
Ingresando a la era sin servidor
En este blog, compartimos el alucinación de construir un registro de artefactos optimizado sin servidor desde cero. Los objetivos principales son asegurar la distribución de la imagen del contenedor ambas escamas sin problemas bajo el tráfico sin servidor ruidoso y permanecen disponibles en escenarios desafiantes, como las importantes fallas de dependencia.
Los contenedores son el formato de implementación nativo de aglomeración flamante que cuenta con aislamiento, portabilidad y ricos ecosistemas de herramientas. Los servicios internos de Databricks se han ejecutado como contenedores desde 2017. Implementamos un esquema de código descubierto provecto y rico en rico como el registro de contenedores. Funcionó proporcionadamente, ya que los servicios generalmente se implementaron a un ritmo controlado.
Avancemos rápidamente hasta 2021, cuando Databricks comenzó a iniciar DBSQL sin servidor y modelos de productos, se esperaba que se aprovisionaran millones de máquinas virtuales cada día, y cada VM extraería más de 10 imágenes del registro de contenedores. A diferencia de otros servicios internos, el tráfico de extirpación de imágenes sin servidor es impulsado por el uso del cliente y puede alcanzar un linde superior mucho más detención.
La Figura 1 es una carga de tráfico de producción de 1 semana (por ejemplo, clientes que lanzan nuevos almacenes de datos o puntos finales de servicio ML) que muestra que el tráfico mayor sin servidor es más de 100 veces en comparación con el de los servicios internos.
Según nuestras pruebas de estrés, concluimos que el registro de contenedores de código descubierto no podía cumplir con los requisitos sin servidor.
Desafíos sin servidor
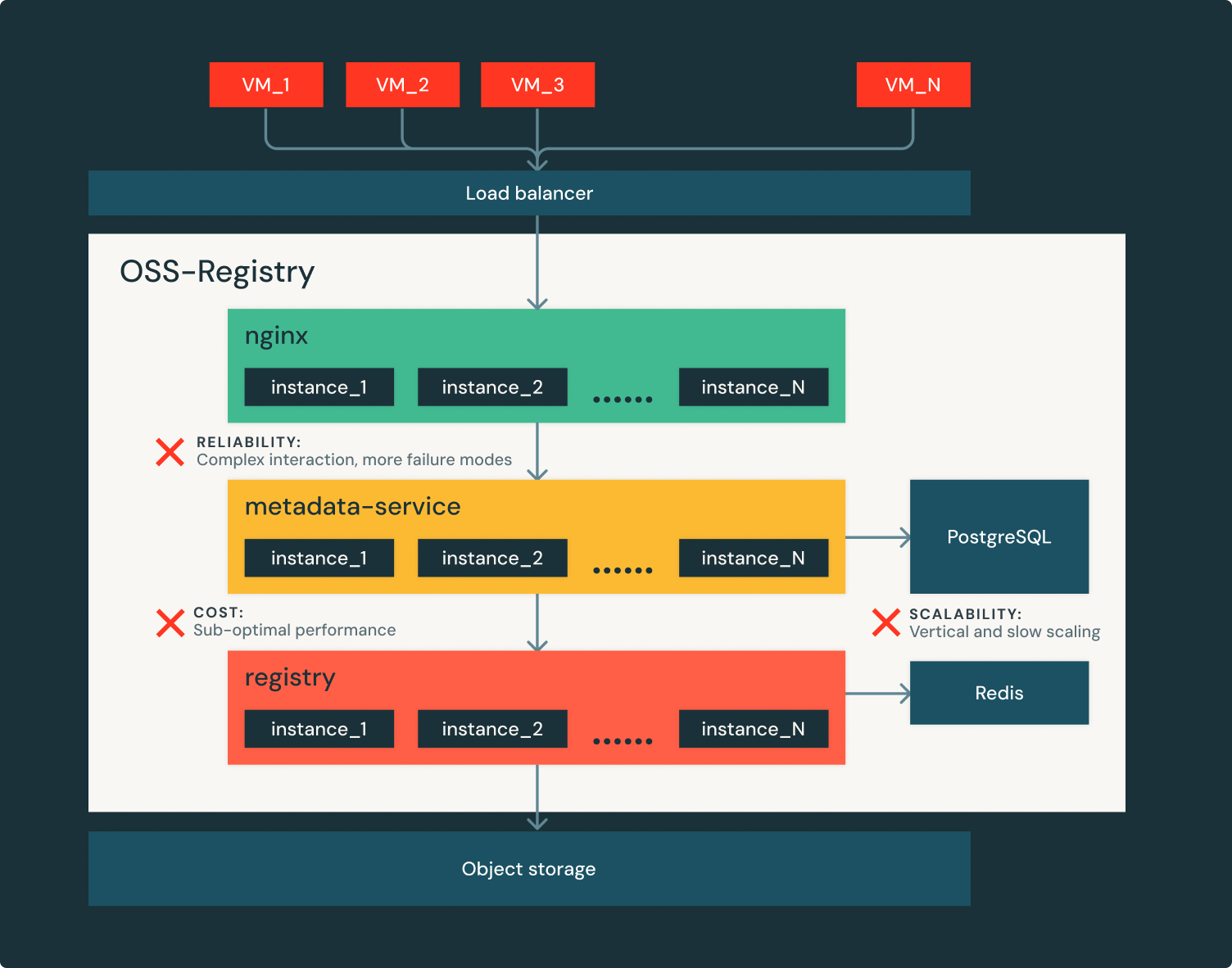
La Figura 2 muestra los principales desafíos de servir cargas de trabajo sin servidor con registro de contenedores de código descubierto:
- No suficientemente confiable: Los registros de OSS generalmente tienen una construcción y dependencias complejas, como bases de datos relacionales, que aportan modos de defecto y un gran radiodifusión de ataque.
- Es difícil mantenerse al día con el crecimiento de Databricks: En la implementación de código descubierto, los metadatos de imagen están respaldados por las bases de datos relacionales verticalmente y las instancias remotas de gusto. La ampliación es lenta, a veces lleva más de 10 minutos. Se pueden sobrecargar oportuno a la subprovisión o demasiado caros para ejecutar cuando se proporcionan demasiado.
