
Esta publicación muestra cómo Amazon EMR 7.12 puede hacer que sus cargas de trabajo de Apache Spark e Iceberg tengan un rendimiento hasta 4,5 veces más rápido.
El Tiempo de ejecución de Amazon EMR para Apache Spark proporciona un entorno de ejecución de detención rendimiento con compatibilidad API total con código descubierto chispa apache y Iceberg apache. Amazon EMR en EC2, Amazon EMR sin servidor, Amazon EMR en Amazon EKS, Amazon EMR en puestos avanzados de AWS y Pegamento AWS Utilice los tiempos de ejecución optimizados.
Nuestros puntos de relato muestran que Amazon EMR 7.12 ejecuta cargas de trabajo TPC-DS de 3 TB 4,5 veces más rápido que el código descubierto Spark 3.5.6 con Iceberg 1.10.0.
Las mejoras de rendimiento incluyen optimizaciones para el almacenamiento en gusto de metadatos, E/S paralela, planificación de consultas adaptativa, manejo de tipos de datos y tolerancia a fallas. Asimismo hubo algunas regresiones específicas de Iceberg en torno a escaneos de datos que identificamos y arreglamos.
Estas optimizaciones le permiten igualar el rendimiento de Parquet en Amazon EMR y al mismo tiempo proseguir las características secreto de Iceberg: transacciones ACID, viajes en el tiempo y transformación de esquemas.
Resultados de relato en comparación con el código descubierto
Para evaluar el rendimiento del motor Spark con el formato de tabla Iceberg, realizamos pruebas comparativas utilizando el Conjunto de datos TPC-DS de 3 TB, traducción 2.13un punto de relato standard popular de la industria. Se realizaron pruebas comparativas para el tiempo de ejecución de Amazon EMR para Apache Spark y Apache Iceberg en clústeres EC2 de Amazon EMR 7.12 en comparación con Apache Spark 3.5.6 y Apache Iceberg 1.10.0 de código descubierto en clústeres EC2.
Nota: Nuestros resultados derivados del conjunto de datos de TPC-DS no son directamente comparables con los resultados oficiales de TPC-DS correcto a diferencias de configuración.
Las instrucciones de configuración y los detalles técnicos están disponibles en nuestro repositorio de GitHub. Minimizar la influencia de catálogos externos como Pegamento AWS y Hive, utilizamos el catálogo de Hadoop para las tablas Iceberg. Esto utiliza el sistema de archivos subyacente, específicamente Amazon S3, como catálogo. Podemos delimitar esta configuración configurando la propiedad spark.sql.catalog.. Las tablas de hechos utilizaron la partición predeterminada por la columna de vencimiento, que varía entre 200 y 2100 particiones. No se utilizaron estadísticas precalculadas para estas tablas.
Ejecutamos un total de 104 consultas SparkSQL en 3 rondas secuenciales y se tomó el tiempo de ejecución promedio de cada consulta en estas rondas para comparar. El tiempo de ejecución promedio de las 3 rondas en Amazon EMR 7.12 con Iceberg gestor fue de 0,37 horas, lo que demuestra un aumento de velocidad de 4,5 veces en comparación con el código descubierto Spark 3.5.6 e Iceberg 1.10.0. La futuro figura presenta los tiempos de ejecución totales en segundos.
