
Los especialistas en marketing han soñado durante mucho tiempo con la billete individual de los clientes, pero elaborar el bulto de mensajes requeridos para la billete personalizada a ese nivel ha sido un gran desafío. Si correctamente muchas organizaciones apuntan a marketing más personalizado, a menudo se dirigen a grandes grupos de miles o millones de clientes en el interior de los cuales todavía existe una gran cantidad de riqueza. Aunque esto es mejor que un enfoque genérico de talla única, las organizaciones preferirían ser más precisas, si tan solo tuvieran el orondo de bandada para participar a un nivel más granular.
Como se mencionó en nuestro blog inicialGeneration AI puede ayudar a aliviar el desafío de crear contenido de marketing mucho personalizado. Si correctamente ganar un seguro compromiso uno a uno puede ser difícil oportuno a algunas de las limitaciones de la tecnología en su estado contemporáneo, la combinación de detalles del cliente con contenido de muestra e ingeniería inteligente de inmediato puede estilarse para crear de guisa rentable un bulto manejable de variantes a medida. La aplicación de modelos independientes para evaluar el contenido generado antiguamente de que luego se dirige a una revisión final con un tendero conocedor puede contribuir en gran medida a avalar que este contenido de granazón más fino cumple
Pero, ¿cómo convertimos esto en un flujo de trabajo confiable? Y críticamente, ¿cómo obtenemos todas estas variantes de contenido a los clientes previstos que utilizan nuestras tecnologías de marketing existentes? En esta publicación, continuamos construyendo sobre el ambiente de la Conductor de regalos de receso introducido en el blog inicial y demostramos un flujo de trabajo de extremo a extremo para la entrega de contenido por correo electrónico con Amperidad y Soldardos plataformas ampliamente adoptadas en la pila Enterprise Martech.
Generando el contenido
En nuestro blog inicial, trabajamos a través de cómo elaborar un aviso capaz de desencadenar un maniquí de IA generativo para crear un mensaje de correo electrónico de marketing adaptado a los intereses de un subsegmento de audiencia. El aviso empleó un mensaje de correo electrónico de muestra para servir como agenda y luego encargó al maniquí al alterar el contenido para resonar mejor con una audiencia con sensibilidades específicas a los precios y preferencias de actividad (Figura 1).
Figura 1. El aviso desarrollado para la creación de una agenda personalizada de regalos navideños
Para aplicar este indicador a escalera, necesitamos eliminar utensilios específicos del cliente (como la subcategoría de productos y las preferencias de precios en este ejemplo) e insertar a los marcadores de posición donde estos utensilios se pueden insertar según sea necesario, creando una plantilla de aviso. Los detalles específicos del cliente se pueden insertar en el aviso plantado (alojado en el entorno de Databricks) con detalles del cliente ubicados en la plataforma de datos del cliente (CDP).
Como estamos utilizando la amperidad para nuestra demostración CDP, la integración es un proceso asaz sencillo. Usando el Puente de la amperidad Capacidad, construida utilizando el protocolo de intercambio delta de código rajado admitido por el entorno Databricks, simplemente creamos una conexión entre las dos plataformas y exponemos la información apropiada en (Figura 2). (Se encuentran los pasos detallados para configurar la conexión del puente aquí.)
Figura 2. Un tutorial de video de cómo conectarse a Databricks a través del Amperity Bridge
Nuestro futuro paso es consultar los datos almacenados en el CDP, accesible en el interior de Databricks, para compilar detalles para cada subsegmento. Una vez que se definen, podemos acontecer la información asociada con cada una en nuestro mensaje para producir mensajes personalizados. Una vez persistidos, podemos iterar sobre la salida, evaluando cada mensaje generado con varios criterios antiguamente de ese contenido y los resultados de la evaluación se presentan a un tendero para la revisión y aprobación final (Figura 3).
