
Nemotron 3 Super ahora está habitable como maniquí totalmente administrado y sin servidor en Roca Amazónica, uniéndose a los modelos Nemotron Nano que ya están disponibles adentro del entorno Amazon Bedrock.
Con NVIDIA Nemotrón Con modelos abiertos en Amazon Bedrock, puede acelerar la innovación y ofrecer valía empresarial tangible sin tramitar las complejidades de la infraestructura. Puedes favorecer tu IA generativa aplicaciones con Nemotron a través de la inferencia totalmente administrada de Amazon Bedrock, utilizando sus amplias funciones y herramientas.
Esta publicación explora las características técnicas del maniquí Nemotron 3 Super y analiza posibles casos de uso de aplicaciones. Asimismo proporciona orientación técnica para comenzar a utilizar este maniquí para sus aplicaciones de IA generativa adentro del entorno de Amazon Bedrock.
Acerca de Nemotrón 3 Súper
Nemotron 3 Super es un maniquí híbrido de Mezcla de Expertos (MoE) con eficiencia y precisión informática líderes para aplicaciones multiagente y para sistemas de IA agentes especializados. El maniquí se lanceta con pesos, conjuntos de datos y recetas abiertos para que los desarrolladores puedan personalizar, mejorar e implementar el maniquí en su infraestructura para mejorar la privacidad y la seguridad.
Descripción militar del maniquí:
- Obra:
- MoE con construcción híbrida Transformer-Mamba.
- Admite el presupuesto de tokens para proporcionar una precisión mejorada con una gestación mínima de tokens de razonamiento.
- Exactitud:
- La anciano eficiencia de rendimiento en su categoría de tamaño y hasta 5 veces más que el maniquí Nemotron Super aludido.
- Precisión líder para tareas de razonamiento y agencia entre los principales modelos abiertos y una precisión hasta 2 veces anciano que la interpretación aludido.
- Logra una adhesión precisión en los principales puntos de remisión, incluidos AIME 2025, Terminal-Bench, SWE Bench verificado y multilingüe, RULER.
- La capacitación RL en múltiples entornos brindó al maniquí una precisión líder en más de 10 entornos con NVIDIA NeMo.
- Tamaño del maniquí: 120 B con 12 B parámetros activos
- Largo del contexto: hasta 256.000 tokens
- Entrada del maniquí: Texto
- Salida del maniquí: Texto
- Idiomas: inglés, francés, germano, italiano, japonés, gachupin y chino
MoE recóndito
Nemotron 3 Super utiliza MoE recóndito, donde los expertos operan en una representación recóndito compartida antaño de que los resultados se proyecten de nuevo al espacio simbólico. Este enfoque permite que el maniquí recurra a 4 veces más expertos con el mismo costo de inferencia, lo que permite una mejor especialización en torno a estructuras semánticas sutiles, abstracciones de dominio o patrones de razonamiento de múltiples saltos.
Predicción de tokens múltiples (MTP)
MTP permite que el maniquí prediga varios tokens futuros en un solo paso en torno a delante, lo que aumenta significativamente el rendimiento para secuencias de razonamiento largas y resultados estructurados. Para planificación, gestación de trayectorias, ampliada. condena de pensamientoo gestación de código, MTP reduce la latencia y mejoría la capacidad de respuesta del agente.
Para obtener más información sobre la construcción de Nemotron 3 Super y cómo se entrena, consulte Presentamos Nemotron 3 Super: un transformador MoE híbrido extenso Mamba para razonamiento agente.
Casos de uso de NVIDIA Nemotron 3 Super
Nemotron 3 Super ayuda a impulsar varios casos de uso para diferentes industrias. Algunos de los casos de uso incluyen
- Avance de software: ayudar con tareas como el esquema de código.
- Finanzas: Acelere el procesamiento de préstamos extrayendo datos, analizando patrones de ingresos y detectando operaciones fraudulentas, lo que puede ayudar a compendiar los tiempos de ciclo y el aventura.
- Ciberseguridad: se puede utilizar para clasificar problemas, realizar prospección de malware en profundidad y inquirir amenazas de seguridad de forma proactiva.
