
En Databricks, utilizamos Refplyiendo Learning (RL) para desarrollar modelos de razonamiento para problemas que enfrentan nuestros clientes, así como para nuestros productos, como el Asistente de Databricks y Ai/bi temperamento. Estas tareas incluyen producir código, analizar datos, integrar el conocimiento organizacional, la evaluación específica del dominio y Procedencia de información (es asegurar) de documentos. Tareas como la codificación o la cuna de información a menudo tienen recompensas verificables: la corrección se puede revisar directamente (por ejemplo, pruebas de aprobación, etiquetas coincidentes). Esto permite el enseñanza de refuerzo sin un maniquí de remuneración aprendido, conocido como RLVR (enseñanza de refuerzo con recompensas verificables). En otros dominios, se puede requerir un maniquí de remuneración personalizado, que además es compatible con Databricks. En esta publicación, nos centramos en la configuración RLVR.
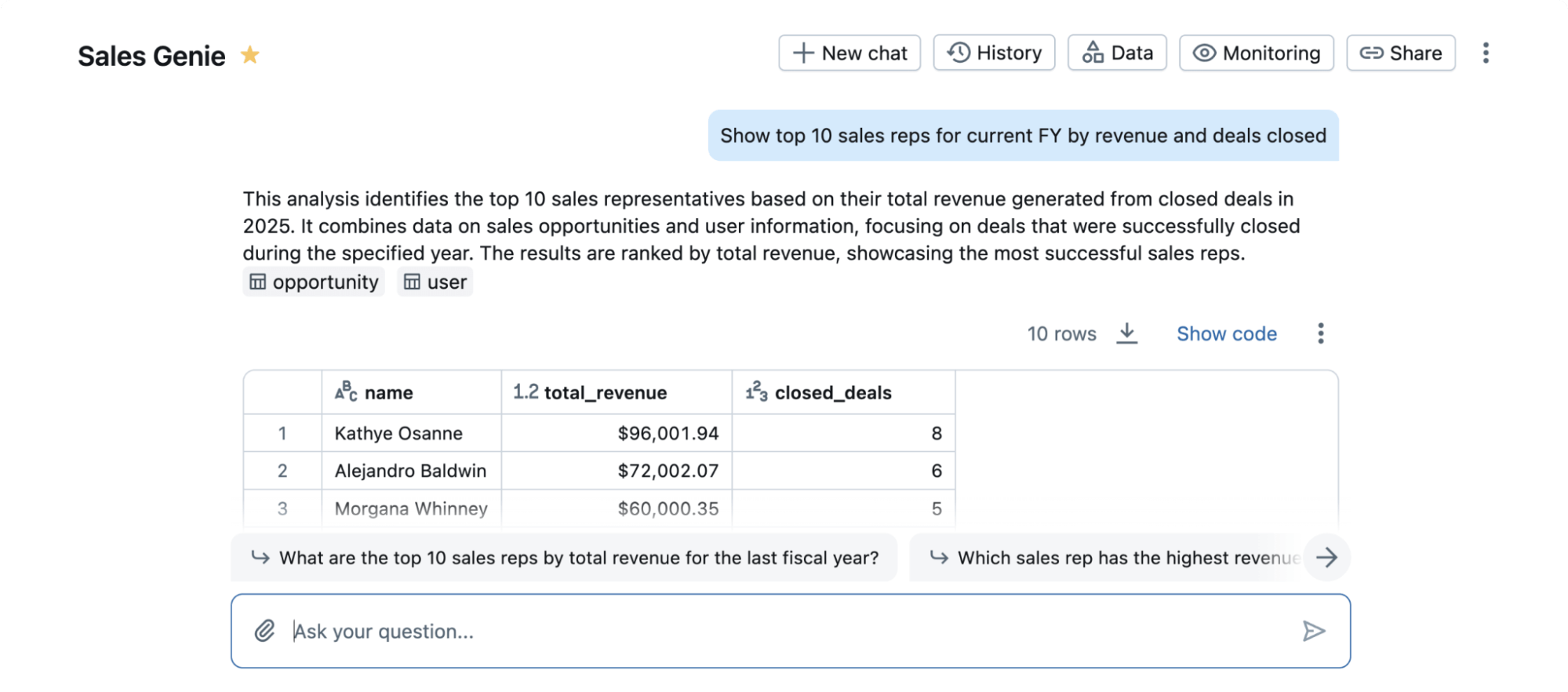
Como ejemplo del poder de RLVR, aplicamos nuestra pila de capacitación a un punto de narración purista popular en ciencias de datos llamadas PÁJARO. Este punto de narración estudia la tarea de alterar una consulta de lengua natural en un código SQL que se ejecuta en una almohadilla de datos. Este es un problema importante para los usuarios de Databricks, lo que permite a los expertos no SQL conversar con sus datos. Asimismo es una tarea desafiante en la