
Detección de objetos es fundamental en inteligencia sintéticosirviendo como columna vertebral para numerosas aplicaciones de vanguardia. Desde vehículos autónomos y sistemas de vigilancia hasta imágenes médicas y verdad aumentada, la capacidad de identificar y emplazar objetos en imágenes y vídeos está transformando industrias en todo el mundo. La API de detección de objetos de TensorFlow, una útil potente y versátil, simplifica la creación de modelos robustos de detección de objetos. Al emplear esta API, los desarrolladores pueden entrenar modelos personalizados adaptados a evacuación específicas, lo que reduce significativamente el tiempo y la complejidad del progreso.
En esta gurú, exploraremos el proceso paso a paso de entrenar un maniquí de detección de objetos usando TensorFlow, centrándonos en la integración de conjuntos de datos de Universo Roboflowun rico repositorio de conjuntos de datos anotados diseñados para acelerar el progreso de la IA.
Objetivos de educación
- Aprenda a instalar y configurar TensorFlowEntorno API de detección de objetos para un entrenamiento de modelos apto.
- Comprenda cómo preparar y preprocesar conjuntos de datos para entrenamiento, utilizando el formato TFRecord.
- Obtenga experiencia en la selección y personalización de un maniquí de detección de objetos previamente entrenado para evacuación específicas.
- Aprenda a ajustar los archivos de configuración de canalizaciones y afinar los parámetros del maniquí para optimizar el rendimiento.
- Domine el proceso de capacitación, incluido el manejo de puntos de control y la evaluación del rendimiento del maniquí durante la capacitación.
- Comprenda cómo exportar el maniquí entrenado para inferencia e implementación en aplicaciones del mundo efectivo.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Implementación paso a paso de la detección de objetos con TensorFlow
En esta sección, lo guiaremos a través de una implementación paso a paso de la detección de objetos usando TensorFlow, guiándolo desde la configuración hasta la implementación.
Paso 1: configurar el entorno
La API de detección de objetos de TensorFlow requiere varias dependencias. Comience clonando el repositorio de modelos de TensorFlow:
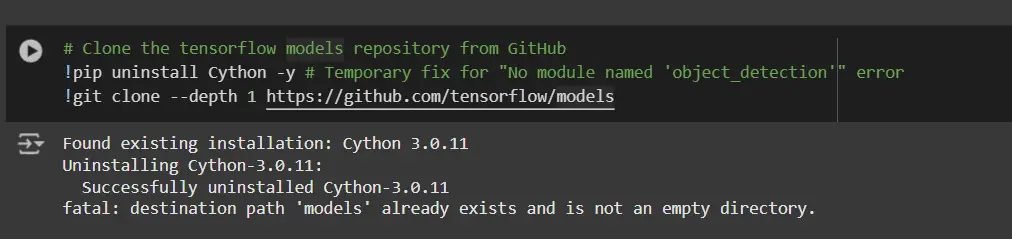
# Clone the tensorflow models repository from GitHub
!pip uninstall Cython -y # Temporary fix for "No module named 'object_detection'" error
!git clone --depth 1 https://github.com/tensorflow/models- Desinstalar Cython: Este paso garantiza que no haya conflictos con la biblioteca Cython durante la instalación.
- Clonar el repositorio de modelos de TensorFlow: Este repositorio contiene los modelos oficiales de TensorFlow, incluida la API de detección de objetos.
Copie los archivos de configuración y modifique el archivo setup.py
# Copy setup files into models/research folder
%%bash
cd models/research/
protoc object_detection/protos/*.proto --python_out=.
#cp object_detection/packages/tf2/setup.py .
# Modify setup.py file to install the tf-models-official repository targeted at TF v2.8.0
import re
with open('/content/models/research/object_detection/packages/tf2/setup.py') as f:
s = f.read()
with open('/content/models/research/setup.py', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('tf-models-official>=2.5.1',
'tf-models-official==2.8.0', s)
f.write(s)¿Por qué es esto necesario?
- Compilación de buffers de protocolo: La API de detección de objetos utiliza archivos .proto para constreñir configuraciones de modelos y estructuras de datos. Estos deben compilarse en código Python para funcionar.
- Compatibilidad de versiones de dependencia: TensorFlow y sus dependencias evolucionan. El uso de tf-models-official>=2.5.1 puede instalar sin darse cuenta una interpretación incompatible para TensorFlow v2.8.0.
- Configurar explícitamente tf-models-official==2.8.0 evita posibles conflictos de versiones y garantiza la estabilidad.
Instalación de bibliotecas de dependencia
Los modelos de TensorFlow suelen reconocer de versiones de biblioteca específicas. Arreglar la interpretación de TensorFlow garantiza una integración fluida.
