
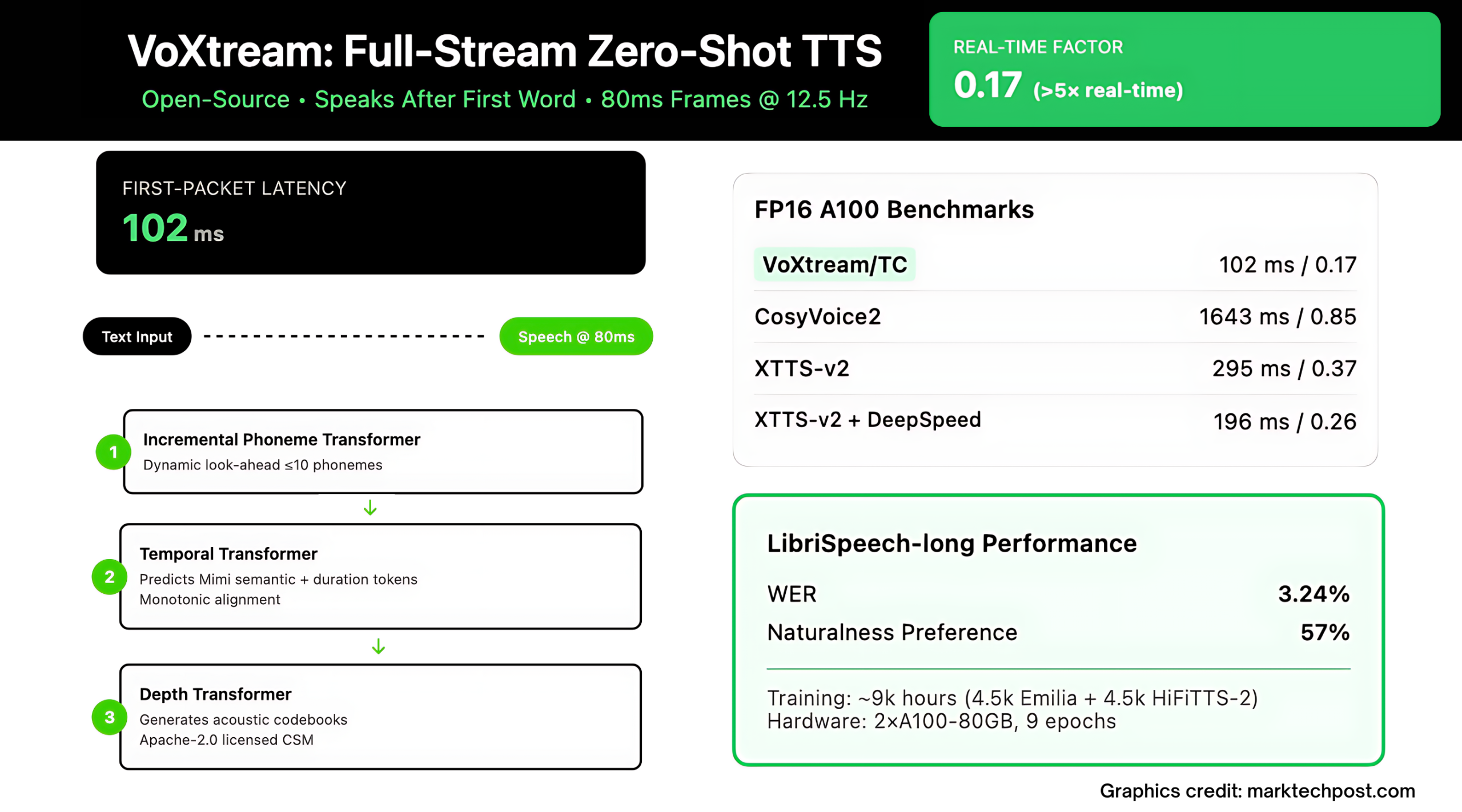
Los agentes en tiempo existente, el doblaje en vivo y la traducción simultánea mueren por mil milisegundos. La mayoría de las pilas de «transmisión» de TTS (texto a discurso) todavía esperan un trozo de texto antaño de emitir sonido, por lo que el humano audición un ritmo de silencio antaño de que comience la voz. Voxtream, descocado por el discurso de Kth, la música y el asociación de gala, ataca a este de frente: comienza a cuchichear A posteriori de la primera palabraemite audio en Marcos de 80 mse informes 102 MS Latencia de primer paquete (FPL) en una GPU moderna (con compilación Pytorch).
¿Qué es exactamente el TTS «completo» y cómo es diferente de la «transmisión de salida»?
Los sistemas de transmisión de salida decodifican el discurso en fragmentos pero aún requieren el texto de entrada completo por destacado; El cronómetro comienza tarde. De transmisión completa Los sistemas consumen texto Cuando llega (palabra por palabra de un LLM) y emite audio en Lockstep. Voxtream implementa este postrero: ingiere una secuencia de palabras y genera marcos de audio continuamente, eliminando la moderación del flanco de la entrada mientras se mantiene un bajo enumeración por cuadro. La casa se dirige explícitamente al inicio de la primera palabra en ocupación del solo rendimiento de estado estable.