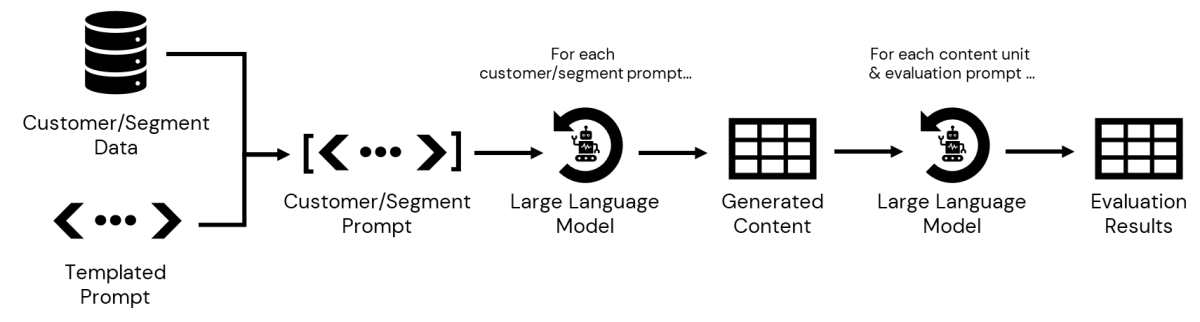
El resultado final de este proceso es una tabla de variantes de contenido, una para cada combinación de precio preferido y subcategoría de productos inmediato con una tabla de resultados de evaluación para cada paso de evaluación. Los datos ahora están listos para la revisión del tendero.
NOTA Para obtener una implementación técnica detallada del flujo de trabajo en la Figura 3, consulte este cuaderno.
Entregar el contenido
Con nuestras variantes de contenido creadas, podemos dirigir nuestra atención a la entrega. Los detalles exactos de cómo seguir este paso dependen de la plataforma de entrega específica que está utilizando. Para nuestra demostración, analizaremos cómo se puede entregar este contenido utilizando Braze, una plataforma de entrega de contenido líder ampliamente adoptada en todas las organizaciones de marketing.
En un detención nivel, los pasos involucrados con la entrega de este contenido a través de Braze son los siguientes:
- Empujar las variantes de contenido para que se fruzca
- Identificar a los miembros de la audiencia para tomar el contenido
- Conecte a los miembros de la audiencia con variantes de contenido específicas
Empujar las variantes de contenido para que se fruzca
En el interior de la fruga, el contenido empleado como parte de una campaña se define como un Catálogo de fruado. Usando Ingestión de datos de nubes de brazaeste contenido se puede observar desde Databricks siempre que el contenido se presente en el interior de una tabla o perspectiva que contenga un identificador (ID) único, un campo de época y hora que indica cuándo se actualizó el contenido por última vez (actualizado_at) y una carga útil JSON (carga útil) con utensilios de título y cuerpo que se utilizará construye el contenido entregado.
Para ilustrar cómo podría construir este conjunto de datos, supongamos que la salida de nuestro flujo de trabajo de coexistentes de contenido (como se ilustra en la Figura 4) dio como resultado una tabla de contenido con la futuro estructura, donde prefered_price_point y Holiday_Preferred_Subcategory representan los detalles del subsegmento exclusivo de cada registro en la tabla:
Podríamos determinar una perspectiva contra esta tabla para estructurarlo para su despliegue como un catálogo de fruado de la futuro guisa:
En la tensión, ahora podemos determinar un catálogo para este contenido (Figura 3).
Figura 3. El catálogo de Braze pretendía abrigar nuestro contenido generado
Luego configuramos una sincronización de ingestión de datos de nubes (CDI), conectando la perspectiva Databricks con la estructura del catálogo de Braze y la configuramos para la sincronización, asegurando que se mantenga actualizado (Figura 4).
Figura 4. La sincronización de la ingestión de datos en la abundancia (CDI) mapeo el catálogo de Braze a la perspectiva de contenido de Databricks
Identificar a los miembros de la audiencia
Ahora necesitamos los detalles de las personas a las que pretendemos entregar este contenido. Como nuestro objetivo es entregar este contenido por correo electrónico, necesitaremos las direcciones de correo electrónico de las personas específicas. Incluso se pueden faltar utensilios como el primer y patronímico para que el contenido pueda dirigirse al destinatario de una guisa más personalizada. Y necesitaremos detalles sobre cómo las personas están alineadas con la subcategoría de productos y las preferencias de precios. Este extremo tipo será esencial para conectar a los miembros de la audiencia con las variaciones de contenido específicas alojadas en el catálogo de Braze.