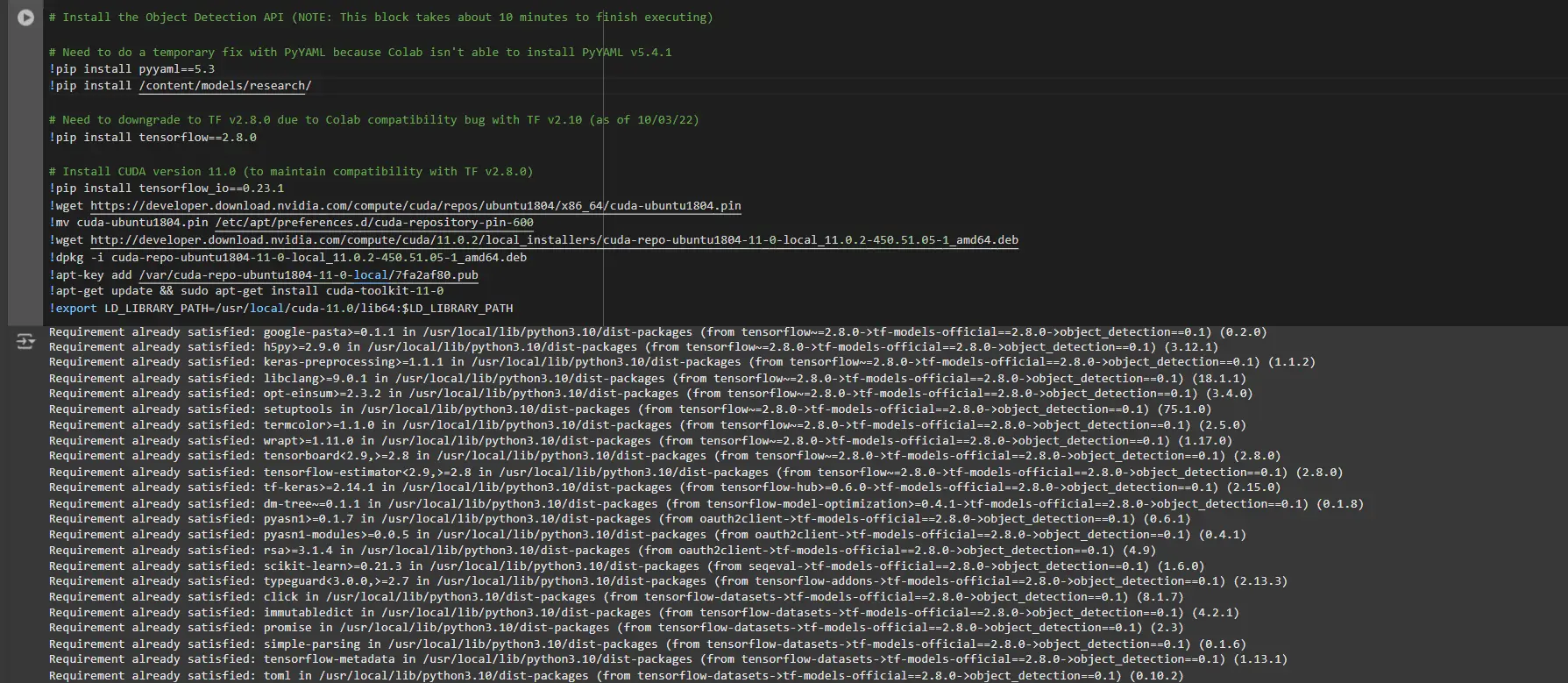
# Install the Object Detection API
# Need to do a temporary fix with PyYAML because Colab isn't able to install PyYAML v5.4.1
!pip install pyyaml==5.3
!pip install /content/models/research/
# Need to downgrade to TF v2.8.0 due to Colab compatibility bug with TF v2.10 (as of 10/03/22)
!pip install tensorflow==2.8.0
# Install CUDA version 11.0 (to maintain compatibility with TF v2.8.0)
!pip install tensorflow_io==0.23.1
!wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
!mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
!wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!dpkg -i cuda-repo-ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
!apt-key add /var/cuda-repo-ubuntu1804-11-0-local/7fa2af80.pub
!apt-get update && sudo apt-get install cuda-toolkit-11-0
!export LD_LIBRARY_PATH=/usr/circunscrito/cuda-11.0/lib64:$LD_LIBRARY_PATHMientras ejecuta este monolito, debe reiniciar las sesiones nuevamente y ejecutar este monolito de código nuevamente para instalar correctamente todas las dependencias. Esto instalará todas las dependencias con éxito.
