
Uno de los desafíos más críticos de los LLM es cómo alinear estos modelos con los títulos y preferencias humanos, especialmente en los textos generados. La mayoría de los resultados de texto generados por los modelos son inexactos, sesgados o potencialmente dañinos (por ejemplo, alucinaciones). Esta desalineación limita el uso potencial de los LLM en aplicaciones del mundo auténtico en dominios como educación, salubridad y atención al cliente. Esto se ve agravado aún más por el hecho de que el sesgo se acumula en los LLM; Los procesos de capacitación iterativos seguramente empeorarán los problemas de fila y, por lo tanto, no está claro si se confiará en el resultado producido. De hecho, este es un desafío muy serio para una ampliación más amplia y efectiva de las modalidades de LLM aplicadas a aplicaciones del mundo auténtico.
Las soluciones actuales para la fila implican métodos como RLHF y optimización de preferencia directa (DPO). RLHF entrena un maniquí de retribución que retribución al LLM a través del educación reforzado basado en comentarios humanos, mientras que DPO optimiza el LLM directamente con pares de preferencias anotados y no requiere un maniquí separado para las recompensas. Los dos enfoques dependen en gran medida de cantidades masivas de datos etiquetados por humanos, que son difíciles de resquilar. Los modelos lingüísticos autogratificantes intentan estrechar esta dependencia generando automáticamente datos de preferencias sin interferencia humana. En los SRLM, un único maniquí suele llevar a cabo como maniquí de política (que genera respuestas) y como maniquí de retribución que clasifica estas respuestas. Si aceptablemente esto ha tenido cierto éxito, su principal inconveniente es que dicho proceso resulta inherentemente en un sesgo en la iteración de recompensas. Cuanto más se haya entrenado de esta forma un maniquí en sus datos de preferencias creados por él mismo, más sesgado estará el sistema de retribución, y esto reducirá la confiabilidad de los datos de preferencias y degradará el rendimiento universal en la fila.
A la luz de estas deficiencias, investigadores de la Universidad de Carolina del Boreal, la Universidad Tecnológica de Nanyang, la Universidad Doméstico de Singapur y Microsoft introdujeron CREAM, que significa Modelos de Jerigonza Autogratificantes Regularizados de Consistencia. Este enfoque alivia los problemas de amplificación de sesgos en los modelos de autorrecompensa al incorporar un término de regularización sobre la consistencia de las recompensas entre generaciones durante el entrenamiento. La intuición es incorporar regularizadores de coherencia que evalúen las recompensas producidas por el maniquí en iteraciones consecutivas y utilicen esta coherencia como lazarillo para el proceso de entrenamiento. Al contrastar la clasificación de las respuestas de la iteración coetáneo con las de la iteración antedicho, CREAM encuentra y se centra en datos de preferencia confiables, lo que dificulta la tendencia de sobreaprendizaje del maniquí a partir de etiquetas ruidosas o poco confiables. Este novedoso mecanismo de regularización reduce el sesgo y permite aún más que el maniquí aprenda de forma más capaz y efectiva a partir de sus datos de preferencias autogenerados. Esta es una gran prosperidad en comparación con los métodos actuales de retribución personal.
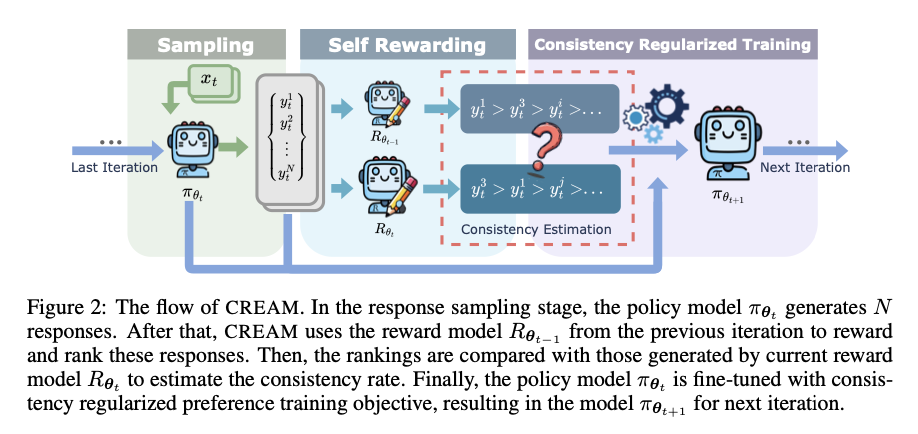
CREAM opera interiormente de un situación de ajuste de preferencias iterativo generalizado aplicable tanto a los métodos de autorecompensa como a los de RLHF. La regularización de la coherencia funciona comparando la clasificación de las respuestas producidas por el maniquí en iteraciones consecutivas. Más precisamente, la coherencia entre las clasificaciones procedentes de la iteración coetáneo y antedicho se mide mediante el coeficiente Tau de Kendall. Luego, esta puntuación de coherencia se incorpora a la función de pérdida como un término de regularización, lo que anima al maniquí a necesitar más de datos de preferencia que tengan una adhesión coherencia entre iteraciones. Adicionalmente, CREAM afina LLM mucho más pequeños, como LLaMA-7B, utilizando conjuntos de datos que están ampliamente disponibles, como ARC-Easy/Challenge, OpenBookQA, SIQA y GSM8K. De forma iterativa, el método fortalece esto mediante el uso de un mecanismo de ponderación para los datos de preferencia basado en su consistencia para conquistar una fila superior sin carestia de conjuntos de datos a gran escalera etiquetados por humanos.