que incluso los mejores LLM de propiedad no funcionan admisiblemente fuera de la caja. Mientras que Bird no captura completamente la complejidad del mundo existente de esta tarea ni el toque completo de productos reales como Databricks AI/BI Genie (Figura 1), su popularidad nos permite calcular la operatividad de RLVR para la ciencia de datos en un punto de narración admisiblemente entendido.
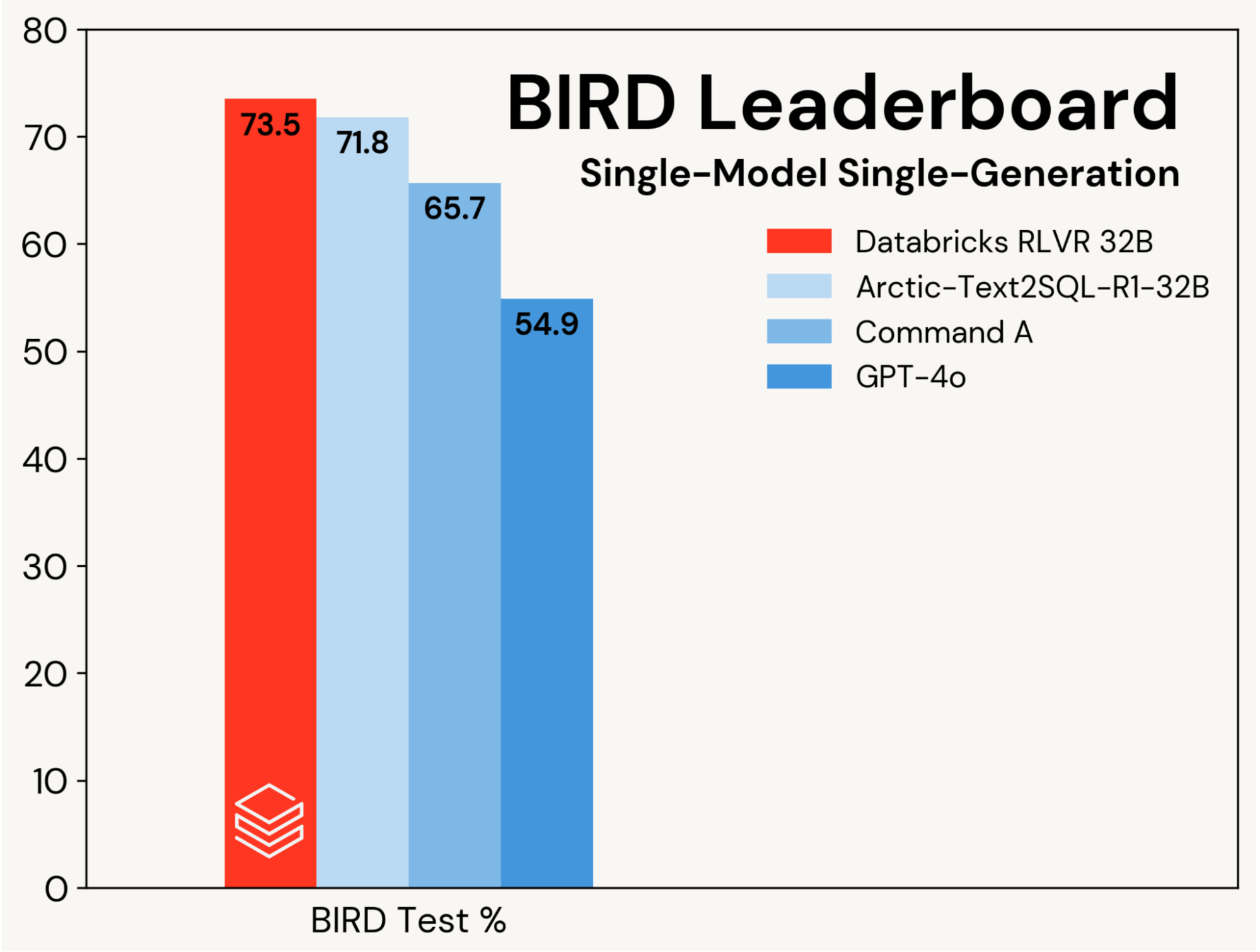
Nos centramos en mejorar un maniquí de codificación SQL almohadilla utilizando RLVR, aislando estas ganancias de las mejoras impulsadas por diseños de agente. El progreso se mide en la pista de una sola coexistentes de un solo maniquí de la tabla de clasificación de aves (es asegurar, sin autoconsistencia), que se evalúa en un conjunto de pruebas privadas.
Establecimos una nueva precisión de prueba de vanguardia del 73.5% en este punto de narración. Lo hicimos usando nuestra pila RLVR unificado y entrenamiento solo en el set de entrenamiento de aves. El mejor puntaje aludido en esta pista fue del 71.8%(1)acabado aumentando el conjunto de entrenamiento de aves con datos adicionales y utilizando un LLM patentado (GPT-4O). Nuestra puntuación es sustancialmente mejor que el maniquí almohadilla diferente y las LLM propietarias (ver Figura 2). Este resultado muestra la simplicidad y universalidad de RLVR: alcanzamos esta puntuación con datos unificado y los componentes RL unificado en los que estamos implementando