Instalación de una interpretación adecuada de la biblioteca protobuf para resolver problemas de dependencia
!pip install protobuf==3.20.1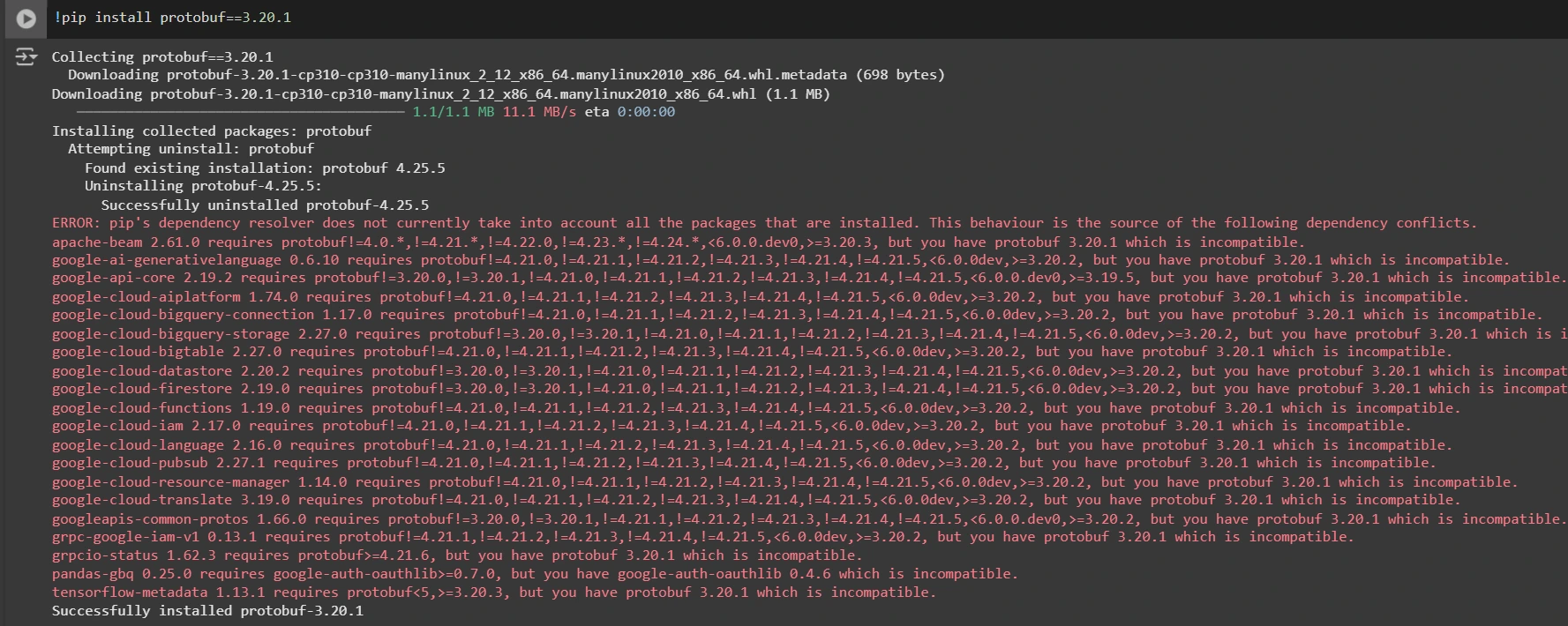
Paso 2: revisar el entorno y las instalaciones
Para confirmar que la instalación funciona, ejecute la posterior prueba:
# Run Model Bulider Test file, just to verify everything's working properly
!python /content/models/research/object_detection/builders/model_builder_tf2_test.py
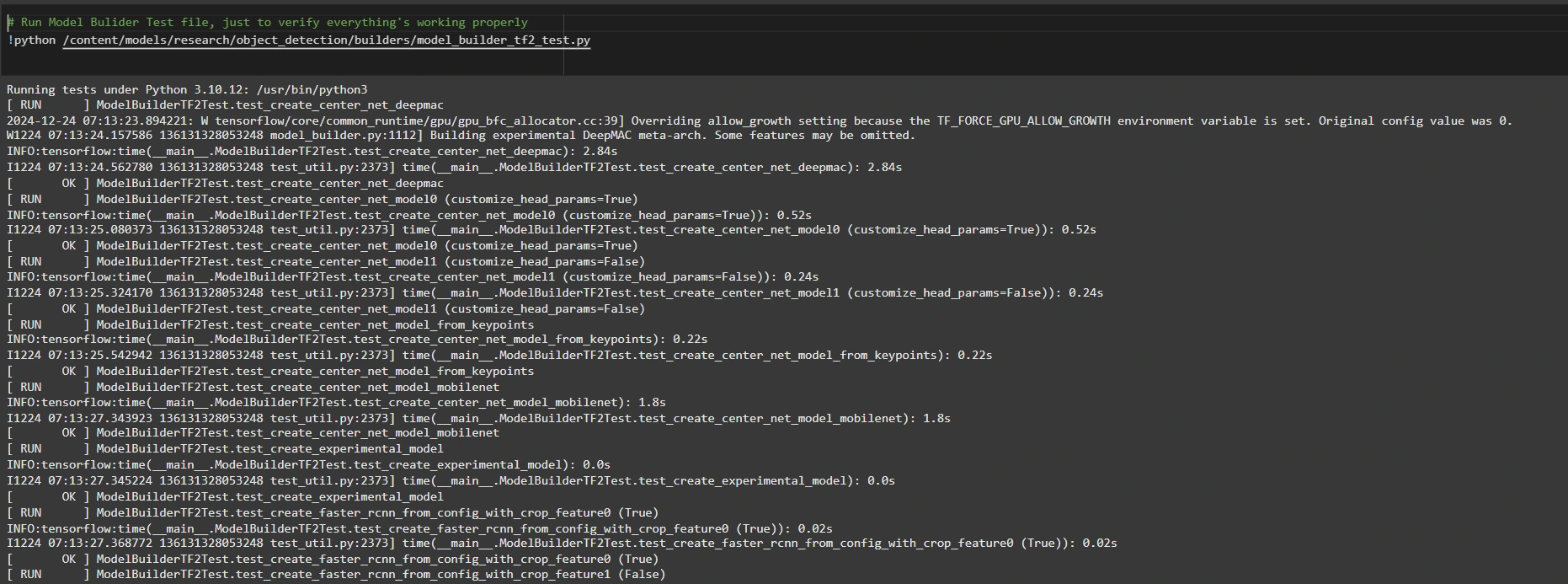
Si no aparecen errores, su configuración está completa. Ahora hemos completado la configuración con éxito.
Paso 3: preparar los datos de entrenamiento
Para este tutorial, usaremos el “Detección de personas” conjunto de datos de Universo Roboflow. Sigue estos pasos para prepararlo:
Visite la página del conjunto de datos:

Bifurque el conjunto de datos en su espacio de trabajo para que sea accesible para su personalización.