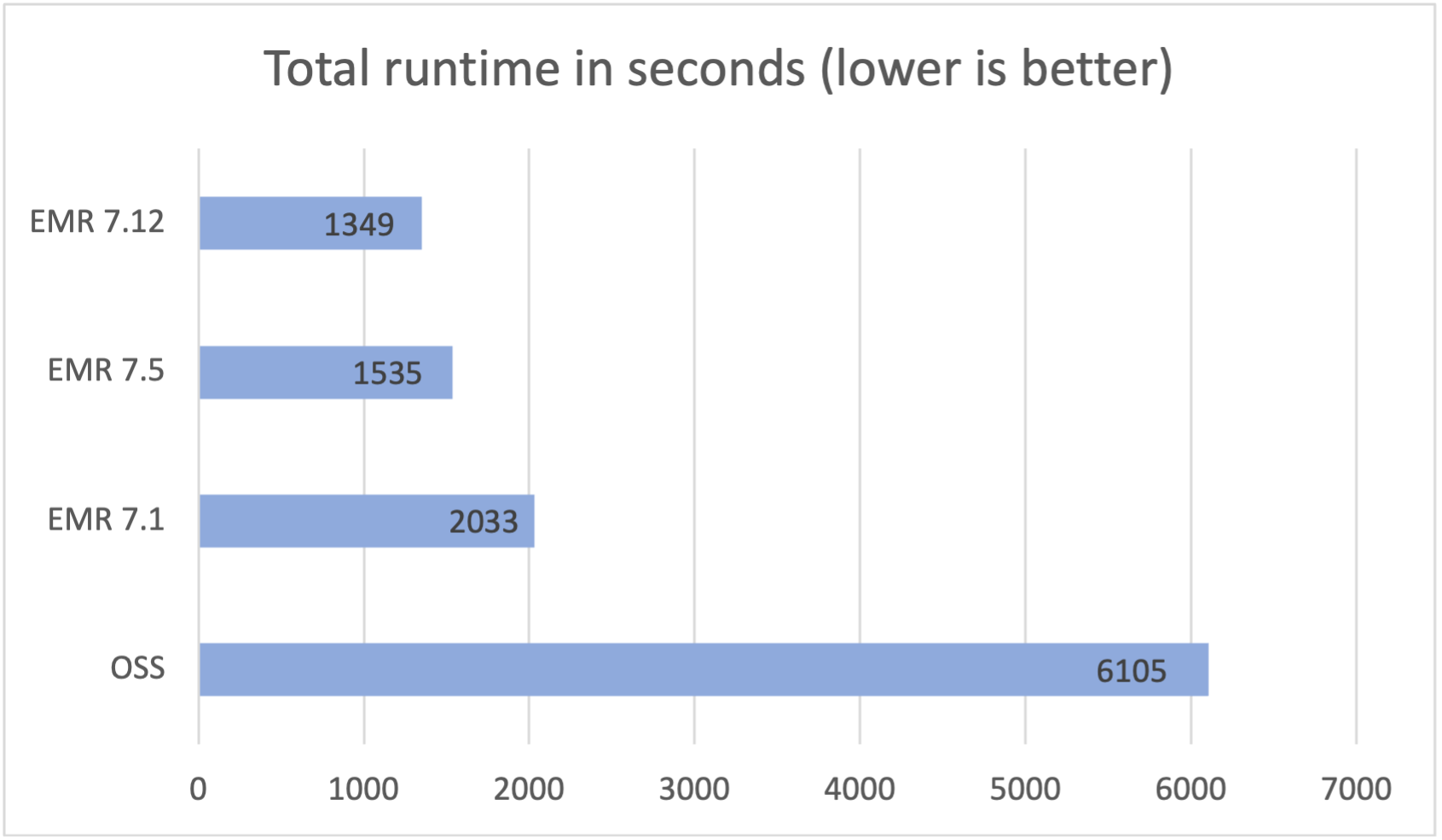
La futuro tabla resume las métricas.
| Métrico | Amazon EMR 7.12 en EC2 | Amazon EMR 7.5 en EC2 | Apache Spark 3.5.6 y Apache Iceberg 1.10.0 de código descubierto |
| Tiempo de ejecución promedio en segundos | 1349.62 | 1535.62 | 6113.92 |
| Media geométrica sobre consultas en segundos | 7.45910 | 8.30046 | 22.31854 |
| Costo* | $4.81 | $5.47 | $17.65 |
*Las estimaciones de costos detalladas se analizan más delante en esta publicación.
