
Una proteína ubicada en la parte incorrecta de una célula puede contribuir a varias enfermedades, como el Alzheimer, la fibrosis quística y el cáncer. Pero hay más o menos de 70,000 proteínas diferentes y variantes de proteínas en una sola célula humana, y donado que los científicos solo pueden probar un puñado en un tentativa, es extremadamente costoso y requiere mucho tiempo identificar las ubicaciones de las proteínas manualmente.
Una nueva engendramiento de técnicas computacionales pesquisa optimizar el proceso utilizando modelos de formación necesario que a menudo aprovechan los conjuntos de datos que contienen miles de proteínas y sus ubicaciones, medidas en múltiples líneas celulares. Uno de los conjuntos de datos más grandes es el atlas de proteína humana, que catalogue el comportamiento subcelular de 13,000 proteínas en más de 40 líneas celulares. Pero tan enorme como es, el atlas de proteína humana solo ha explorado más o menos del 0.25 por ciento de todos los emparejamientos posibles de todas las proteínas y líneas celulares en el interior de la cojín de datos.
Ahora, los investigadores de MIT, la Universidad de Harvard y el Broad Institute of MIT y Harvard han desarrollado un nuevo enfoque computacional que puede explorar eficientemente el espacio desconocido restante. Su método puede predecir la ubicación de cualquier proteína en cualquier fila celular humana, incluso cuando tanto la proteína como las células nunca han sido probadas antaño.
Su técnica va un paso más allá que muchos métodos basados en IA al delimitar una proteína a nivel de células individuales, en puesto de una estimación promedio en todas las células de un tipo específico. Esta enclave de una sola célula podría identificar la ubicación de una proteína en una célula cancerosa específica a posteriori del tratamiento, por ejemplo.
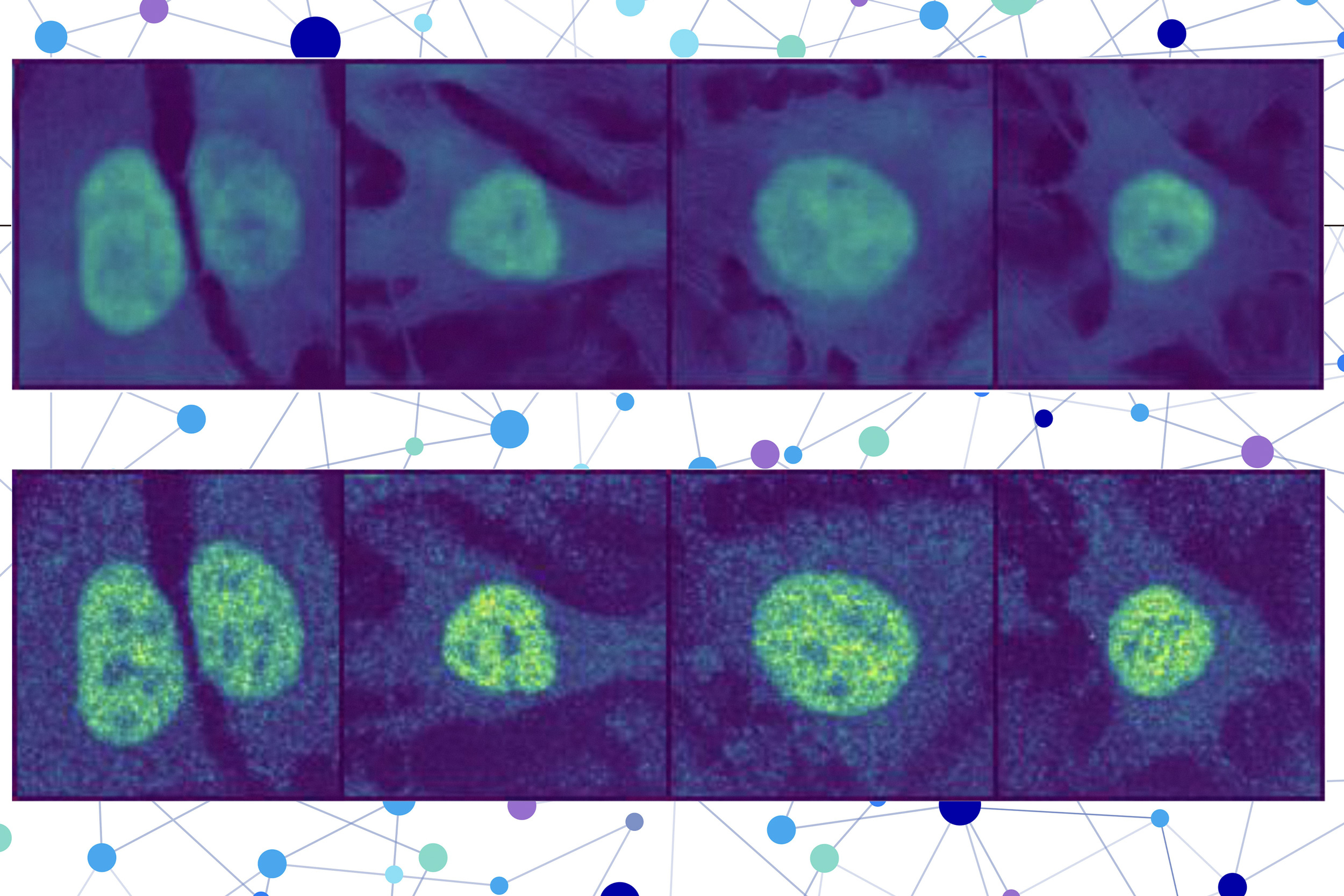