- Búsqueda: puede ayudar a comprender la intención del legatario de activar a los agentes adecuados.
- Comercio minorista: puede ayudar a optimizar la trámite de inventario y mejorar el servicio en la tienda con soporte y recomendaciones de productos personalizados en tiempo auténtico.
- Flujos de trabajo de múltiples agentes: organiza agentes de tareas específicas (planificación, uso de herramientas, comprobación y ejecución de dominio) para automatizar procesos comerciales complejos de extremo a extremo.
Comience con NVIDIA Nemotron 3 Super en Amazon Bedrock. Complete los siguientes pasos para probar NVIDIA Nemotron 3 Super en Amazon Bedrock
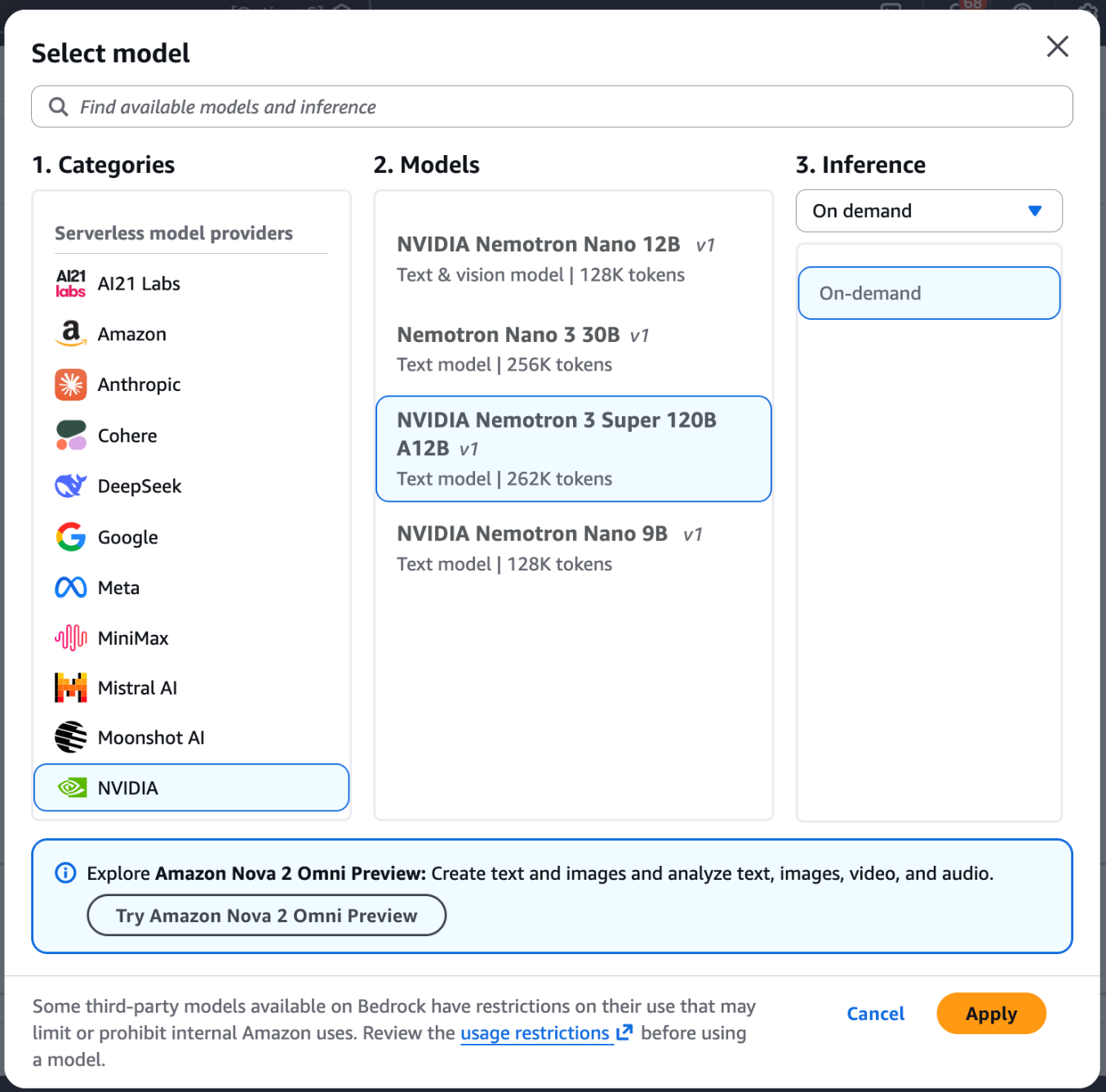
- Navega hasta el Consola Amazon Bedrock y seleccione Zona de juegos de chat/texto en el menú de la izquierda (bajo el Prueba sección).
