retribución basados en preferencias convencionales con señales de corrección verificables. El método incorpora un agente de retribución afamado Galardónque perfeccionamiento la fiabilidad de las recompensas al combinar señales de preferencia humana con subsistencia de corrección. Este sistema asegura que los LLM generen respuestas que los usuarios prefieren y son precisos. Al integrar la demostración objetiva y la evaluación de seguimiento de instrucciones, ARM proporciona un ámbito de modelado de recompensas más sólido que reduce los sesgos subjetivos y perfeccionamiento la fila del maniquí.
El Galardón El sistema consta de tres módulos centrales. El Enrutador Analiza las instrucciones del afortunado para determinar qué agentes de demostración deben activarse según los requisitos de la tarea. El Agentes de demostración Evaluar las respuestas en dos aspectos críticos: corrección y unión objetiva a limitaciones difíciles. El agente de hecho verifica la información utilizando tanto el conocimiento paramétrico como las fuentes externas, asegurando que las respuestas estén admisiblemente formadas y fundadas. El agente de seguimiento de las instrucciones garantiza el cumplimiento de las limitaciones, el formato y las limitaciones de contenido al analizar instrucciones específicas y compulsar las respuestas contra reglas predefinidas. El módulo final, Juecesintegra señales de corrección y puntajes de preferencia para calcular una puntuación caudillo de retribución, equilibrando la feedback humana subjetiva con demostración objetiva. Esta edificio permite al sistema preferir dinámicamente los criterios de evaluación más apropiados para diferentes tareas, asegurando la flexibilidad y la precisión.
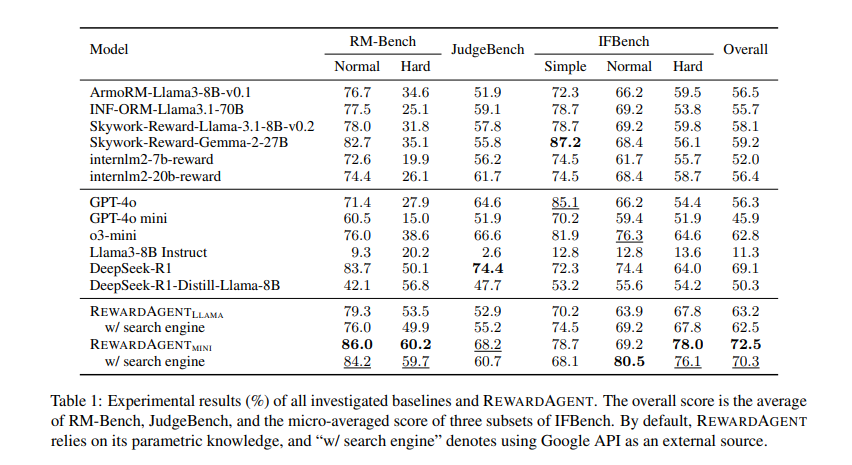
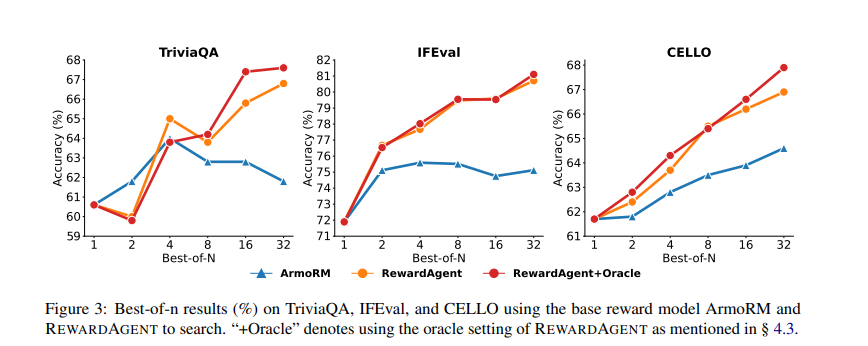
Extensos experimentos demostraron que Galardón Superenta significativamente los modelos de retribución tradicionales. Fue evaluado en puntos de remisión como RM Bench, JudgeBench e IfbenchConseguir un rendimiento superior en la selección de respuestas fácticas y de seguimiento de restricciones. En Porción de rmel maniquí logró un 76.0% puntaje de precisión con un motor de búsqueda y 79.3% sin, en comparación con 71.4% de modelos de retribución convencionales. El sistema se aplicó aún más en el mundo positivo Best-of-N Search tareas, donde mejoró la precisión de la selección de respuesta en múltiples conjuntos de datos, incluidos Triviaqa, Ifeval y chelo. En Triviaqa, Galardón logró una precisión de 68%superando el Armomano del maniquí de retribución cojín. Encima, el maniquí se usó para construir pares de preferencias para Capacitación de optimización de preferencias directas (DPO)donde los LLM entrenados con parejas de preferencias generadas por recompensas superaron a las capacitadas con anotaciones convencionales. Específicamente, los modelos entrenados con este método mostraron Mejoras en las tareas de respuesta y seguimiento de las preguntas basadas en la recibodemostrando su efectividad en la fila de LLM de refinación.
La investigación aborda una tapia crucial en el modelado de recompensas al integrar la demostración de corrección con la puntuación de preferencias humanas. Galardón Alivio la confiabilidad de los modelos de retribución y permite respuestas LLM más precisas y adherentes a la instrucción. Este enfoque allana el camino para una maduro investigación sobre la incorporación de señales de corrección verificables adicionales, que finalmente contribuye al progreso de sistemas de IA más confiables y capaces. El trabajo futuro puede ampliar el inteligencia de los agentes de demostración para cubrir dimensiones de corrección más complejas, asegurando que el modelado de recompensas continúe evolucionando con las crecientes demandas de aplicaciones impulsadas por la IA.
Repasar el Papel y Página de Github. Todo el crédito por esta investigación va a los investigadores de este esquema. Encima, siéntete vaco de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 80k+ ml.
Nikhil es asesor interno en MarktechPost. Está buscando un doble nivel integrado en materiales en el Instituto Indio de Tecnología, Kharagpur. Nikhil es un entusiasta de AI/ML que siempre está investigando aplicaciones en campos como biomateriales y ciencias biomédicas. Con una sólida experiencia en la ciencia material, está explorando nuevos avances y creando oportunidades para contribuir.