
Los modelos de idioma neuronal (LM) a gran escalera se destacan en la realización de tareas similares a sus datos de entrenamiento y variaciones básicas de esas tareas. Sin requisa, es necesario aclarar si los LM pueden resolver nuevos problemas que impliquen razonamiento, planificación o manipulación de cadenas no triviales que difieran de sus datos previos al entrenamiento. Esta pregunta es fundamental para comprender las nuevas capacidades de adquisición de habilidades de los sistemas de IA actuales, que se han propuesto como una medida secreto de la inteligencia. Es difícil obtener una respuesta correcta para tareas complejas y novedosas simplemente tomando muestras de un LM. Investigaciones recientes han demostrado que el rendimiento de LM se puede mejorar aumentando el proceso de decodificación de LM con cálculos adicionales del tiempo de prueba, pero además plantean algunos desafíos.
Se han desarrollado enfoques existentes para aumentar los LM y mejorar su desempeño en tareas complejas y novedosas. Una de esas estrategias es el entrenamiento en el momento de la prueba (TTT), en el que los modelos se actualizan a través de pasos de gradiente explícitos basados en entradas en el momento de la prueba. Este método se diferencia del ajuste fino standard en que opera en un régimen de datos extremadamente bajos utilizando un objetivo no supervisado en una sola entrada o un objetivo supervisado empollón a uno o dos ejemplos etiquetados en contexto. Sin requisa, el espacio de diseño para los enfoques TTT es vasto y existe una comprensión limitada de las opciones de diseño que son más efectivas para los modelos de idioma y el educación de tareas novedosas. Otro método es BARC, que combina enfoques de síntesis neuronal y de programas, logrando una precisión del 54,4% en una tarea de relato.
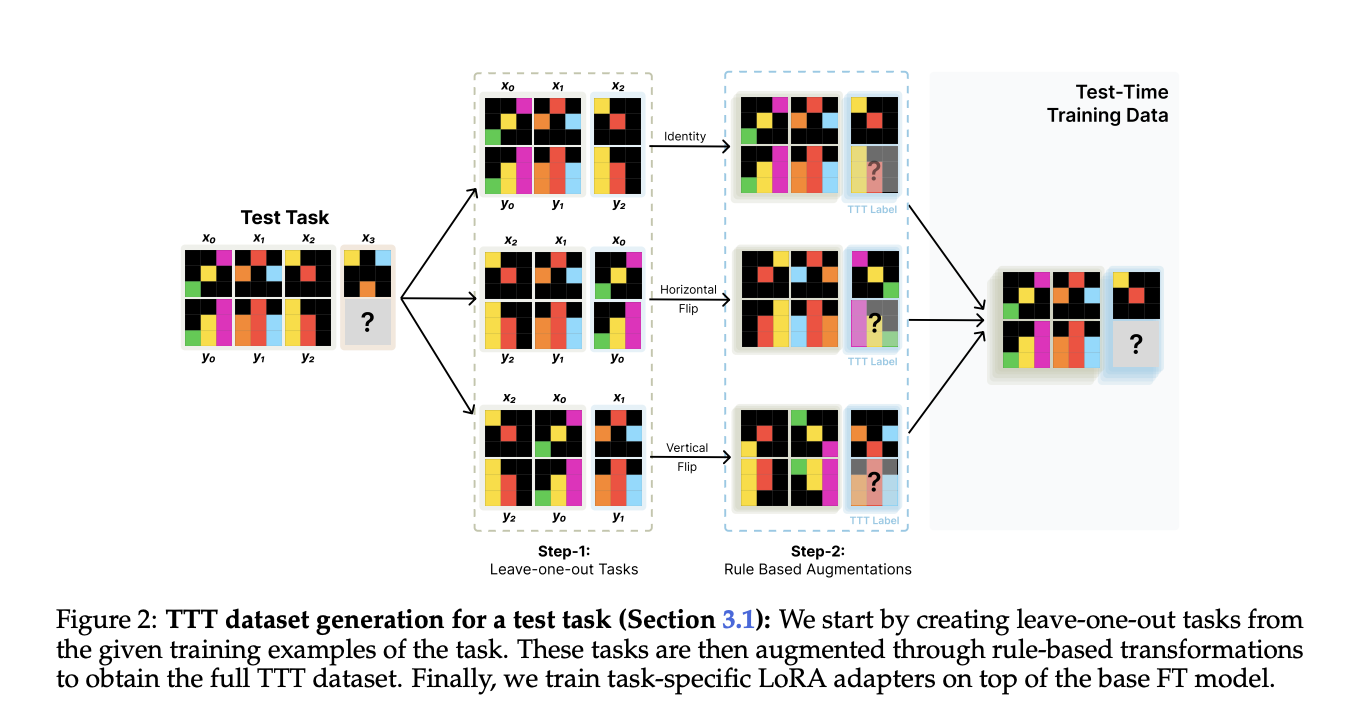
Investigadores del Instituto Tecnológico de Massachusetts han propuesto un enfoque que investiga la eficiencia del TTT para mejorar las capacidades de razonamiento de los modelos lingüísticos. El Corpus de Percepción y Razonamiento (ARC) se utiliza como punto de relato para observar con TTT. Los tres componentes cruciales para el éxito del TTT proporcionados en este documento son el ajuste original de tareas similares, el formato y los aumentos de las tareas auxiliares, y la capacitación por instancia. Encima, los investigadores descubrieron que TTT prosperidad significativamente el rendimiento en las tareas ARC, logrando una prosperidad de hasta 6 veces en la precisión en comparación con los modelos colchoneta ajustados. Al aplicar TTT a un maniquí de idioma de parámetros 8B, se logra una precisión del 53 % en el conjunto de firmeza pública de ARC, lo que prosperidad el estado del arte en casi un 25 % para enfoques públicos y puramente neuronales.