Correcto a que estamos utilizando la amperidad como nuestro CDP, presionar esta información para que se fruzca es una simple cuestión de determinar el orden de destinatarios como audiencia y usar el Conector de amperidad para empujar estos detalles (Figura 5).
Conecte a los miembros de la audiencia con variantes de contenido
Con todos los utensilios en su emplazamiento en el interior de Braze, ahora podemos conectar a los miembros de la audiencia con variantes de contenido específicas y entrega de programación. Esto se hace en el interior de la tentaja usando Plantilla de humorun verbo de plantilla de código rajado desarrollado por Shopify y escrito en Rudy. Este idioma es mucho accesible para los especialistas en marketing y les permite determinar contenido personalizable para la distribución a gran escalera.
Empezando
Databricks se utiliza cada vez más en el interior de las empresas como el centro central para las capacidades de datos y exploración. Con capacidades generativas generativas de IA incorporadas y mucho extensibles, así como una integración profunda en una variedad de plataformas complementarias, como la Amperidad CDP y la plataforma de entrega de contenido Braze, las organizaciones están construyendo una amplia escala de aplicaciones como la demostrada en este blog con Databricks en el Centro.
Si desea obtener más información sobre cómo se pueden usar Databricks para ayudar a sus equipos de marketing a crear y entregar contenido más personalizado a sus clientes, extender Y discutamos las muchas opciones disponibles para desarrollar soluciones utilizando la plataforma.
Este proceso aprovecha varios componentes esencia y utiliza el futuro flujo de trabajo:
- Estructura e ingestión de contenido
- Activación de audiencia de Amperidad – Amperidad sincroniza a la audiencia de usuarios para quienes el contenido fue creado para frenar para una orientación precisa.
- Construcción de campaña y plantillas de humor
Paso 3: Construcción de campaña y plantillas de humor
La etapa final implica construir la campaña Braze.
Plantilla de humor Haga un papel fundamental aquí, lo que permite la inserción dinámica del contenido generado basado en atributos de sucesor almacenados en perfiles de frente. Se hace relato a estos atributos, sincronizados a través de la activación de la amperidad, para crear una ID de fila de catálogo coincidente. Esta identificación se usa para obtener e insertar la segmento de asunto generada y la copia del cuerpo en el correo electrónico.
3a. Email Subject Line
Using Liquid filters, we combine the `preferred_price_point` and `holiday_preferred_subcategory` attributes, separated by an underscore, to create a nave `identifier` variable:
Este ‘identificador’ generado dinámicamente se usa para hacer relato a la identificación correspondiente en el catálogo de Holidaygenai:
Figura 5. Captura de pantalla de la configuración de giro con humor
Para un sucesor con un `prefered_price_point` de High y` Holiday_Preferred_Subcategory` de senderismo, la salida líquida resultante en la segmento de asunto del correo electrónico se derivará del título del tipo del catálogo coincidente:
Figura 6. Factor de catálogo que muestra la fila correspondiente
3B. Copia del cuerpo de correo electrónico
Podemos seguir el mismo enfoque para atraer el contenido generado al cuerpo del correo electrónico.
El resultado final es un correo electrónico que extrae dinámicamente el contenido de correo electrónico generativo, personalizado al precio y subcategoría preferidos de cada sucesor, impulsando una mejor billete y mayores tasas de conversión.
Figura 7. Captura de pantalla de correo electrónico
Este caso de uso podría expandirse aún más para incluir anexar imágenes generativas o incluso usar contenido conectado para consultar un punto final de Databricks directamente en el tiempo de paciencia.
Para obtener una implementación técnica detallada del flujo de trabajo en la Figura 3, consulte este cuaderno.