Ladrillos de agentey lo hicimos en nuestra primera sumisión a Bird. RLVR es una poderosa segmento de almohadilla que los desarrolladores de IA deben considerar cuando hay suficientes datos de capacitación disponibles.
Construimos nuestra presentación basada en el conjunto de ampliación de pájaros. Descubrimos que QWEN 2.5 32B Coder Instruct era el mejor punto de partida. Ajustamos este maniquí usando los dos Databricks Tao – Un método RL fuera de segmento y nuestra pila RLVR. Este enfoque adjunto con una cuidadosa rápida y la selección del maniquí fue suficiente para llevarnos a la cima del punto de narración de aves. Este resultado es una demostración pública de las mismas técnicas que estamos utilizando para mejorar los productos de Databricks populares como AI/Bi Genie and Assistant y para ayudar a nuestros clientes a construir agentes que usan Ladrillos de agente.
Nuestros resultados destacan el poder de RLVR y la operatividad de nuestra pila de entrenamiento. Los clientes de Databricks además tienen reportado Excelentes resultados usando nuestra pila en sus dominios de razonamiento. Creemos que esta fórmula es poderosa, compuesta y ampliamente aplicable a una variedad de tareas. Si desea obtener una tino previa de RLVR en Databricks, contáctenos aquí.
1Ver Tabla 1 en https://arxiv.org/pdf/2505.20315
Autores: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, DiPendra Kumar Misra, Jose Javier Gonzalez, Krista Opsahl-Anga