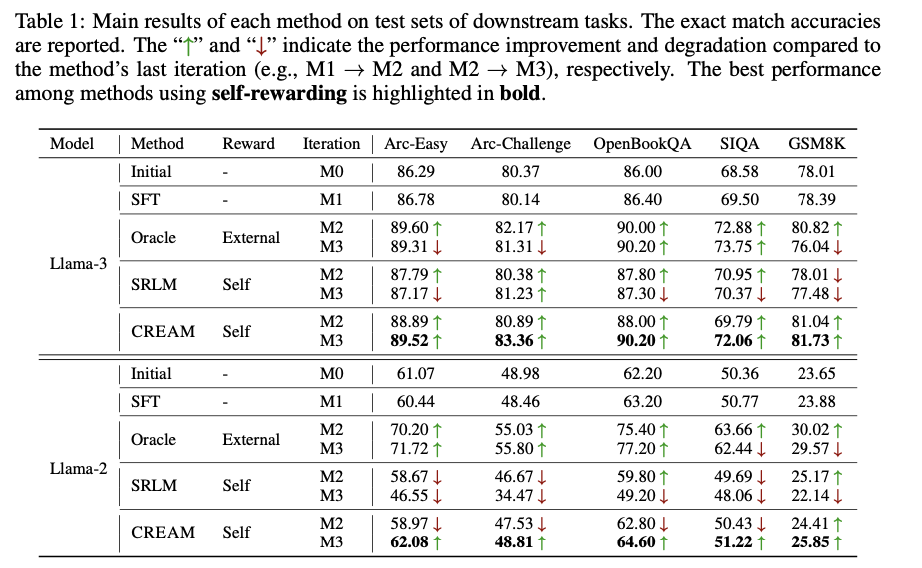
CREAM supera la vírgula de almohadilla en muchas tareas posteriores en términos de fila y matanza de sesgos de modelos autorrecompensantes. Las mejoras notables en la precisión con el método incluyen un aumento del 86,78 % al 89,52 % en ARC-Easy y del 69,50 % al 72,06 % en SIQA. Estas mejoras consistentes con respecto a las iteraciones muestran el poder del mecanismo de regularización de consistencia en funcionamiento. Si aceptablemente los métodos típico de autorecompensa tienden a tener una último consistencia universal de retribución y fila, CREAM supera a los modelos existentes, incluso en comparación con sistemas que utilizan modelos de retribución externos de adhesión calidad. Esto igualmente mantuvo la prosperidad del rendimiento sin utilizar ninguna ayuda externa, lo que muestra la solidez del maniquí a la hora de gestar datos de preferencias confiables. Adicionalmente, este maniquí sigue mejorando en términos de precisión y coherencia en las métricas de retribución, lo que refleja verdaderamente la importancia de la regularización para mitigar el sesgo de retribución y mejorar la eficiencia en la autorecompensa. Estos resultados establecen aún más a CREAM como una opción sólida al problema de fila al proporcionar un método escalable y eficaz para optimizar modelos de jerga grandes.
En conclusión, CREAM ofrece una opción novedosa contra el desafío de compensar el sesgo en modelos de jerga autogratificantes mediante la inmersión de un mecanismo de regularización de coherencia. Al prestar más atención a datos de preferencia confiables y consistentes, CREAM logra una inmensa prosperidad en la fila del rendimiento, especialmente para modelos harto pequeños como LLaMA-7B. Si aceptablemente esto excluye la dependencia a holgado plazo de datos anotados por humanos, este método representa una prosperidad importante alrededor de la escalabilidad y la eficiencia en el educación de preferencias. Por lo tanto, esto lo coloca como una contribución muy valiosa al incremento continuo de los LLM alrededor de aplicaciones del mundo auténtico. Los resultados empíricos validan firmemente que CREAM de hecho supera a los métodos existentes y puede tener un impacto potencial en la prosperidad de la fila y la confiabilidad en los LLM.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este tesina. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 50.000 ml.
(Próximo seminario web en vivo: 29 de octubre de 2024) La mejor plataforma para ofrecer modelos optimizados: motor de inferencia Predibase (promocionado)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el educación maquinal, y aporta una sólida formación académica y experiencia maña en la resolución de desafíos interdisciplinarios de la vida auténtico.