
¿Qué pasaría si pudieras construir una IA sencillo similar a ChatGPT por $100? ¡El nuevo nanochat de Andrej Karpathy te dice exactamente eso! Decidido el 13 de octubre de 2025, el tesina nanochat de Karpathy es un LLM de código extenso codificado en aproximadamente 8000 líneas de PyTorch. Le brinda una hoja de ruta sencilla sobre cómo entrenar un maniquí de idioma desde cero y crear su propia IA privada en un par de horas. En este artículo, hablaremos sobre el nanochat recientemente arrojado y cómo configurarlo correctamente para la capacitación paso a paso.
¿Qué es el nanochat?
El repositorio de nanochat proporciona una canalización completa para entrenar un clon pequeño de ChatGPT. Se encarga de todo, desde la tokenización hasta la interfaz de sucesor web final. Este sistema es el sucesor del preliminar nanoGPT. Introduce características secreto como el ajuste fino supervisado (SFT), el formación por refuerzo (RL) y la inferencia mejorada.
Características secreto
El tesina tiene una serie de componentes importantes. Incorpora un nuevo tokenizador construido en Rust para un stop rendimiento. El proceso de formación emplea datos de calidad como FineWeb-EDU para la formación previa. Asimismo emplea datos especializados como SmolTalk y GSM8K para realizar ajustes posteriores al entrenamiento. Por seguridad, el maniquí puede ejecutar código en el interior de un entorno definido de Python.
El tesina funciona admisiblemente en el interior de su presupuesto. El maniquí principal “speedrun” cuesta unos 100 dólares y entrena durante cuatro horas. Asimismo puede desarrollar un maniquí más robusto por aproximadamente $1000 con aproximadamente 42 horas de capacitación.
Acto
El rendimiento aumenta con el tiempo de entrenamiento.
- 4 horas: La ejecución rápida le ofrece un maniquí conversacional simple. Puede componer poemas sencillos o describir conceptos como la dispersión de Rayleigh.
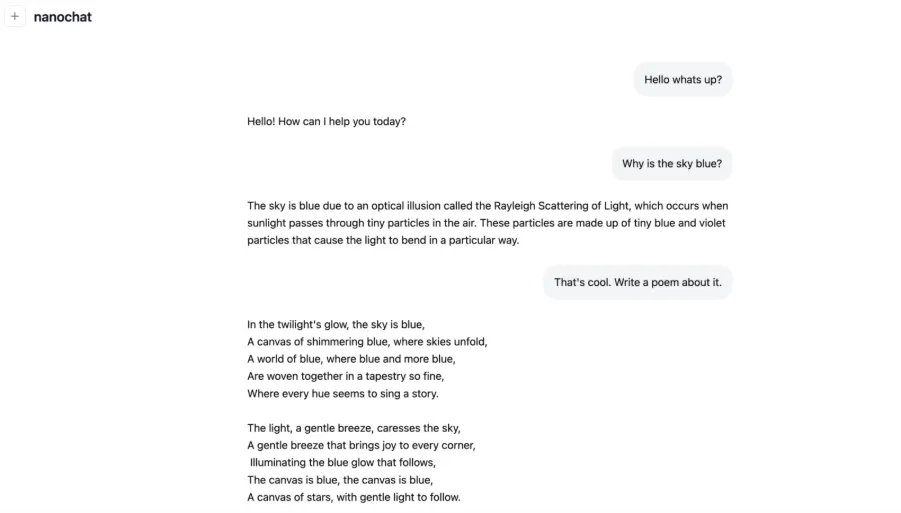
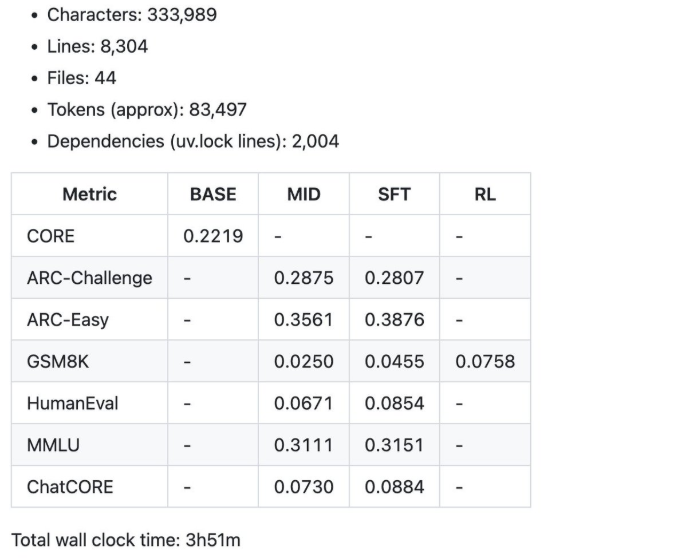
Algunas de las métricas resumidas fueron producidas por el speedrun de $100 durante 4 horas.