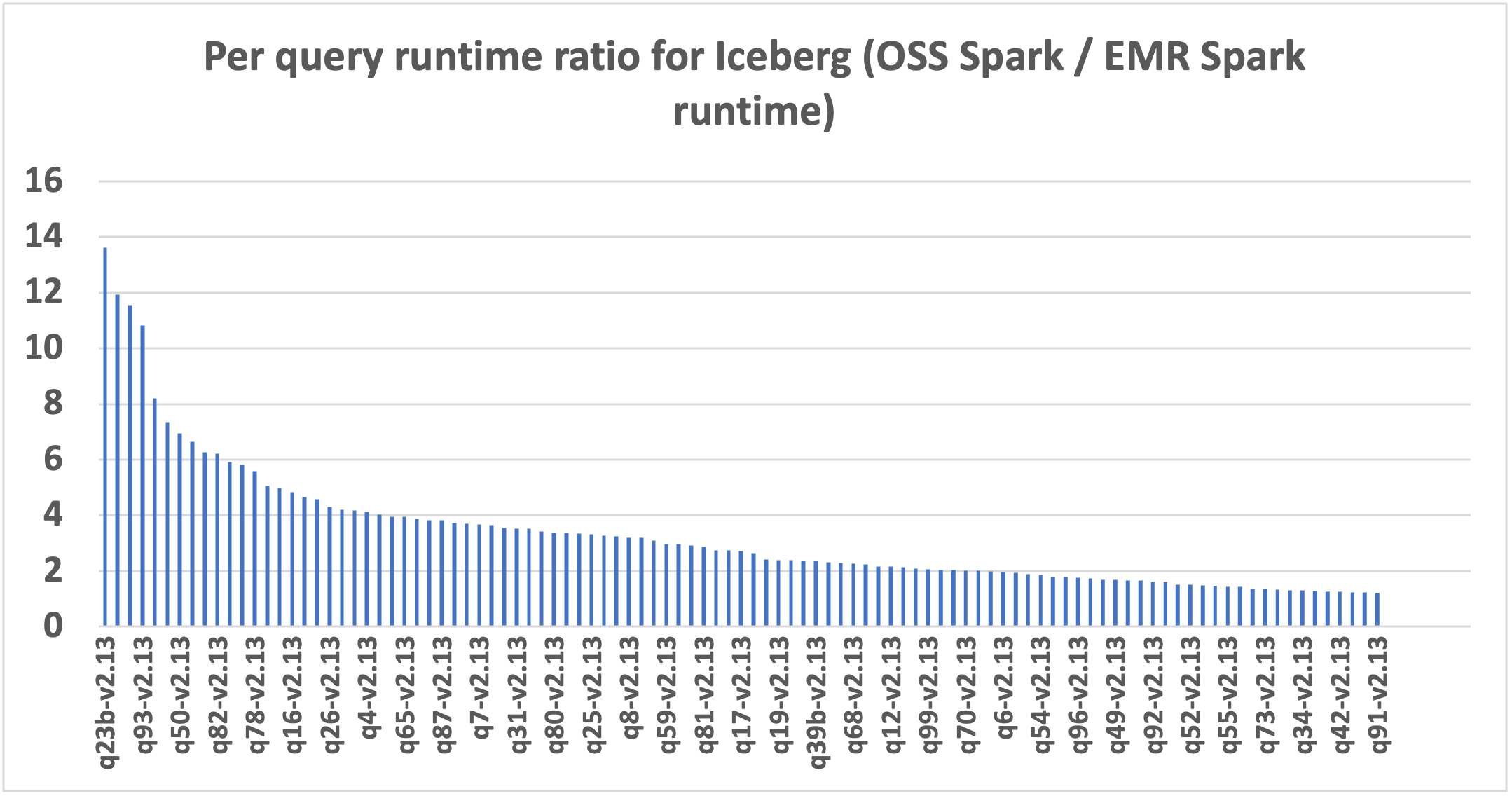
El futuro dibujo demuestra la perfeccionamiento del rendimiento por consulta de Amazon EMR 7.12 en relación con el código descubierto Spark 3.5.6 y Iceberg 1.10.0. El talento de la celeridad varía de una consulta a otra, siendo la más rápida hasta 13,6 veces más rápida para q23b, y Amazon EMR superó a Spark de código descubierto con tablas Iceberg. El eje horizontal organiza las consultas de relato de TPC-DS de 3 TB en orden descendente según la perfeccionamiento de rendimiento observada con Amazon EMR, y el eje erecto representa la magnitud de esta celeridad como una proporción.
