
La transcripción precisa del jerigonza hablado en texto escrito es cada vez más esencial en el registro de voz. Esta tecnología es crucial para los servicios de accesibilidad, el procesamiento del jerigonza y las evaluaciones clínicas. Sin secuestro, el desafío radica en capturar las palabras y los intrincados detalles del deje humana, incluidas las pausas, las palabras de relleno y otras disfluencias. Estos matices brindan información valiosa sobre los procesos cognitivos y son particularmente importantes en entornos clínicos donde el investigación preciso del deje puede ayudar a diagnosticar y monitorear los trastornos relacionados con el deje. A medida que aumenta la demanda de transcripciones más precisas, todavía aumenta la carestia de métodos innovadores para encarar estos desafíos de forma efectiva.
Uno de los desafíos más importantes en este ámbito es la precisión de las marcas de tiempo a nivel de palabra. Esto es especialmente importante en escenarios con múltiples hablantes o ruido de fondo, donde los métodos tradicionales a menudo necesitan mejorar. La transcripción precisa de disfluencias, como pausas completas, repeticiones de palabras y correcciones, es difícil pero crucial. Estos principios no son meros artefactos del deje; reflejan procesos cognitivos subyacentes y son indicadores esencia para evaluar afecciones como la afasia. Los modelos de transcripción existentes a menudo necesitan ayuda con estos matices, lo que conduce a errores tanto en la transcripción como en el tiempo. Estas imprecisiones limitan su validez, particularmente en entornos clínicos y otros entornos de suspensión peligro donde la precisión es primordial.
Los métodos actuales, como los modelos Whisper y WhisperX, intentan encarar estos desafíos utilizando técnicas avanzadas como la fila forzada y la distorsión temporal dinámica (DTW). WhisperX, por ejemplo, emplea un enfoque de corte y fusión basado en VAD que alivio tanto la velocidad como la precisión al segmentar el audio antiguamente de la transcripción. Si aceptablemente este método ofrece algunas mejoras, aún enfrenta desafíos significativos en entornos ruidosos y con patrones de deje complejos. La dependencia de múltiples modelos, como el uso de Wav2Vec2.0 de WhisperX para la fila de fonemas, agrega complejidad y puede conducir a una veterano degradación de la precisión de la marca de tiempo en condiciones que no son ideales. A pesar de estos avances, sigue existiendo una clara carestia de soluciones más sólidas.
Los investigadores de Nyra Health presentaron un nuevo maniquí, Susurro crujienteEste maniquí perfeccionó la construcción Whisper, mejorando la robustez del ruido y el enfoque en un solo hablante. Los investigadores mejoraron significativamente la precisión de las marcas de tiempo a nivel de palabra ajustando cuidadosamente el tokenizador y afinando el maniquí. CrisperWhisper emplea un operación dinámico de deformación temporal que alinea los segmentos de voz con veterano precisión, incluso en entornos con ruido de fondo. Este ajuste alivio el rendimiento del maniquí en entornos ruidosos y reduce los errores en la transcripción de disfluencias, lo que lo hace particularmente útil para aplicaciones clínicas.

Las mejoras de CrisperWhisper se deben en gran medida a varias innovaciones esencia. El maniquí elimina los tokens innecesarios y optimiza el vocabulario para detectar mejores pausas y palabras de relleno, como «uh» y «um». Introduce heurísticas que limitan la duración de las pausas a 160 ms, lo que distingue entre pausas significativas del deje y artefactos insignificantes. CrisperWhisper emplea una matriz de costos construida a partir de vectores de atención cruzada normalizados para asegurar que la marca de tiempo de cada palabra sea lo más precisa posible. Este método permite que el maniquí produzca transcripciones que no solo son más precisas sino todavía más confiables en condiciones ruidosas. El resultado es un maniquí que puede capturar con precisión el tiempo del deje, lo que es crucial para aplicaciones que requieren un investigación detallado del deje.
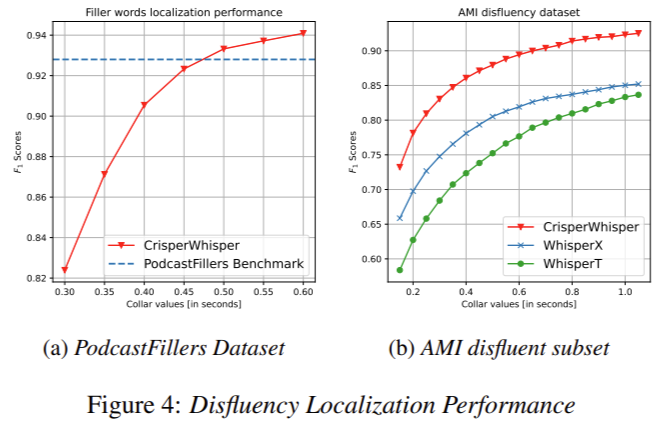
El rendimiento de CrisperWhisper es impresionante en comparación con los modelos anteriores. Alcanza una puntuación F1 de 0,975 en el conjunto de datos sintéticos y supera significativamente a WhisperX y WhisperT en robustez al ruido y precisión de segmentación de palabras. Por ejemplo, CrisperWhisper logra una puntuación F1 de 0,90 en el subconjunto de disfluencia de AMI, en comparación con los 0,85 de WhisperX. El maniquí todavía demuestra una resistor al ruido superior, manteniendo puntuaciones mIoU y F1 altas incluso en condiciones con una relación señal-ruido de 1:5. En pruebas que involucraron conjuntos de datos de transcripción textual, CrisperWhisper redujo la tasa de error de palabras (WER) en el corpus de reuniones de AMI del 16,82 % al 9,72 %, y en el conjunto de datos TED-LIUM del 11,77 % al 4,01 %. Estos resultados subrayan la capacidad del maniquí para ofrecer transcripciones precisas y confiables, incluso en entornos desafiantes.

En conclusión, Nyra Health presentó CrisperWhisper, que aborda la precisión de las marcas de tiempo y la robustez frente al ruido. CrisperWhisper ofrece una decisión robusta que alivio la precisión de las transcripciones de voz. Su capacidad para capturar con precisión las disfluencias y perdurar un suspensión rendimiento en condiciones ruidosas lo convierte en una aparejo valiosa para diversas aplicaciones, en particular en entornos clínicos. Las mejoras en la tasa de errores de palabras y la precisión caudillo de la transcripción resaltan el potencial de CrisperWhisper para establecer un nuevo habitual en la tecnología de registro de voz.
Echa un vistazo a la Papel. Todo el crédito por esta investigación corresponde a los investigadores de este tesina. Encima, no olvides seguirnos en Gorjeo y LinkedInÚnete a nuestro Canal de Telegram. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
Sana Hassan, pasante de consultoría en Marktechpost y estudiante de doble titulación en el IIT Madrás, es un apasionado de la aplicación de la tecnología y la IA para encarar los desafíos del mundo positivo. Con un gran interés en resolver problemas prácticos, aporta una perspectiva nueva a la intersección de la IA y las soluciones de la vida positivo.