Para investigar el impacto de cada componente TTT, se utilizan un LM de parámetro 8B de los modelos Ardor-3 y modelos 1B y 3B de Ardor-3.2 durante la bloque y optimización del maniquí. La acomodo de rango bajo (LoRA) se utiliza para un entrenamiento en tiempo de prueba competente en parámetros, inicializando un conjunto separado de parámetros LoRA para cada tarea y entrenándolos en el conjunto de datos DTTT. Durante la evaluación competente de datos y formato, se seleccionan aleatoriamente 80 tareas ARC equilibradas del conjunto de firmeza ARC, incluidas 20 tareas fáciles, 20 medianas, 20 difíciles y 20 expertas. Encima, la DTTT está limitada a 250 ejemplos por tarea. Con esta configuración, todo el proceso de inferencia y TTT tarda aproximadamente 12 horas para 100 tareas de firmeza muestreadas aleatoriamente cuando se utiliza una GPU NVIDIA-A100.
La implementación principal de TTT se compara con varias líneas de colchoneta, incluidos modelos ajustados sin TTT (FT), datos de extremo a extremo (datos E2E) y enfoques TTT compartidos. Los resultados muestran que su método TTT es muy eficaz y prosperidad la precisión del maniquí adecuado aproximadamente 6 veces (del 5 % al 29 %). La estructura de la tarea auxiliar tiene un impacto significativo en la efectividad del TTT, ya que las tareas de educación en contexto superan a las tareas de un extremo a otro, lo que resulta en una caída relativa del rendimiento de 11 tareas (38%). Encima, la aniquilación de múltiples componentes de la optimización TTT revela que educarse un único adaptador LoRA en todas las tareas reduce el rendimiento en 7 tareas (24%), mientras que desavenir una pérdida en las demostraciones de salida prosperidad marginalmente el rendimiento (del 26% al 29%).
En conclusión, los investigadores investigaron el entrenamiento en tiempo de prueba (TTT) y demostraron que puede mejorar significativamente el rendimiento de LM en el popular conjunto de datos ARC. Los investigadores además desarrollan un proceso de inferencia aumentada que utiliza transformaciones invertibles para producir múltiples predicciones y luego emplea la autoconsistencia para optar a los mejores candidatos. Esta canalización aplica múltiples métodos de cálculo en tiempo de prueba, y cada componente contribuye positivamente. Encima, el canal TTT combinado con BARC logra resultados de última vivientes en el conjunto notorio de ARC y tiene un rendimiento comparable al de un ser humano promedio. Estos hallazgos sugieren que los métodos de tiempo de prueba podrían desempeñar un papel importante en el avance de la próxima vivientes de LM.
Mira el Papel y Página de GitHub. Todo el crédito por esta investigación va a los investigadores de este tesina. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(SEMINARIO WEB GRATUITO sobre IA) Implementación del procesamiento inteligente de documentos con GenAI en servicios financieros y transacciones inmobiliarias

Sajjad Ansari es un estudiante de extremo año de IIT Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA centrándose en comprender el impacto de las tecnologías de IA y sus implicaciones en el mundo existente. Su objetivo es articular conceptos complejos de IA de una forma clara y accesible.