Desglose de la comparación de costos
Nuestro punto de relato proporciona el tiempo de ejecución total y los datos de la media geométrica para evaluar el rendimiento de Spark e Iceberg en un marco confuso de soporte de decisiones del mundo efectivo. Para obtener información adicional, además examinamos el aspecto de los costos. Calculamos estimaciones de costos utilizando fórmulas que tienen en cuenta las instancias EC2 On-Demand, Tienda de bloques elásticos de Amazon (Amazon EBS) y gastos de Amazon EMR.
- Costo de Amazon EC2 (incluye costo de SSD) = número de instancias * tarifa por hora de r5d.4xlarge * tiempo de ejecución del trabajo en horas
- Tarifa por hora 4xlarge = $1,152 por hora
- Costo raíz de Amazon EBS = número de instancias * tarifa de Amazon EBS por GB por hora * tamaño del convexidad raíz de EBS * tiempo de ejecución del trabajo en horas
- Costo de Amazon EMR = número de instancias * costo de r5d.4xlarge Amazon EMR * tiempo de ejecución del trabajo en horas
- Costo de Amazon EMR 4xlarge = $0,27 por hora
- Costo total = costo de Amazon EC2 + costo raíz de Amazon EBS + costo de Amazon EMR
Los cálculos revelan que el punto de relato de Amazon EMR 7.12 produce una perfeccionamiento de rentabilidad 3,6 veces anciano que el código descubierto Spark 3.5.6 y Iceberg 1.10.0 al ejecutar el trabajo de punto de relato.
| Métrico | AmazonEMR 7.12 | AmazonEMR 7.5 | Apache Spark 3.5.6 y Apache Iceberg 1.10.0 de código descubierto |
| Tiempo de ejecución en segundos | 1349.62 | 1535.62 | 6113.92 |
|
Número de instancias EC2 (Incluye nodo primario) |
9 | 9 | 9 |
| Tamaño de Amazon EBS | 20 gb | 20 gb | 20 gb |
|
AmazonEC2 (Costo total del tiempo de ejecución) |
$3.89 | $4.42 | $17.61 |
| Costo de Amazon EBS | $0.01 | $0.01 | $0.04 |
| Costo de Amazon EMR | $0.91 | $1.04 | $0 |
| Costo total | $4.81 | $5.47 | $17.65 |
| Economía de costos | Amazon EMR 7.12 es 3,6 veces mejor | Amazon EMR 7.5 es 3,2 veces mejor | Almohadilla |
Encima de las métricas basadas en el tiempo analizadas hasta ahora, los datos de los registros de eventos de Spark muestran que Amazon EMR escaneó aproximadamente 4,3 veces menos datos de Amazon S3 y 5,3 veces menos registros que la traducción de código descubierto en el punto de relato TPC-DS de 3 TB. Esta reducción en el escaneo de datos de Amazon S3 contribuye directamente al capital de costos para las cargas de trabajo de Amazon EMR.
Ejecute pruebas comparativas de Apache Spark de código descubierto en tablas Apache Iceberg
Usamos clústeres EC2 separados, cada uno equipado con 9 instancias r5d.4xlarge, para probar Spark 3.5.6 de código descubierto y Amazon EMR 7.12 para la carga de trabajo Iceberg. El nodo principal estaba equipado con 16 vCPU y 128 GB de memoria, y los 8 nodos trabajadores juntos tenían 128 vCPU y 1024 GB de memoria. Realizamos pruebas utilizando la configuración predeterminada de Amazon EMR para mostrar la experiencia de sucesor típica y ajustamos mínimamente la configuración de Spark e Iceberg para proseguir una comparación equilibrada.