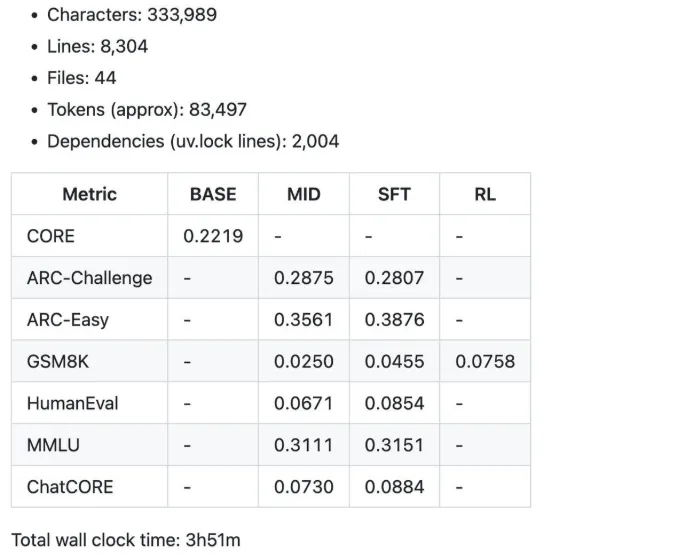
- 12 horas: El maniquí comienza a exceder al GPT-2 en el benchmark CORE.
- 24 horas: Obtiene puntuaciones decentes, como 40% en MMLU y 70% en ARC-Easy.
El objetivo educativo principal del tesina nanochat es proporcionar una colchoneta de narración posible y pirateable. Esto lo convierte en un gran apelación para estudiantes, investigadores y aficionados a la IA.
Requisitos previos y configuración
Ayer de comenzar, debe preparar su hardware y software. Es posible de hacer con las herramientas correctas.
Requisitos de hardware
El tesina se maneja mejor con un nodo GPU 8xH100. Estos están disponibles en proveedores como Lambda GPU Cloud por aproximadamente de $24 la hora. Asimismo puedes utilizar una única GPU con acumulación de gradiente. Este es un método más sosegado, pero ocho veces más sosegado.
Software
Necesitará un entorno Python en serie adjunto con PyTorch. El tesina se base en la ultravioleta Administrador de paquetes para administrar dependencias. Asimismo necesitarás tener Git instalado para poder clonar el repositorio. Como opción opcional, puedes incluir Pesos y Sesgos para registrar tus carreras de entrenamiento.
Pasos iniciales
Lo primero es clonar el repositorio oficial:
git clone (email protected):karpathy/nanochat.git En segundo lado, vaya al directorio del tesina, es asegurar, nanochat, e instale las dependencias.
cd nanochat Por posterior, cree y adjunte su instancia de GPU en la cirro para comenzar a entrenar.
Dirección para entrenar su propio clon de ChatGPT
Lo que sigue es una recorrido paso a paso para entrenar su primer maniquí. Prestar mucha atención a estos pasos dará como resultado un LLM sencillo. El tutorial oficial en el repositorio contiene más información.
Paso 1: preparación del entorno
Primero, inicie su nodo 8xH100. Una vez instalado, instale el administrador de paquetes uv usando el script proporcionado. Es inteligente tener cosas de larga duración en el interior de una sesión de pantalla. Esto hace que el entrenamiento continúe incluso cuando te desconectas.