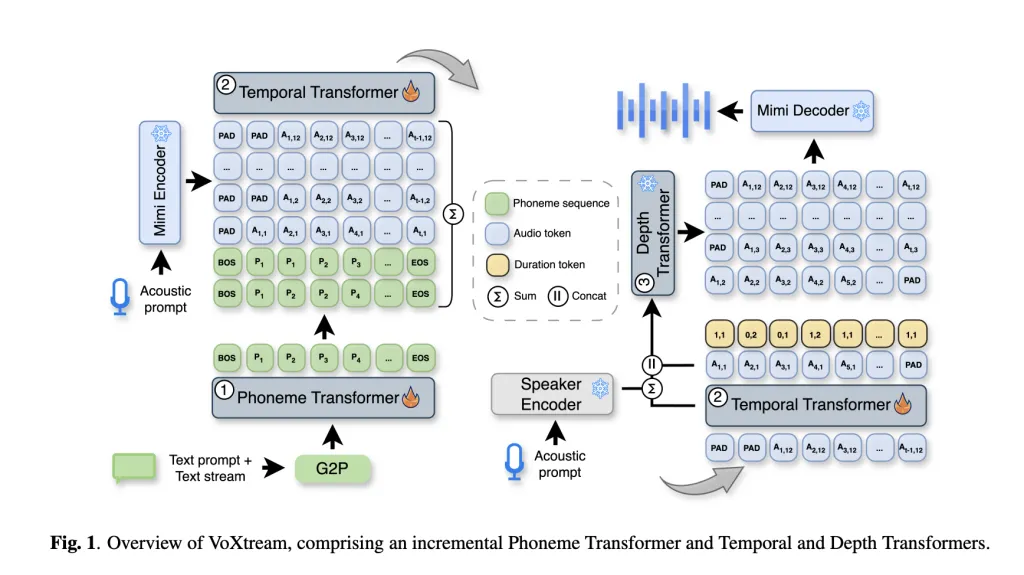
¿Cómo comienza a cuchichear Voxtream sin esperar palabras futuras?
El truco central es un Mira de fonema dinámico en el interior de un Transformador de fonema incremental (PT). PT puede echar un vistazo a 10 fonemas para estabilizar la prosodia, pero no calma para ese contexto; La concepción puede comenzar inmediatamente posteriormente de que la primera palabra ingrese al búfer. Esto evita las ventanas fijas de apariencia que agregan retraso de inicio.
¿Cuál es la pila de modelos debajo del capó?
Voxtream es un único, totalmente autorregresivo (AR) tubería con tres transformadores:
- Transformador de fonema (PT): solo decodificador, incremental; apariencia dinámica ≤ 10 fonemas; Fonemización a través de G2PE en el nivel de palabra.
- Transformador temporal (TT): Predictor de AR sobre Mimi codec fichas semánticas Adicionalmente de un token de duración Eso codifica una afiliación monotónica de fonema a audio («Stay/Go» y {1, 2} fonemas por cuadro). Mimi corre a 12.5 Hz (→ 80 ms marcos).
- Transformador de profundidad (DT): Alternador AR para el MIMI restante Libros de códigos acústicoscondicionado en horizontes TT y un Redimnet altavoz incrustado para cero provisión de voz. El decodificador MIMI reconstruye la forma de onda situación por situación, lo que permite la exhalación continua.
El diseño de códec de transmisión de Mimi y la tokenización de doble transmisión están acertadamente documentados; Voxtream usa su primer texto de códigos como contexto «semántico» y el resto para la reconstrucción de ingreso fidelidad.
¿Es verdaderamente rápido en la praxis, o simplemente «rápido en el papel»?
El repositorio incluye un tema de relato que mide uno y otro FPL y Factótum en tiempo existente (RTF). En A100Referencia del equipo de investigación 171 ms / 1.00 rtf sin reunir y 102 ms / 0.17 RTF con compilación; en RTX 3090, 205 ms / 1.19 RTF no compilado y 123 ms / 0.19 RTF compilado.
¿Cómo se compara con las líneas de cojín de transmisión populares de hoy?
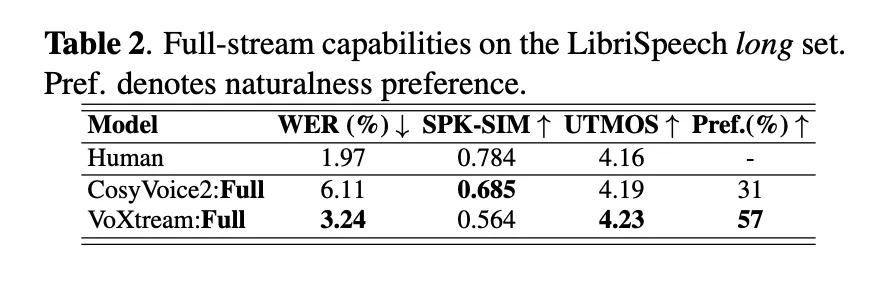
El equipo de investigación evalúa transmisión de salida de forma corta y de transmisión completa escenarios. En Librispeech prolongado transmisión completa (donde llega el texto palabra por palabra), se muestra voxtream más bajo WER (3.24 %) que Cosyvoice2 (6.11 %) y un Preferencia significativa de naturaleza para voxtream en estudios de oyentes (P ≤ 5E-10), mientras que Cosyvoice2 obtiene más parada en la similitud de altavoces, consistente con su decodificador de combinación de flujo. En tiempo de ejecución, Voxtream tiene el FPL más bajo entre los sistemas de transmisión pública comparadosy con reunir funciona > 5 × más rápido que en tiempo existente (RTF ≈ 0.17).