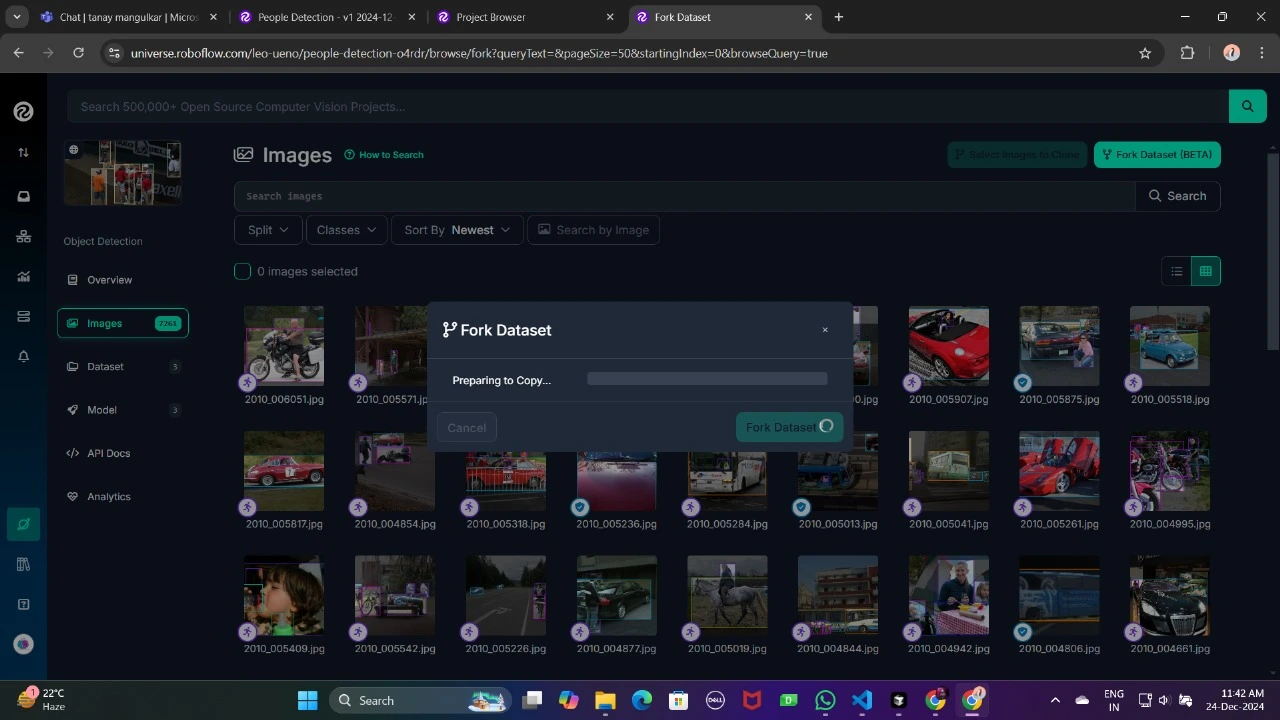
Genere una interpretación del conjunto de datos para finalizar sus configuraciones de preprocesamiento, como el aumento y el cambio de tamaño.
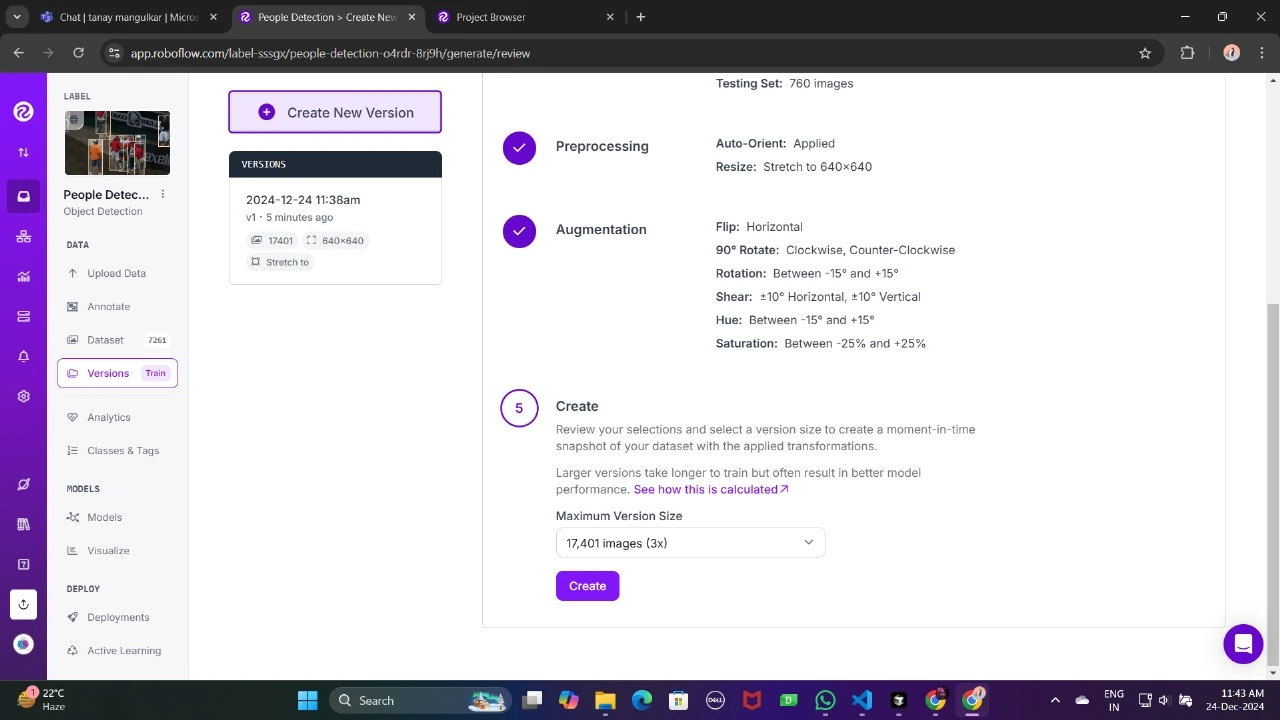
Ahora, descárgalo en formato TFRecord, que es un formato binario optimizado para los flujos de trabajo de TensorFlow. TFRecord almacena datos de modo apto y permite a TensorFlow descubrir grandes conjuntos de datos durante el entrenamiento con una sobrecarga mínima.