# install uv (if not already installed)
command -v uv &> /dev/null || curl -LsSf https://astral.sh/uv/install.sh | sh
# create a .venv locorregional imaginario environment (if it doesn't exist)
( -d ".venv" ) || uv venv
# install the repo dependencies
uv sync
# activate venv so that `python` uses the project's venv instead of system python
source .venv/bin/activate Paso 2: Configuración de datos y tokenizador
Primero, necesitamos instalar Rust/Cargo para poder reunir nuestro tokenizador Rust personalizado.
# Install Rust / Cargo
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
source "$HOME/.cargo/env"
# Build the rustbpe Tokenizer
uv run maturin develop --release --manifest-path rustbpe/Cargo.toml Los datos de preentrenamiento son solo el texto de muchas páginas web y, para esta parte, usaremos el FineWeb-EDU conjunto de datos. Pero Karpathy recomienda utilizar la ulterior interpretación.
https://huggingface.co/datasets/karpathy/fineweb-edu-100b-shuffle
python -m nanochat.dataset -n 240 Una vez descargado, entrenas el tokenizador Rust en un gran corpus de texto. Este paso está hecho para que sea rápido según el asunto. Debe comprimirse a aproximadamente una relación de compresión de 4,8 a 1.
python -m scripts.tok_train --max_chars=2000000000
python -m scripts.tok_eval Paso 3: entrenamiento previo
Ahora debe descargar el paquete de datos de evaluación. Aquí es donde residen los conjuntos de datos de prueba para el rendimiento del maniquí.
curl -L -o eval_bundle.zip https://karpathy-public.s3.us-west-2.amazonaws.com/eval_bundle.zip
unzip -q eval_bundle.zip
rm eval_bundle.zip
mv eval_bundle "$HOME/.cache/nanochat" Adicionalmente, configurar varita mágica por ver bonitas tramas durante el entrenamiento. ultravioleta ya instalado varita mágica para nosotros en lo alto, pero aún debe configurar una cuenta e iniciar sesión con:
wandb login Ahora puede iniciar el script principal de preentrenamiento. Ejecútelo con el comando torchrun para utilizar las ocho GPU. El proceso entrena el maniquí en patrones de idioma simples del corpus FineWeb-EDU. Esta etapa requiere aproximadamente de dos o tres horas de velocidad. Esta es una parte trascendental del proceso de entrenamiento de un maniquí de idioma.
torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- --depth=20 Estamos iniciando el entrenamiento en 8 GPU usando el script scripts/base_train.py. El maniquí es un transformador de 20 capas. Cada GPU maneja 32 secuencias de 2048 tokens por paso alrededor de delante y alrededor de a espaldas, lo que da un total de 32 × 2048 = 524,288 (≈0.5M) tokens procesados por paso de optimización.
Si se configura Weights & Biases (wandb), puede adicionar el indicador –run=speedrun para asignar un nombre de ejecución y habilitar el registro.
Cuando comience el entrenamiento, verá un resultado similar al ulterior (simplificado aquí para longevo claridad):
Paso 4: entrenamiento medio y SFT
Una vez preentrenado, se procede al entrenamiento medio. El entrenamiento medio aplica el SmolTalk conjunto de datos para proporcionar al maniquí más poder conversacional. Posteriormente de eso, realizará un ajuste fino supervisado (SFT) en datos como GSM8K. Esto es lo que ayuda al maniquí a asimilar a ejecutar instrucciones y a resolver problemas.
Podemos comenzar el entrenamiento a parte de camino de la ulterior modo: esta carrera solo dura unos 8 minutos, mucho más corta que el entrenamiento previo de ~3 horas.
torchrun --standalone --nproc_per_node=8 -m scripts.mid_train Posteriormente de la parte del entrenamiento viene el Sintonia FINA proscenio. Esta período implica otra ronda de ajuste de los datos conversacionales, pero con un enfoque en decidir solo los ejemplos mejor seleccionados y de longevo calidad. Asimismo es la etapa donde se realizan ajustes orientados a la seguridad, como entrenar el maniquí sobre comportamientos de rechazo apropiados para consultas delicadas o restringidas. De nuevo, esto sólo dura unos 7 minutos.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_sft Paso 5: RL opcional
El LLM de código extenso de nanochat además cuenta con soporte de formación por refuerzo preliminar. Puede ejecutar una técnica conocida como GRPO en el conjunto de datos GSM8K. Este es un proceso opcional y puede tardar otra hora. Compruebe que Karpathy dijo que el soporte de RL aún está en su infancia.