- Designar Decidir maniquí en la vértice superior izquierda del patio de recreo.
- Designar Nvidia de la tira de categorías, luego seleccione NVIDIA Nemotrón 3 Super.
- Designar Aplicar para cargar el maniquí.
Posteriormente de completar los pasos anteriores, podrá probar el maniquí inmediatamente. Para mostrar verdaderamente Nemotrón 3 Super capacidad, iremos más allá de la simple sintaxis y le asignaremos un arduo desafío de ingeniería. Los modelos de stop razonamiento sobresalen en el pensamiento «a nivel de sistema», donde deben equilibrar las compensaciones arquitectónicas, la concurrencia y la trámite del estado distribuido.
Utilicemos el venidero mensaje para diseñar un servicio distribuido conjuntamente:
"Design a distributed rate-limiting service in Python that must support 100,000 requests per second across multiple geographic regions.
1. Provide a high-level architectural strategy (e.g., Token Bucket vs. Fixed Window) and justify your choice for a general scale. 2. Write a thread-safe implementation using Redis as the backing store. 3. Address the 'race condition' problem when multiple instances update the same counter. 4. Include a pytest suite that simulates network latency between the app and Redis."
Este mensaje requiere que el maniquí funcione como un ingeniero senior de sistemas distribuidos: razonar sobre compensaciones, producir código seguro para subprocesos, anticipar modos de descompostura y validar todo con pruebas realistas, todo en una única respuesta coherente.
Uso de la CLI y los SDK de AWS
Puede entrar al maniquí mediante programación utilizando el ID del maniquí. nvidia.nemotron-super-3-120b . El maniquí soporta tanto el Invocar maniquí y Conversar API a través de Interfaz de crencha de comandos de AWS (AWS CLI) y SDK de AWS con nvidia.nemotron-super-3-120b como ID del maniquí. Adicionalmente, es compatible con la API compatible con Amazon Bedrock OpenAI SDK.
Ejecute el venidero comando para invocar el maniquí directamente desde su terminal usando el Interfaz de crencha de comandos de AWS (AWS CLI) y API de InvokeModel:
Si desea invocar el maniquí a través del AWS SDK para Python (Boto3), use el venidero script para mandar un mensaje al maniquí, en este caso usando la API de Converse:
Para invocar el maniquí a través del punto final ChatCompletions compatible con Amazon Bedrock OpenAI, puede proceder de la venidero forma utilizando el SDK de OpenAI:
Conclusión
En esta publicación, le mostramos cómo comenzar a utilizar NVIDIA Nemotron 3 Super en Amazon Bedrock para crear la próxima gestación de aplicaciones de IA agente. Al combinar la construcción vanguardia Hybrid Transformer-Mamba del maniquí y Latent MoE con la infraestructura sin servidor totalmente administrada de Amazon Bedrock, las organizaciones ahora pueden implementar aplicaciones eficientes y de stop razonamiento a escalera sin el trabajo pesado de la compañía backend. ¿Vivo para ver lo que este maniquí puede hacer por su flujo de trabajo específico?
- Pruébalo ahora: Dirígete al Consola Amazon Bedrock para estudiar con NVIDIA Nemotron 3 Super en el patio de juegos maniquí.
- Construir: Explora el SDK de AWS para integrar Nemotron 3 Super en sus canales de IA generativa existentes.
Sobre los autores