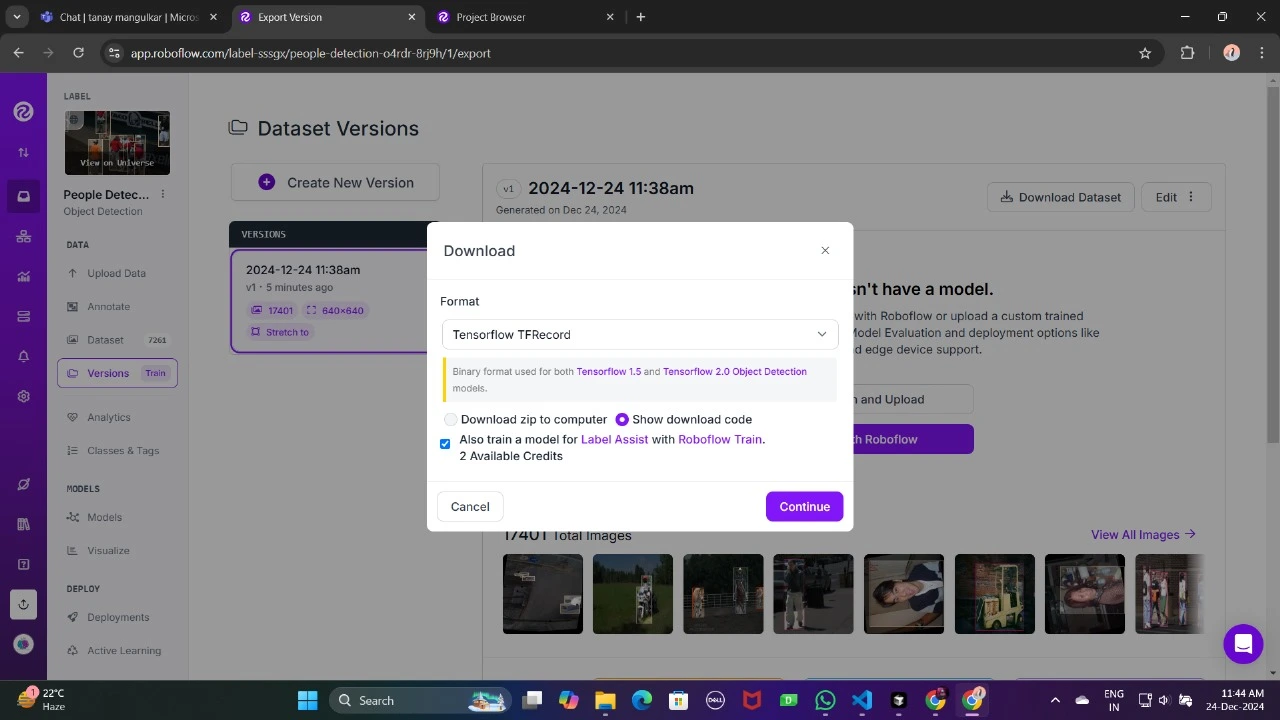
Una vez descargado, coloque los archivos del conjunto de datos en su Google Drive, monte su código en su dispositivo y cargue esos archivos en el código para usarlo.
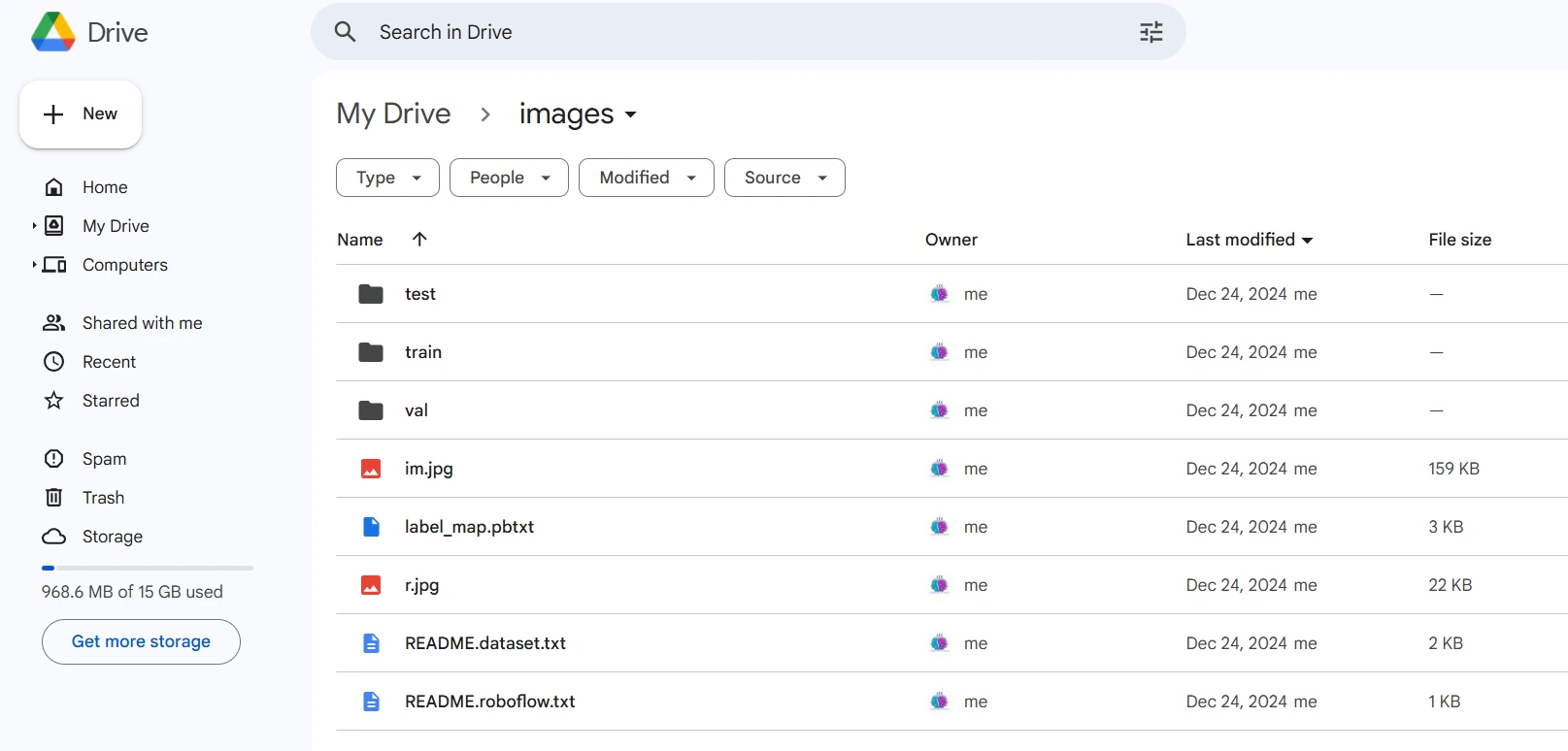
from google.colab import drive
drive.mount('/content/gdrive')
train_record_fname="/content/gdrive/MyDrive/images/train/train.tfrecord"
val_record_fname="/content/gdrive/MyDrive/images/test/test.tfrecord"
label_map_pbtxt_fname="/content/gdrive/MyDrive/images/label_map.pbtxt"
Paso 4: configurar la configuración de entrenamiento
Ahora es el momento de establecer la configuración para el maniquí de detección de objetos. Para este ejemplo, usaremos el maniquí eficientedet-d0. Puede nominar entre otros modelos como ssd-mobilenet-v2 o ssd-mobilenet-v2-fpnlite-320, pero para esta gurú, nos centraremos en eficientedet-d0.