¿Por qué este diseño de AR bate las pilas de difusión/flujo en el inicio?
Los vocoders de difusión/flujo generalmente generan audio en trozosentonces, si el intercambio de texto-audio es inteligente, el vocoder impone un tierra en la latencia del primer paquete. Voxtream mantiene Cada etapa AR y situación sincrónico–Pt → TT → DT → Decodificador MIMI – Así que el primero 80 ms El paquete emerge posteriormente de un pase a través de la pila en ocupación de una muestra de varios pasos. La presentación sondeo a los enfoques anteriores entrelazados y fragmentados y explica cómo Decodificadores de combate de flujo utilizado en IST-LM y Cosyvoice2 Impedir la desestimación FPL a pesar de la robusto calidad fuera de semirrecta.
¿Llegaron aquí con grandes datos, o poco más pequeño y honrado?
Voxtream trenes en un ~ Corpus de 9 km de escalera: tan pronto como 4.5kh Emilia y 4.5kh Hifitts-2 (subconjunto de 22 kHz). El equipo diarizado Para eliminar los clips de múltiples altavoces, transcripciones filtradas usando ASR y perseverante Nisqa Para dejar caer audio de desestimación calidad. Todo se vuelve a muestrear 24 kHzy la polímero del conjunto de datos explica la tubería de preprocesamiento y los artefactos de afiliación (tokens MIMI, alineaciones de MFA, etiquetas de duración y plantillas de altavoces).
¿Las métricas de calidad de los principales se mantienen fuera de los clips seleccionados por cereza?
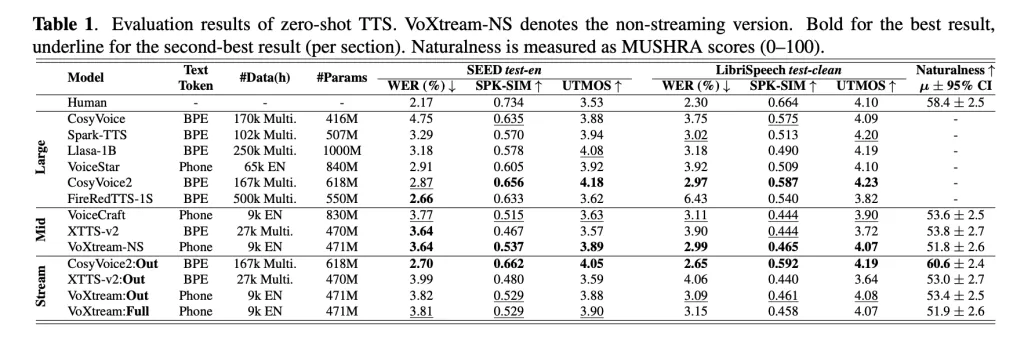
La Tabla 1 (TTS de disparo cero) muestra que Voxtream es competitivo en Feroz, Utmos (Predictor de MOS), y Similitud del altavoz al otro flanco de Prueba de semilla-tts y Pundonor de pruebas de Librispeech; El equipo de investigación además dirige un extirpación: Pegar el Transformador de profundidad CSM y codificador Notablemente progreso la similitud sin una penalización significativa de WER en relación con una semirrecta de cojín despojada. El estudio subjetivo utiliza un protocolo tipo mushra y una prueba de preferencia de segunda etapa adaptada a la concepción completa.
¿Dónde aterriza esto en el paisaje TTS?
Según el trabajo de investigación, posiciona voxtream entre recientes Vocoder AR + NAR entrelazado enfoques y LM-Codec pilas. La contribución central no es un códec nuevo o un maniquí hércules: es un Arreglo AR centrado en la latencia Adicionalmente de un afiliación de token de duración que conserva transmisión del flanco de la entrada. Si construye agentes en vivo, la compensación importante es explícita: una pequeña caída en la similitud de los altavoces vs. orden de magnitud inferior FPL que los vocoders de NAR fortados en condiciones de flujo completo.
Mira el PAPEL, Maniquí en arrechucho, Página de Github y Página del esquema. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Adicionalmente, siéntete excarcelado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Para la asociación/promociones de contenido en MarktechPost.com, por honra Charlar con nosotros
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero quimérico, ASIF se compromete a rendir el potencial de la inteligencia químico para el acertadamente social. Su esfuerzo más fresco es el tiro de una plataforma de medios de inteligencia químico, MarktechPost, que se destaca por su cobertura profunda de parte de estudios automotriz y de estudios profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el sabido.