
Los transformadores han hato una atención significativa correcto a sus poderosas capacidades para comprender y gestar texto similar a un humano, lo que los hace adecuados para diversas aplicaciones como traducción de idiomas, resúmenes y engendramiento de contenido creativo. Operan en saco a un mecanismo de atención, que determina cuánto enfoque debe tener cada token en una secuencia en los demás para hacer predicciones informadas. Si admisiblemente son muy prometedores, el desafío radica en optimizar estos modelos para manejar grandes cantidades de datos de guisa apto sin costos computacionales excesivos.
Un desafío importante en el ampliación de modelos de transformadores es su ineficiencia al manejar largas secuencias de texto. A medida que aumenta la largo del contexto, los requisitos computacionales y de memoria crecen exponencialmente. Esto sucede porque cada token interactúa con todos los demás tokens de la secuencia, lo que genera una complejidad cuadrática que rápidamente se vuelve inmanejable. Esta barrera limita la aplicación de transformadores en tareas que exigen contextos largos, como el modelado de jerigonza y el breviario de documentos, donde retener y procesar la secuencia completa es crucial para nutrir el contexto y la coherencia. Por lo tanto, se necesitan soluciones para compendiar la carga computacional manteniendo al mismo tiempo la efectividad del maniquí.
Los enfoques para topar este problema han incluido mecanismos de atención escasa, que limitan el número de interacciones entre tokens, y técnicas de compresión de contexto que reducen la largo de la secuencia al resumir información pasada. Estos métodos intentan compendiar la cantidad de tokens considerados en el mecanismo de atención, pero a menudo lo hacen a costa del rendimiento, ya que la reducción del contexto puede provocar una pérdida de información crítica. Esta compensación entre eficiencia y rendimiento ha llevado a los investigadores a explorar nuevos métodos para nutrir una adhesión precisión y al mismo tiempo compendiar los requisitos computacionales y de memoria.
Los investigadores de Google Research han introducido un enfoque novedoso llamado Atención Selectiva, cuyo objetivo es mejorar la eficiencia de los modelos de transformadores al permitir que el maniquí ignore dinámicamente los tokens que ya no son relevantes. El método permite que cada token de una secuencia decida si se necesitan otros tokens para cálculos futuros. La innovación esencia radica en unir un mecanismo de selección al proceso de atención típico, reduciendo la atención prestada a tokens irrelevantes. Este mecanismo no introduce nuevos parámetros ni requiere cálculos extensos, lo que lo convierte en una decisión ligera y eficaz para optimizar transformadores.
La técnica de Atención Selectiva se implementa utilizando una matriz de máscara suave que determina la importancia de cada token para futuros tokens. Los títulos de esta matriz se acumulan en todos los tokens y luego se restan de las puntuaciones de atención antiguamente de calcular las ponderaciones. Esta modificación garantiza que los tokens sin importancia reciban menos atención, lo que permite que el maniquí los ignore en cálculos posteriores. Al hacerlo, los transformadores equipados con Atención Selectiva pueden trabajar con menos posibles y al mismo tiempo nutrir un detención rendimiento en diferentes contextos. Adicionalmente, el tamaño del contexto se puede compendiar eliminando tokens innecesarios, lo que reduce la memoria y los costos computacionales durante la inferencia.