# Change the chosen_model variable to deploy different models available in the TF2 object detection zoo
chosen_model="efficientdet-d0"
MODELS_CONFIG = {
'ssd-mobilenet-v2': {
'model_name': 'ssd_mobilenet_v2_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_320x320_coco17_tpu-8.tar.gz',
},
'efficientdet-d0': {
'model_name': 'efficientdet_d0_coco17_tpu-32',
'base_pipeline_file': 'ssd_efficientdet_d0_512x512_coco17_tpu-8.config',
'pretrained_checkpoint': 'efficientdet_d0_coco17_tpu-32.tar.gz',
},
'ssd-mobilenet-v2-fpnlite-320': {
'model_name': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8',
'base_pipeline_file': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.config',
'pretrained_checkpoint': 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz',
},
}
model_name = MODELS_CONFIG(chosen_model)('model_name')
pretrained_checkpoint = MODELS_CONFIG(chosen_model)('pretrained_checkpoint')
base_pipeline_file = MODELS_CONFIG(chosen_model)('base_pipeline_file')Luego descargamos los pesos previamente entrenados y el archivo de configuración correspondiente al maniquí electo:
# Create "mymodel" folder for holding pre-trained weights and configuration files
%mkdir /content/models/mymodel/
%cd /content/models/mymodel/
# Download pre-trained model weights
import tarfile
download_tar="http://download.tensorflow.org/models/object_detection/tf2/20200711/" + pretrained_checkpoint
!wget {download_tar}
tar = tarfile.open(pretrained_checkpoint)
tar.extractall()
tar.close()
# Download training configuration file for model
download_config = 'https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/configs/tf2/' + base_pipeline_file
!wget {download_config}
Posteriormente de esto, configuramos la cantidad de pasos para el entrenamiento y el tamaño del conjunto según el maniquí seleccionado:
# Set training parameters for the model
num_steps = 4000
if chosen_model == 'efficientdet-d0':
batch_size = 8
else:
batch_size = 8
Puede aumentar y disminuir num_steps y lote_size según sus requisitos.
Paso 5: Modificar el archivo de configuración de Pipeline
Necesitamos personalizar el archivo pipeline.config con las rutas a nuestro conjunto de datos y parámetros del maniquí. El archivo pipeline.config contiene varias configuraciones, como el tamaño del conjunto, la cantidad de clases y puntos de control de ajuste fino. Realizamos estas modificaciones leyendo la plantilla y reemplazando los campos relevantes:
# Set file locations and get number of classes for config file
pipeline_fname="/content/models/mymodel/" + base_pipeline_file
fine_tune_checkpoint="/content/models/mymodel/" + model_name + '/checkpoint/ckpt-0'
def get_num_classes(pbtxt_fname):
from object_detection.utils import label_map_util
label_map = label_map_util.load_labelmap(pbtxt_fname)
categories = label_map_util.convert_label_map_to_categories(
label_map, max_num_classes=90, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
return len(category_index.keys())
num_classes = get_num_classes(label_map_pbtxt_fname)
print('Total classes:', num_classes)
# Create custom configuration file by writing the dataset, model checkpoint, and training parameters into the pulvínulo pipeline file
import re
%cd /content/models/mymodel
print('writing custom configuration file')
with open(pipeline_fname) as f:
s = f.read()
with open('pipeline_file.config', 'w') as f:
# Set fine_tune_checkpoint path
s = re.sub('fine_tune_checkpoint: ".*?"',
'fine_tune_checkpoint: "{}"'.format(fine_tune_checkpoint), s)
# Set tfrecord files for train and test datasets
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/train)(.*?")', 'input_path: "{}"'.format(train_record_fname), s)
s = re.sub(
'(input_path: ".*?)(PATH_TO_BE_CONFIGURED/val)(.*?")', 'input_path: "{}"'.format(val_record_fname), s)
# Set label_map_path
s = re.sub(
'label_map_path: ".*?"', 'label_map_path: "{}"'.format(label_map_pbtxt_fname), s)
# Set batch_size
s = re.sub('batch_size: (0-9)+',
'batch_size: {}'.format(batch_size), s)
# Set training steps, num_steps
s = re.sub('num_steps: (0-9)+',
'num_steps: {}'.format(num_steps), s)
# Set number of classes num_classes
s = re.sub('num_classes: (0-9)+',
'num_classes: {}'.format(num_classes), s)
# Change fine-tune checkpoint type from "classification" to "detection"
s = re.sub(
'fine_tune_checkpoint_type: "classification"', 'fine_tune_checkpoint_type: "{}"'.format('detection'), s)
# If using ssd-mobilenet-v2, reduce learning rate (because it's too high in the default config file)
if chosen_model == 'ssd-mobilenet-v2':
s = re.sub('learning_rate_base: .8',
'learning_rate_base: .08', s)
s = re.sub('warmup_learning_rate: 0.13333',
'warmup_learning_rate: .026666', s)
# If using efficientdet-d0, use fixed_shape_resizer instead of keep_aspect_ratio_resizer (because it isn't supported by TFLite)
if chosen_model == 'efficientdet-d0':
s = re.sub('keep_aspect_ratio_resizer', 'fixed_shape_resizer', s)
s = re.sub('pad_to_max_dimension: true', '', s)
s = re.sub('min_dimension', 'height', s)
s = re.sub('max_dimension', 'width', s)
f.write(s)
# (Optional) Display the custom configuration file's contents
!cat /content/models/mymodel/pipeline_file.config
# Set the path to the custom config file and the directory to store training checkpoints in
pipeline_file="/content/models/mymodel/pipeline_file.config"
model_dir="/content/training/"
Paso 6: entrenar el maniquí
Ahora podemos entrenar el maniquí utilizando el archivo de configuración de canalización personalizado. El script de entrenamiento guardará puntos de control, que puede utilizar para evaluar el rendimiento de su maniquí:
# Run training!
!python /content/models/research/object_detection/model_main_tf2.py
--pipeline_config_path={pipeline_file}
--model_dir={model_dir}
--alsologtostderr
--num_train_steps={num_steps}
--sample_1_of_n_eval_examples=1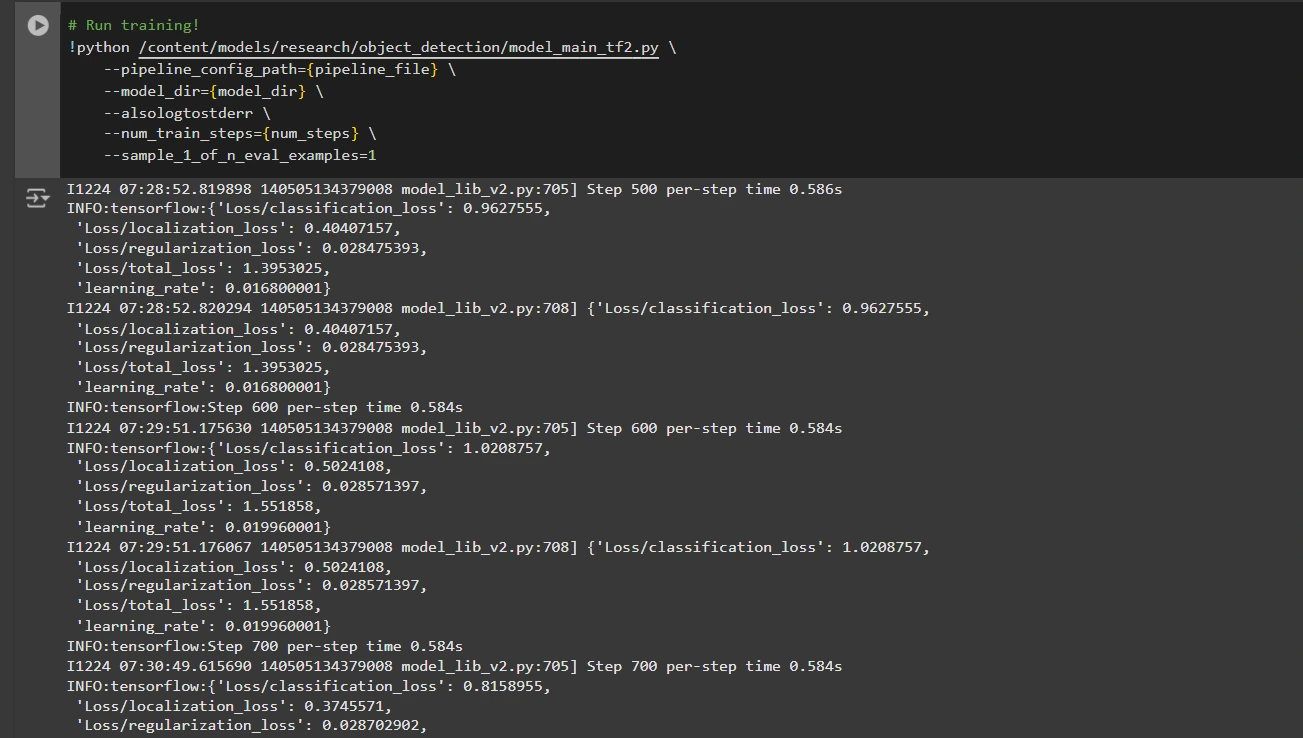
Paso 7: guarde el maniquí entrenado
Una vez completado el entrenamiento, exportamos el maniquí entrenado para que pueda estilarse para inferencias. Usamos el script exporter_main_v2.py para exportar el maniquí:
!python /content/models/research/object_detection/exporter_main_v2.py
--input_type image_tensor
--pipeline_config_path {pipeline_file}
--trained_checkpoint_dir {model_dir}
--output_directory /content/exported_model
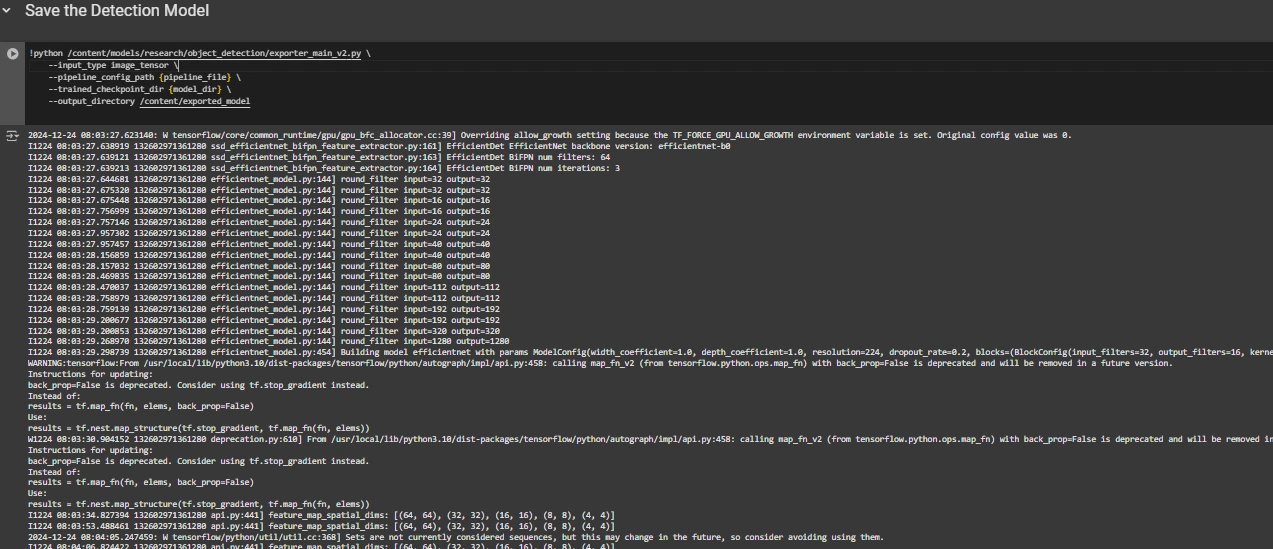
Finalmente, comprimimos el maniquí exportado en un archivo zip para descargarlo fácilmente y luego usted puede descargar el archivo zip que contiene su maniquí entrenado:
import shutil
# Path to the exported model folder
exported_model_path="/content/exported_model"
# Path where the zip file will be saved
zip_file_path="/content/exported_model.zip"
# Create a zip file of the exported model folder
shutil.make_archive(zip_file_path.replace('.zip', ''), 'zip', exported_model_path)
# Download the zip file using Google Colab's file download utility
from google.colab import files
files.download(zip_file_path)
Puede utilizar estos archivos de maniquí descargados para probarlos en imágenes no vistas o en sus aplicaciones según sus evacuación.
Puedes consultar esto: cuaderno de colaboración para código detallado
Conclusión
En conclusión, esta gurú le brinda el conocimiento y las herramientas necesarias para entrenar un maniquí de detección de objetos utilizando la API de detección de objetos de TensorFlow, aprovechando conjuntos de datos de Roboflow Universe para una rápida personalización. Si sigue los pasos descritos, puede preparar sus datos de modo efectiva, configurar el proceso de capacitación, aspirar el maniquí correcto y ajustarlo para satisfacer sus evacuación específicas. Encima, la capacidad de exportar e implementar su maniquí entrenado abre amplias posibilidades para aplicaciones del mundo efectivo, ya sea en vehículos autónomos, imágenes médicas o sistemas de vigilancia. Este flujo de trabajo le permite crear sistemas de detección de objetos potentes y escalables con complejidad limitada y un tiempo de implementación más rápido.
Conclusiones esencia