torchrun --standalone --nproc_per_node=8 -m scripts.chat_rl Paso 6: Inferencia y UI
Una vez finalizado el entrenamiento, ahora puede ejecutar el script de inferencia. Esto le permite conversar con su maniquí mediante una interfaz de sucesor web o una interfaz de ringlera de comandos. Intente ejecutarlo con algunos ejemplos como «¿Por qué el Gloria es cerúleo?» para observar tu creación.
python -m scripts.chat_cli (for Command line window) O
python -m scripts.chat_web. (for Web UI) El script chat_web servirá al motor mediante FastAPI. Asegúrese de conseguir a él correctamente, por ejemplo, en Lambda, use la IP pública del nodo en el que se encuentra, seguida del puerto, por ejemplo http://209.20.xxx.xxx:8000/, etc.
Paso 7: revisar los resultados
Ahora, probándolo con la interfaz web en el enlace en el que está alojado el nanochat.
Por posterior, mira el mensaje.md en el repositorio. Tiene algunas métricas importantes para su maniquí, como su puntuación CORE y su precisión GSM8K. El speedrun principal cuesta aproximadamente $ 92,40 y supone un poco menos de cuatro horas de trabajo.
Nota: He tomado el código y los pasos del nano chat GitHub de Andrej Karapathy. Puedes encontrar la documentación completa. aquí. Lo que mostré en lo alto es una interpretación más simple y corta.
Personalización y escalado
El speedrun es un excelente punto de partida. A partir de ese punto, puedes personalizar aún más el maniquí. Esta es una de las ventajas más importantes de la interpretación de nanochat de Karpathy.
Opciones de sintonización
Puede modificar la profundidad del maniquí para mejorar el rendimiento. Con el --depth=26 bandera, digamos, entras en un rango más poderoso de $300. Asimismo puede intentar utilizar otros conjuntos de datos o modificar los hiperparámetros de entrenamiento.
Ampliación
El repositorio detalla un nivel de $1,000. Esto implica un entrenamiento prolongado de aproximadamente 41,6 horas. Produce un maniquí con longevo coherencia y puntuaciones de narración más altas. Si tiene limitaciones de VRAM, intente resumir el --device_batch_size configuración.
Desafíos de personalización
Otros pueden ajustar el maniquí en función de los datos personales. Karpathy desaconseja esto, ya que puede terminar generando “bajadura”. Una mejor modo de utilizar los datos personales es engendramiento aumentada de recuperación (RAG) a través de herramientas como NotebookLM.
Conclusión
El tesina nanochat permite tanto a investigadores como a principiantes. Ofrece una forma sencilla y económica de formar un LLM sólido de código extenso. Con un presupuesto definido y un fin de semana extenso, puede producirse de la configuración a la implementación. Utilice este tutorial para entrenar su propio ChatGPT, consulte el repositorio de nanochat y participe en el foro de la comunidad para ayudar. Tu aventura de formar un maniquí de idioma comienza aquí.
Preguntas frecuentes
R. Nanochat es una iniciativa PyTorch de código extenso de Andrej Karpathy. Proporciona un canal de extremo a extremo para capacitar un LLM estilo ChatGPT desde cero de forma económica.
R. Cuesta aproximadamente de $100 entrenar un maniquí principal y toma cuatro horas. Se pueden entrenar modelos más potentes con presupuestos de $300 a $1000 con duraciones de entrenamiento extendidas.
R. La configuración sugerida es un nodo GPU 8xH100 y puede alquilarlo a proveedores de cirro. Es posible utilizar una sola GPU, pero será mucho más lenta.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de idioma grandes que con humanos reales. Apasionado por GenAI, PNL y hacer que las máquinas sean más inteligentes (para que no lo reemplacen todavía). Cuando no optimiza modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.