La futuro tabla resume las configuraciones de Amazon EC2 para el nodo principal y 8 nodos trabajadores de tipo r5d.4xlarge.
| Instancia EC2 | CPU imaginario | Memoria (GiB) | Almacenamiento de instancias (GB) | Prominencia raíz de EBS (GB) |
| r5d.4xgrande | 16 | 128 | 2 SSD NVMe de 300 | 20GB |
Requisitos previos
Se requieren los siguientes requisitos previos para ejecutar la evaluación comparativa:
- Usando las instrucciones en el repositorio de GitHub emr-spark-benchmarkconfigure los datos de origen de TPC-DS en su depósito S3 y en su computadora restringido.
- Cree la aplicación de relato siguiendo los pasos proporcionados en Pasos para crear una aplicación de ensamblaje Spark-benchmark y copie la aplicación de relato a su depósito S3. Alternativamente, copie Spark-benchmark-ensamblaje-3.5.6.jar a su depósito S3.
- Cree tablas Iceberg a partir de los datos fuente de TPC-DS. Siga las instrucciones en GitHub para crear tablas Iceberg utilizando el catálogo de Hadoop. Por ejemplo, el futuro código utiliza un clúster de Amazon EMR 7.12 con Iceberg gestor para crear las tablas:
Nota: La ubicación del almacén del catálogo de Hadoop y el nombre de la colchoneta de datos del paso preparatorio. Usamos las mismas tablas Iceberg para ejecutar pruebas comparativas con Amazon EMR 7.12 y Spark de código descubierto.
Esta aplicación de relato está construida a partir de la rama. tpcds-v2.13_iceberg. Si está creando una nueva aplicación de relato, cambie a la rama correcta a posteriori de descargar el código fuente del repositorio de GitHub.
Cree y configure un clúster YARN en Amazon EC2
Para comparar el rendimiento de Iceberg entre Amazon EMR en Amazon EC2 y Spark de código descubierto en Amazon EC2, siga las instrucciones del repositorio de GitHub emr-spark-benchmark para crear un clúster Spark de código descubierto en Amazon EC2 utilizando Flintrock con 8 nodos trabajadores.
Según la selección del clúster para esta prueba, se utilizan las siguientes configuraciones:
Asegúrate de reemplazar el registrador de posición
Ejecute el punto de relato TPC-DS con Apache Spark 3.5.6 y Apache Iceberg 1.10.0
Complete los siguientes pasos para ejecutar el punto de relato TPC-DS:
- Inicie sesión en el nodo principal del clúster de código descubierto usando
flintrock login $CLUSTER_NAME. - Envíe su trabajo Spark:
- Elija la ubicación correcta del almacén del catálogo de Iceberg y la colchoneta de datos que tenga las tablas de Iceberg creadas.
- Los resultados se crean en
s3://./benchmark_run - Puedes seguir el progreso en
/media/ephemeral0/spark_run.log.
Resumir los resultados
Una vez finalizado el trabajo de Spark, recupere el archivo de resultados de la prueba del depósito S3 de salida en s3://. Esto se puede hacer a través de la consola de Amazon S3 navegando a la ubicación del depósito especificada o utilizando el Interfaz de diámetro de comandos de Amazone (AWS CLI). La aplicación de relato Spark organiza los datos creando una carpeta de marca de tiempo y colocando un archivo de recapitulación adentro de una carpeta etiquetada summary.csv. Los archivos CSV de salida contienen 4 columnas sin encabezados:
- Nombre de la consulta
- tiempo medio
- tiempo minimo
- tiempo mayor
Con los datos de 3 ejecuciones de prueba separadas con 1 iteración cada vez, podemos calcular el promedio y la media geométrica de los tiempos de ejecución de relato.