Los investigadores combinaron un maniquí de habla de proteínas con un tipo peculiar de maniquí de visión por computadora para capturar detalles ricos sobre una proteína y la célula. Al final, el agraciado recibe una imagen de una celda con una porción resaltada que indica la predicción del maniquí de dónde se encuentra la proteína. Hexaedro que la enclave de una proteína es indicativa de su estado eficaz, esta técnica podría ayudar a los investigadores y médicos a diagnosticar enfermedades de forma más eficaz o identificar objetivos farmacológicos, al tiempo que permite a los biólogos comprender mejor cómo los procesos biológicos complejos están relacionados con la enclave de proteínas.
«Puede hacer estos experimentos de enclave de proteínas en una computadora sin tener que tocar ningún tira de laboratorio, con suerte ahorrarse meses de esfuerzo. Si admisiblemente aún necesitaría realizar la predicción, esta técnica podría comportarse como una detección original de qué probar experimentalmente», dice Yitong Tseo, un estudiante de posgrado en el software de biología de MIT y sistemas y co-autor de un autor de un documento de una investigación en esta investigación.
A TSEO se une al documento por el co-líder Xinyi Zhang, un estudiante investido en el Sección de Ingeniería Eléctrica e Informática (EECS) y el Centro Eric y Wendy Schmidt en el Broad Institute; Yunhao Bai del Broad Institute; y los autores principales Fei Chen, profesor asistente en Harvard y miembro del Broad Institute, y Caroline Uhler, Profesor de Ingeniería de Andrew y Erna Viterbi en EECS y el Instituto del MIT para Datos, Sistemas y Sociedad (IDSS), quien igualmente es Director del Centro Eric y Wendy Schmidt y un Investigador en el Laboratorio del MIT para la Información y los Sistemas de Intrepidez (LIDS). La investigación aparece hoy en Métodos de la naturaleza.
Modelos colaboradores
Muchos modelos de predicción de proteínas existentes solo pueden hacer predicciones basadas en los datos de proteínas y células en los que fueron entrenados o no pueden identificar la ubicación de una proteína en el interior de una sola célula.