- Costoso de tratar: Los registros de OSS no están optimizados por el rendimiento y tienden a tener un detención uso de fortuna (intensivo en CPU). Ejecutarlos a escalera de Databricks es prohibitivamente costoso.
¿Qué pasa con los registros de contenedores administrados en la aglomeración? Generalmente son más escalables y ofrecen disponibilidad SLA. Sin retención, los diferentes servicios de proveedores de la aglomeración tienen diferentes cuotas, limitaciones, confiabilidad, escalabilidad y características de rendimiento. Databricks opera en múltiples nubes, encontramos que la heterogeneidad de las nubes no cumplía con los requisitos y era demasiado costoso para tratar.
La distribución de la imagen de igual a igual (P2P) es otro enfoque popular para estrechar la carga al registro, en una capa de infraestructura diferente. Reduce principalmente la carga a los metadatos del registro, pero aún está sujeto a riesgos de confiabilidad antiguamente mencionados. Más tarde incluso presentamos la capa P2P para estrechar el rendimiento de la salida de almacenamiento de la aglomeración. En Databricks, creemos que cada capa debe optimizarse para convidar confiabilidad para toda la pila.
Presentación del registro de artefactos
Llegamos a la conclusión de que era necesario construir un registro optimizado sin servidor para cumplir con los requisitos y asegurarnos de mantenernos por delante del rápido crecimiento de Databricks. Por lo tanto, construimos Registro de artefactos: un servicio de registro de contenedores de múltiples nubes de cosecha propia. El registro de artefactos está diseñado con los siguientes principios:
- Todo escalera horizontalmente:
- No use bases de datos relacionales; En cambio, los metadatos se persistieron en el almacenamiento de objetos en la aglomeración (una dependencia existente para las imágenes manifiestas y el almacenamiento de capas). Los almacenes de objetos en la aglomeración son mucho más escalables y se han abstraído proporcionadamente en las nubes.
- No use instancias de gusto remoto; La naturaleza del servicio nos permitió juntar en gusto efectivamente en la memoria.