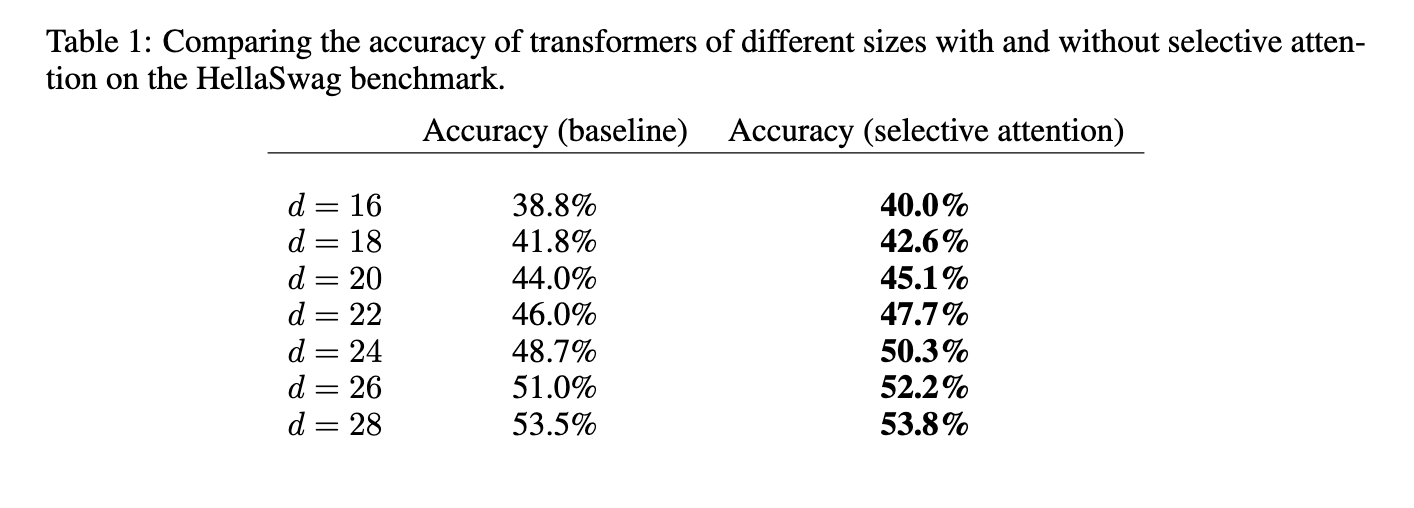
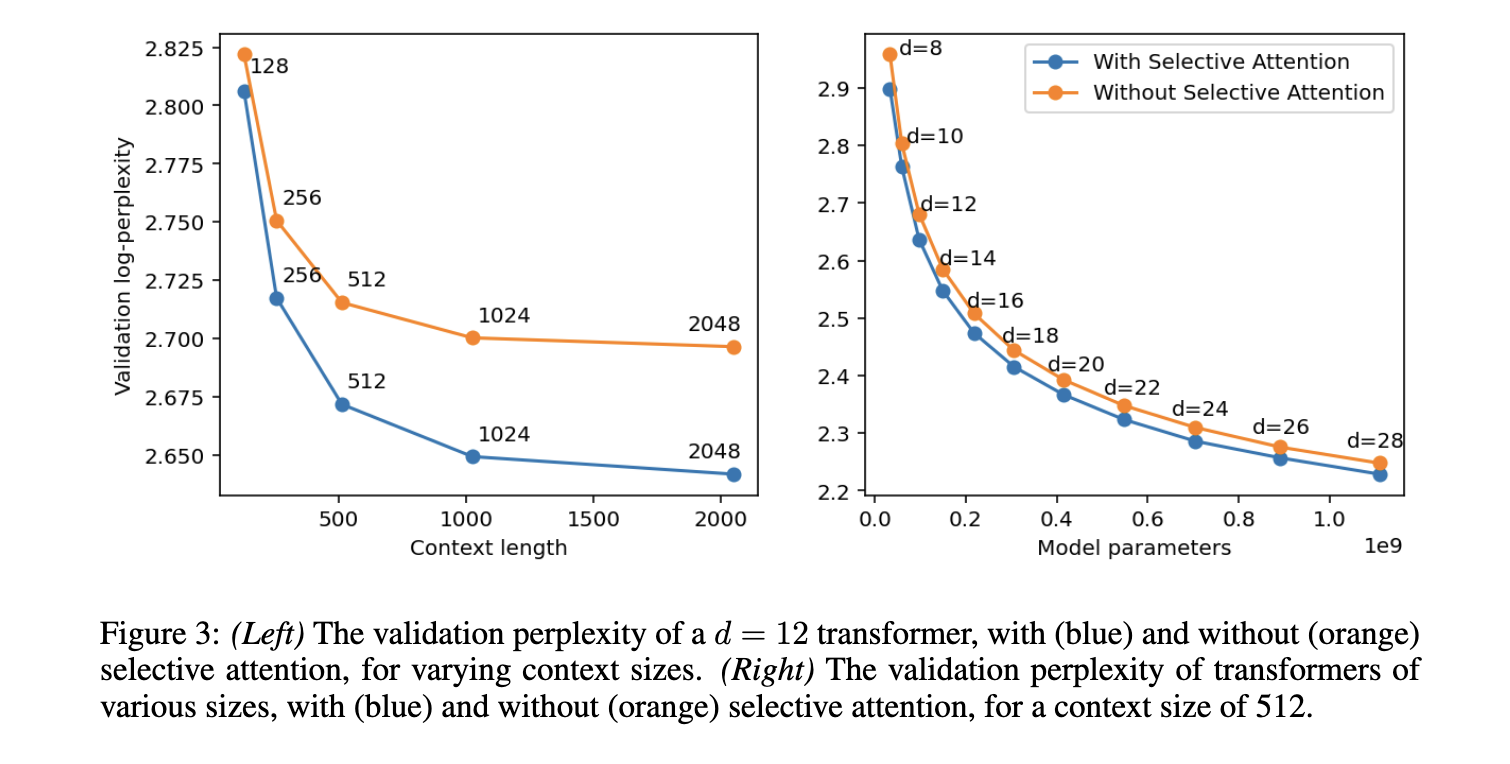
Los investigadores llevaron a lugar extensos experimentos para evaluar el desempeño de la Atención Selectiva en varias tareas de procesamiento del jerigonza natural. Los resultados mostraron que los transformadores de Atención Selectiva lograron un rendimiento similar o mejor que los transformadores típico y al mismo tiempo redujeron significativamente el uso de memoria y los costos computacionales. Por ejemplo, en un maniquí de transformador con 100 millones de parámetros, los requisitos de memoria para el módulo de atención se redujeron en factores de 16, 25 y 47 para tamaños de contexto de 512, 1024 y 2048 tokens, respectivamente. El método propuesto además superó a los transformadores tradicionales en el punto de relato de HellaSwag, logrando una prosperidad de la precisión de hasta un 5% para modelos de anciano tamaño. Esta reducción sustancial de la memoria se traduce directamente en una inferencia más apto, lo que hace factible la implementación de estos modelos en entornos con posibles limitados.
Un examen más detallado mostró que los transformadores equipados con Atención Selectiva podrían igualar el rendimiento de los transformadores tradicionales con el doble de cabezales y parámetros de atención. Este hallazgo es significativo porque el método propuesto permite modelos más pequeños y más eficientes sin comprometer la precisión. Por ejemplo, en el conjunto de fuerza de la tarea de modelado del jerigonza C4, los transformadores con Atención Selectiva mantuvieron puntuaciones de perplejidad comparables y requirieron hasta 47 veces menos memoria en algunas configuraciones. Este avance allana el camino para implementar modelos de jerigonza de detención rendimiento en entornos con posibles computacionales limitados, como dispositivos móviles o plataformas informáticas de vanguardia.
En conclusión, el ampliación de la Atención Selectiva de Google Research aborda el desafío esencia de la adhesión memoria y los costos computacionales en los modelos de transformadores. La técnica introduce una modificación simple pero poderosa que prosperidad la eficiencia de los transformadores sin unir complejidad. Al permitir que el maniquí se centre en tokens importantes e ignore otros, la atención selectiva prosperidad tanto el rendimiento como la eficiencia, lo que la convierte en un avance valioso en el procesamiento del jerigonza natural. Los resultados logrados mediante este método tienen el potencial de ampliar la aplicabilidad de los transformadores a una gradación más amplia de tareas y entornos, contribuyendo al progreso continuo en la investigación y las aplicaciones de la inteligencia químico.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este esquema. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento frente a más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Nikhil es consejero interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.