- La API de detección de objetos de TensorFlow ofrece un situación flexible para crear modelos de detección de objetos personalizados con opciones previamente entrenadas, lo que reduce el tiempo y la complejidad del progreso.
- El formato TFRecord es esencial para el manejo apto de datos, especialmente con grandes conjuntos de datos en TensorFlow, lo que permite un entrenamiento rápido y una sobrecarga mínima.
- Los archivos de configuración de canalización son cruciales para afinar y ajustar el maniquí para que funcione con su conjunto de datos específico y las características de rendimiento deseadas.
- Los modelos previamente entrenados como eficientedet-d0 y ssd-mobilenet-v2 brindan puntos de partida sólidos para entrenar modelos personalizados, y cada uno tiene fortalezas específicas según el caso de uso y las limitaciones de medios.
- El proceso de capacitación implica la diligencia de parámetros como el tamaño del conjunto, la cantidad de pasos y los puntos de control del maniquí para certificar que el maniquí aprenda de modo óptima.
- Exportar el maniquí es esencial para utilizar el maniquí de detección de objetos entrenado en un maniquí del mundo efectivo que se está empaquetando y vivo para su implementación.
Preguntas frecuentes
R: La API de detección de objetos de TensorFlow es un situación flexible y de código despejado para crear, entrenar e implementar modelos de detección de objetos personalizados. Proporciona herramientas para ajustar modelos previamente entrenados y crear soluciones adaptadas a casos de uso específicos.
R: TFRecord es un formato de archivo binario optimizado para canalizaciones de TensorFlow. Permite un manejo apto de los datos, lo que garantiza una carga más rápida, una sobrecarga mínima de E/S y un entrenamiento más fluido, especialmente con grandes conjuntos de datos.
R: Estos archivos permiten una personalización perfecta del maniquí al constreñir parámetros como rutas de conjuntos de datos, tasa de educación, cimentación del maniquí y pasos de capacitación para cumplir con conjuntos de datos y objetivos de rendimiento específicos.
R: Seleccione EfficientDet-D0 para obtener un contrapeso entre precisión y eficiencia, ideal para dispositivos periféricos, y SSD-MobileNet-V2 para aplicaciones livianas y rápidas en tiempo efectivo, como aplicaciones móviles.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Soy Neha Dwivedi, una entusiasta de la ciencia de datos, graduada de la Universidad MIT World Peace, Pune. Me apasiona la ciencia de datos y las tendencias crecientes con ella. ¡Estoy emocionado de compartir ideas y cultivarse de esta comunidad!