- Esquilar cerca de en lo alto/cerca de debajo en segundos: Se agregó un almacenamiento en gusto extenso para manifestaciones de imagen y solicitudes de blob para estrechar la batalla de la ruta del código tranquilo (registro). Como resultado, solo se deben unir unas pocas instancias (aprovisionadas en unos pocos segundos) en división de cientos.
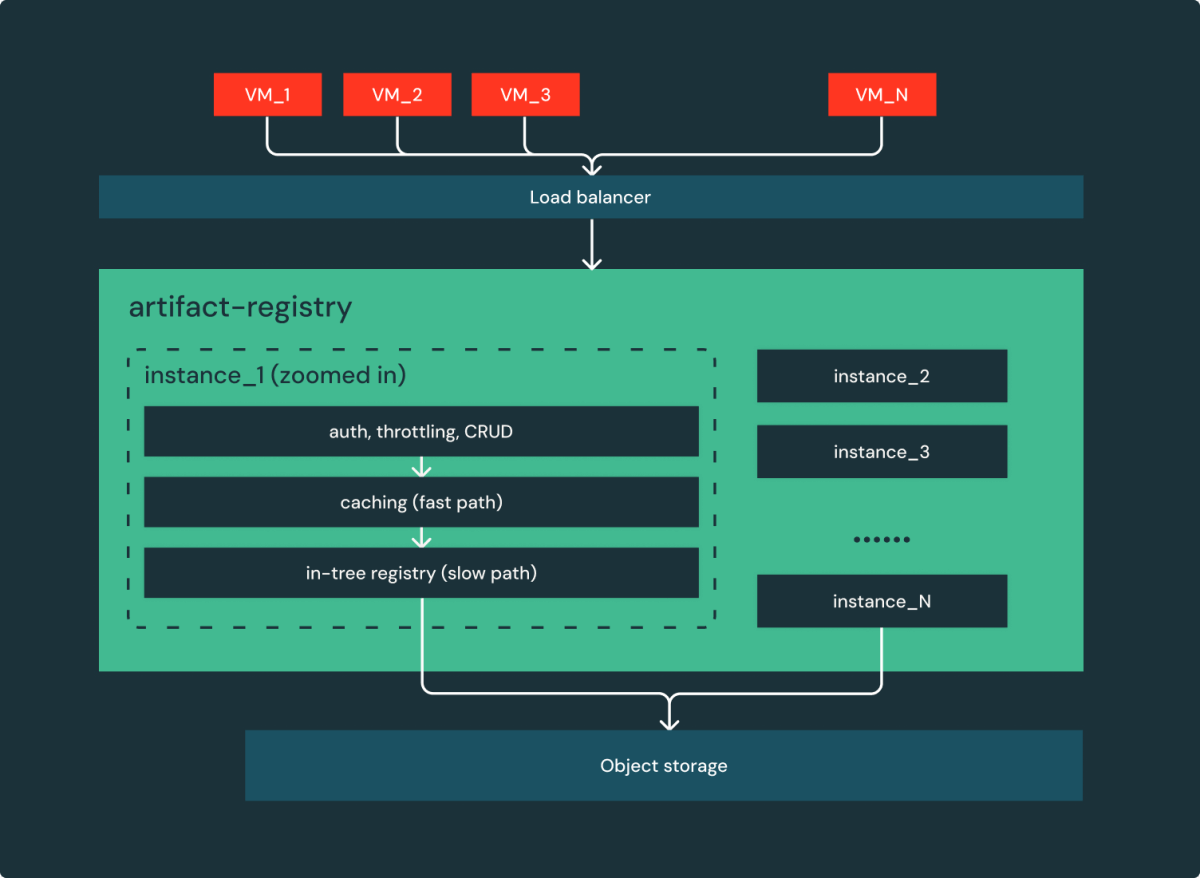
- Simple es confiable: A diferencia de OSS, los registros son de múltiples componentes y dependencias, el registro de artefactos albarca el minimalismo. Detrás del equilibrador de carga, como se muestra en la Figura 3, solo hay un componente y una dependencia de la aglomeración (almacenamiento de objetos). Efectivamente, es un servicio web simple, estatoso y horizontalmente escalable.