Ejecute el punto de relato TPC-DS con el tiempo de ejecución de Amazon EMR para Apache Spark
La mayoría de las instrucciones son similares a Pasos para ejecutar Spark Benchmarking con algunos detalles específicos de Iceberg.
Requisitos previos
Complete los siguientes pasos previos:
- Valer
aws configurepara configurar el shell de AWS CLI para que apunte a la cuenta de AWS de evaluación comparativa. Referirse a Configurar la CLI de AWS para obtener instrucciones. - Cargue el archivo JAR de la aplicación de relato en Amazon S3.
Implemente el clúster de Amazon EMR y ejecute el trabajo de relato
Complete los siguientes pasos para ejecutar el trabajo de relato:
- Utilice el comando AWS CLI como se muestra en Implemente EMR en EC2 Cluster y ejecute un trabajo de relato para implementar un Amazon EMR en un clúster EC2. Asegúrate de habilitar Iceberg. Ver Crear un reunión de Iceberg para más detalles. Elija la traducción correcta de Amazon EMR, el tamaño del convexidad raíz y la misma configuración de capital que la configuración de código descubierto de Flintrock. Referirse a crear-cluster para obtener una descripción detallada de las opciones de AWS CLI.
- Almacene el ID del clúster de la respuesta. Necesitamos esto para el futuro paso.
- Envíe el trabajo de relato en Amazon EMR utilizando
add-stepsdesde la CLI de AWS:- Reemplazar
- La aplicación de relato está en
s3://./spark-benchmark-assembly-3.5.6.jar - Elija la ubicación correcta del almacén del catálogo de Iceberg y la colchoneta de datos que tenga las tablas de Iceberg creadas. Este debería ser el mismo que el utilizado para la ejecución comparativa de código descubierto TPC-DS.
- Los resultados estarán en
s3://./benchmark_run
- Reemplazar
Resumir los resultados
Una vez completado el paso, puede ver el resultado de relato resumido en s3:// de la misma forma que la ejecución preparatorio y calcule el promedio y la media geométrica de los tiempos de ejecución de la consulta.
Lustrar
Para ayudar a evitar cargos futuros, elimine los capital que creó siguiendo las instrucciones proporcionadas en el Sección de destreza del repositorio de GitHub.
Breviario
Amazon EMR optimiza el tiempo de ejecución de Spark cuando se utiliza con tablas Iceberg, logrando un rendimiento 4,5 veces más rápido que el código descubierto Apache Spark 3.5.6 y Apache Iceberg 1.10.0 con Amazon EMR 7.12 en TPC-DS 3 TB, v2.13. Esto representa un avance significativo con respecto a Amazon EMR 7.5, que brindó un rendimiento 3,6 veces más rápido y cierra la brecha con el rendimiento de parquet en Amazon EMR para que los clientes puedan utilizar los beneficios de Iceberg sin una penalización en el rendimiento.
Le recomendamos que se mantenga actualizado con las últimas versiones de Amazon EMR para beneficiarse plenamente de las mejoras continuas de rendimiento.
Para mantenerse informado, suscríbase al Fuente RSS para el blog de Big Data de AWSdonde puede encontrar actualizaciones sobre el tiempo de ejecución de Amazon EMR para Spark e Iceberg, así como sugerencias sobre prácticas recomendadas de configuración y recomendaciones de ajuste.
Sobre los autores
 Atul Félix Payapilly es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Atul Félix Payapilly es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Akshaya KP es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Akshaya KP es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Hari Kishore Chaparala es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
Hari Kishore Chaparala es ingeniero de mejora de software para Amazon EMR en Amazon Web Services.
 Giovanni Mateo es el directivo senior del reunión Amazon EMR Spark and Iceberg.
Giovanni Mateo es el directivo senior del reunión Amazon EMR Spark and Iceberg.