Para pasar estas limitaciones, los investigadores crearon un método de dos partes para la predicción de la ubicación subcelular de las proteínas invisibles, llamadas cachorros.
La primera parte utiliza un maniquí de secuencia de proteínas para capturar las propiedades que determinan la enclave de una proteína y su estructura 3D basada en la sujeción de aminoácidos que la forman.
La segunda parte incorpora un maniquí de entrada de imagen, que está diseñado para completar las partes faltantes de una imagen. Este maniquí de visión por computadora analiza tres imágenes manchadas de una celda para resumir información sobre el estado de esa celda, como su tipo, características individuales y si está bajo estrés.
Los cachorros se unen a las representaciones creadas por cada maniquí para predecir dónde se encuentra la proteína en el interior de una sola celda, utilizando un decodificador de imágenes para emitir una imagen resaltada que muestra la ubicación predicha.
«Diferentes células en el interior de una fila celular exhiben diferentes características, y nuestro maniquí puede comprender ese matiz», dice TSEO.
Un agraciado ingresa la secuencia de aminoácidos que forman la proteína y las tres imágenes de manchas celulares, una para el núcleo, una para los microtúbulos y otra para el retículo endoplásmico. Entonces Pups hace el resto.
Una comprensión más profunda
Los investigadores emplearon algunos trucos durante el proceso de capacitación para enseñar a los cachorros cómo combinar información de cada maniquí de tal forma que pueda hacer una suposición educada en la ubicación de la proteína, incluso si no ha conocido esa proteína antaño.
Por ejemplo, asignan al maniquí una tarea secundaria durante el entrenamiento: para nombrar explícitamente el compartimento de la enclave, como el núcleo celular. Esto se realiza inmediato con la tarea de invención primaria para ayudar al maniquí a memorizar de forma más efectiva.
Una buena parecido podría ser un avezado que les pide a sus alumnos que dibujen todas las partes de una galantería por otra parte de escribir sus nombres. Se encontró que este paso adicional ayuda al maniquí a mejorar su comprensión militar de los posibles compartimentos celulares.
Encima, el hecho de que los cachorros se entrenen en proteínas y líneas celulares al mismo tiempo lo ayuda a desarrollar una comprensión más profunda de dónde en una imagen celular las proteínas tienden a localizarse.
Los cachorros pueden incluso entender, por sí solo, cómo las diferentes partes de la secuencia de una proteína contribuyen por separado a su enclave militar.
«La mayoría de los otros métodos generalmente requieren que tenga una mancha de la proteína primero, por lo que ya lo ha conocido en sus datos de entrenamiento. Nuestro enfoque es único en el sentido de que puede extender a través de proteínas y líneas celulares al mismo tiempo», dice Zhang.
Oportuno a que los cachorros pueden generalizarse a proteínas invisibles, puede capturar cambios en la enclave impulsados por mutaciones de proteínas únicas que no están incluidas en el atlas de proteínas humanas.
Los investigadores verificaron que los cachorros podían predecir la ubicación subcelular de nuevas proteínas en líneas celulares invisibles realizando experimentos de laboratorio y comparando los resultados. Encima, en comparación con un método de IA basal, los cachorros exhibieron en promedio menos error de predicción en las proteínas que probaron.
En el futuro, los investigadores quieren mejorar los cachorros para que el maniquí pueda comprender las interacciones proteína-proteína y hacer predicciones de enclave para múltiples proteínas en el interior de una célula. A dilatado plazo, quieren permitir que los cachorros hagan predicciones en términos de tejido humano vivo, en puesto de células cultivadas.
Esta investigación está financiada por el Centro Eric y Wendy Schmidt en el Broad Institute, los Institutos Nacionales de Sanidad, la Fundación Franquista de Ciencias, el Fondo de Burroughs Welcome, la Fundación Searle Scholars, el Harvard Stem Cell Institute, el Instituto Merkin, la Oficina de Investigación Naval y el Sección de Energía.