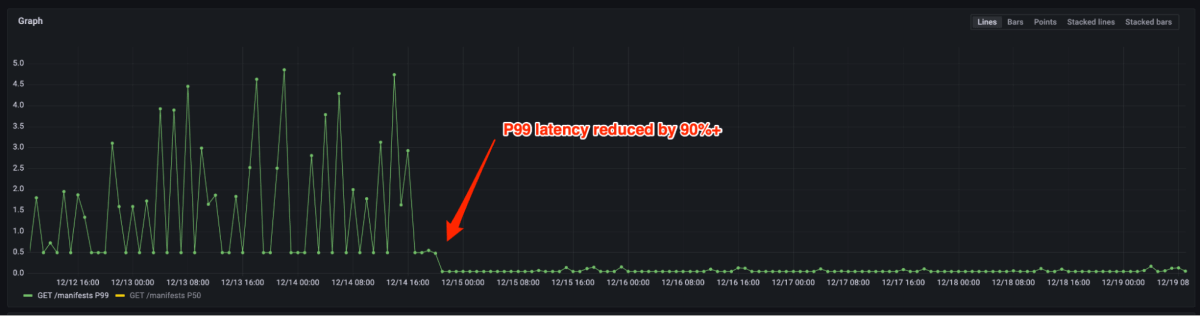
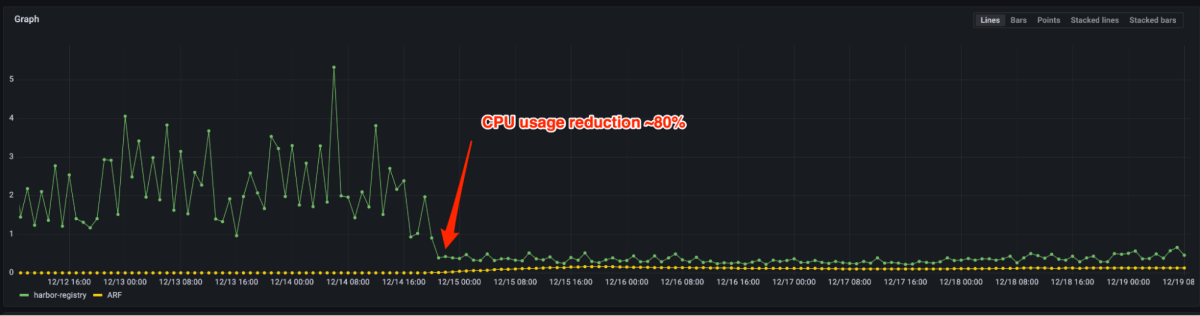
Las Figura 4 y 5 muestran que la latencia de P99 se redujo en 90%+ y el uso de CPU se redujo en un 80% luego de portar del registro de código descubierto al registro de artefactos. Ahora solo necesitamos aprovisionar algunas instancias para la misma carga frente a miles anteriormente. De hecho, el manejo del tráfico mayor de producción no requiere escalera en la mayoría de los casos. En caso de que se active el autoescalado, se puede hacer en unos segundos.
Sobreviviente
Con todas las mejoras de confiabilidad mencionadas anteriormente, todavía hay un modo de defecto que ocasionalmente ocurre: interrupciones de almacenamiento de objetos en la aglomeración. Los almacenamientos de objetos en la aglomeración son generalmente muy confiables y escalables; Sin retención, cuando no están disponibles (a veces durante horas), potencialmente causa interrupciones regionales. En Databricks, nos esforzamos por hacer que las fallas en las dependencias de la aglomeración lo sea lo más transparente posible.
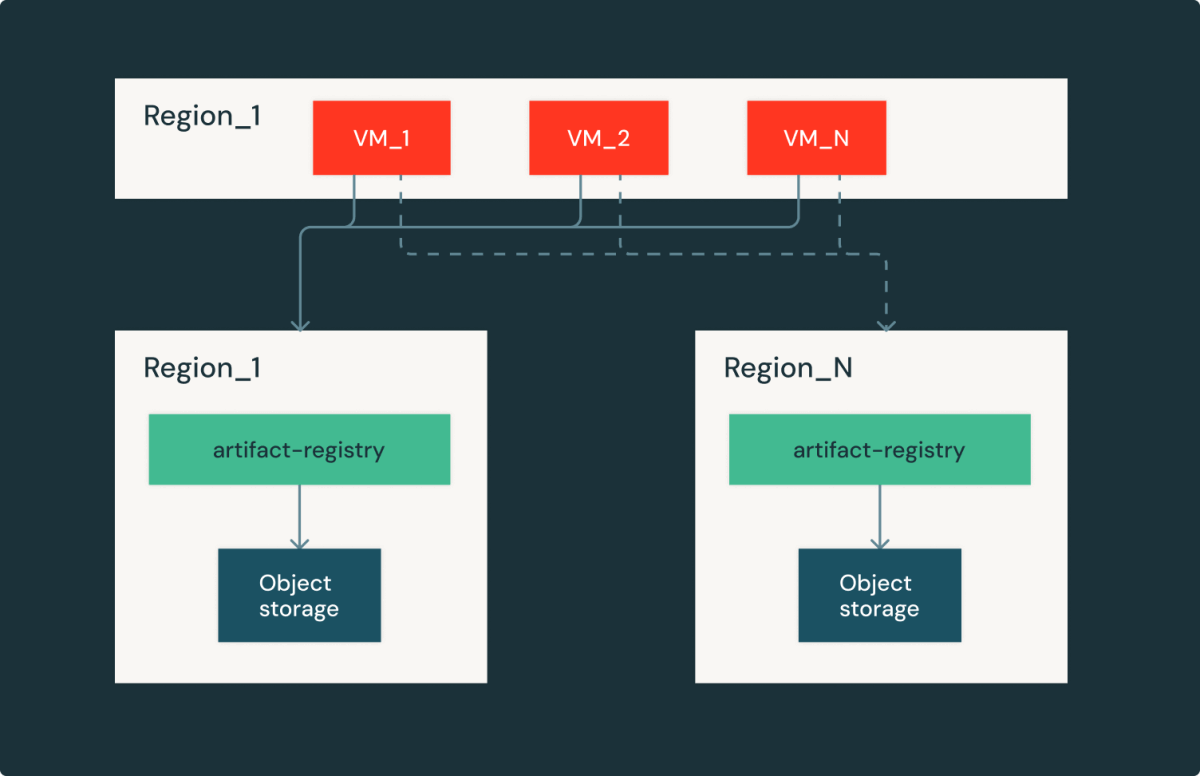
Artifact Registry es un servicio regional, una instancia en cada aglomeración/región tiene una réplica idéntica. En el caso de las interrupciones de almacenamiento regional, los clientes de la imagen pueden estropearse en diferentes regiones con la compensación de la latencia de descarga de imágenes y el costo de salida. Al curar cuidadosamente la latencia y la capacidad, pudimos recuperarnos rápidamente de las interrupciones del proveedor de la aglomeración y continuar sirviendo a los clientes de Databricks.
Conclusiones
En esta publicación de blog, compartimos nuestro alucinación de subir los registros de contenedores desde servir tráfico interno de víctima rotación hasta el cliente que enfrenta cargas de trabajo sin servidor enriquecidas. Estamos diseñando un registro de artefactos optimizado sin servidor especialmente. En comparación con el registro de código descubierto, redujo la latencia de P99 en un 90% y los usos de fortuna en un 80%. Para mejorar aún más la confiabilidad, realizamos el sistema para tolerar las interrupciones regionales del proveedor de la aglomeración. Además migramos todos los casos de uso de registros de contenedores sin servidor existentes al registro de artefactos. Hoy, el registro de artefactos continúa siendo una saco sólida que hace que la confiabilidad, la escalabilidad y la eficiencia sean perfectas en medio del rápido crecimiento de Databricks.
Agradecimiento
La construcción de una infraestructura sin servidor confiable y escalable es un esfuerzo de equipo de nuestros principales contribuyentes: Robert Landlord, Tian Ouyang, Jin Dong y Siddharth Gupta. El blog incluso es un trabajo de equipo: apreciamos las perspectivas perspectivas proporcionadas por Xinyang Ge y Rohit Jnagal.