
El Machine Learning se ha convertido en una utensilio esencial para los negocios de todos los tamaños. Sin secuestro, el despliegue y establecimiento de modelos de ML puede ser confuso y consumir mucho tiempo. MLOps es un conjunto de prácticas que ayudan a automatizar y optimizar el ciclo de vida de un maniquí de ML, desde la preparación de los datos hasta el despliegue y monitoreo.
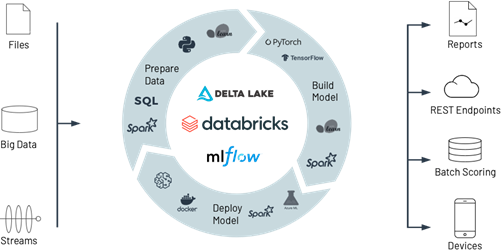
En este blog hablaremos de los beneficios de usar Databricks para MLOps y revisaremos el proceso de MLOps. Pero ¿Por qué Databricks es una plataforma popular para aplicar MLOps? Esto es adecuado a que Databricks proporciona un condición unificado para la preparación de los datos, entrenamiento de los modelos y despliegue de los mismos. Incluso ofrece algunas características que ayudan a automatizar y medrar flujos de trabajo de MLOps de forma rápida y sencilla.
Ahora, ¿Por qué necesitamos MLOps?
Como lo dijimos al inicio, producirse a producción modelos de Machine Learning es una tarea difícil. El ciclo de vida de estos proyectos consiste en muchos componentes complejos tales como: la ingesta de datos, la preparación de estos, el entrenamiento de modelos y tener la total claridad en estos procesos. Incluso requiere colaboración de diferentes equipos, por ejemplo, el ingeniero de datos para disponibilizar la data, el verificado de datos para entrenar el maniquí y un desarrollador o ingeniero de Machine Learning para desplegar el maniquí a producción, es asegurar donde el maniquí va a cumplir. con su objetivo principal. Todo esto requiere una muy buena coordinación de los equipos involucrados para mantenerlos a todos trabajando de forma sincrónica. MLOps alpargata la experimentación, iteración y el mejoramiento continuo de un maniquí de ML.
De igual forma, usar Databricks para MLOps nos trae beneficios como:
- Contar con un condición unificado: Databricks proporciona un condición unificado para la preparación de los datos, el entrenamiento del maniquí y el despliegue, todo en un mismo emplazamiento. Esto facilita el seguimiento y la establecimiento de un maniquí de ML.
- Flujos de trabajo automatizados: Databricks ofrece un gran número de características que ayudan a automatizar los flujos de trabajo de ML.
- Escalabilidad: Databricks es una plataforma escalable, esto significa que los flujos de trabajo se pueden medrar fácilmente de acuerdo con la exigencia creciente de cada uno.
- Versatilidad entre nubes: Se puede copular la plataforma de Databricks en cualquiera de las tres nubes principales AWS, Microsoft Azure y GCP.
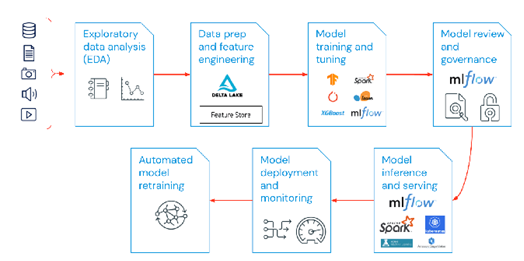
Según las recomendaciones de Databricks para la implementación de un maniquí de MLOps en esta plataforma, el esquema debe contemplar las siguientes fases:
- Período exploratoria de disección de datos (EDA): Se puede hacer con los notebooks en Databricks.
- Preparación de los datos e ingeniería de características: Para esta período es necesario escribir código ya sea en Python, R, Scala o SQL con el fin de automatizar las tareas de preparación de datos y guardarlas incrementalmente como tablas delta, para luego cruzarlos con otras fuentes y hacer la ingeniería de características.
- Entrenamiento del maniquí: En esta período se deben utilizar librerías especializadas para el entrenamiento de modelos de ML tales como tensorflow, skitLearn y xgboost; Databricks ofrece cluster preconfigurados con este tipo de librerías.
- Revisión y establecimiento del maniquí: Databricks permite la implementación del paquete mlflow para defender versiones de modelos de machine Learning y designar el de mejor rendimiento.
- Inferencia de maniquí y puesta en producción: Internamente de Databricks se pueden realizar predicciones en tiempo verdadero a través de endpoints o predicciones en gajo utilizando el poder de spark.
- Despliegue del maniquí y monitoreo: puede habilitar endpoints fácilmente los cuales reciben una entrada en formato json y realiza la predicción con el maniquí entrenado.
- Reentrenamiento de maniquí automatizado: puedes crear alertas (webhook) y automatizarlas para tomar acto inmediata cuando el maniquí empieza a apearse su efectividad.
Una gran preeminencia a la hora de implementar modelos de ML en Databricks es que todo lo puedes hacer en un solo emplazamiento, por ejemplo, la extirpación y preparación de los datos lo haces con notebooks ya sea en Python, R, scala o SQL; el entrenamiento de modelos incluso lo puedes hacer mediante la programación de notebooks que leen datos desde tablas delta previamente creadas. En esquema, Databricks está presente en cada período del ciclo de vida de un esquema de ML iniciando desde la construcción de las ELTs para el procesamiento y la disponibilización de los datos hasta la creación de modelos con MLflow.
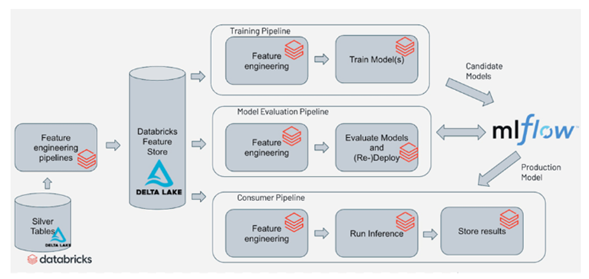
Según las recomendaciones de Databricks para la implementación de un maniquí de MLOps en esta plataforma, el esquema debe contemplar las siguientes fases:
- Período exploratoria de disección de datos (EDA): Se puede hacer con los notebooks en Databricks.
- Preparación de los datos e ingeniería de características: Para esta período es necesario escribir código ya sea en Python, R, Scala o SQL con el fin de automatizar las tareas de preparación de datos y guardarlas incrementalmente como tablas delta, para luego cruzarlos con otras fuentes y hacer la ingeniería de características.
- Entrenamiento del maniquí: En esta período se deben utilizar librerías especializadas para el entrenamiento de modelos de ML tales como tensorflow, skitLearn y xgboost; Databricks ofrece cluster preconfigurados con este tipo de librerías.
- Revisión y establecimiento del maniquí: Databricks permite la implementación del paquete mlflow para defender versiones de modelos de machine Learning y designar el de mejor rendimiento.
- Inferencia de maniquí y puesta en producción: Internamente de Databricks se pueden realizar predicciones en tiempo verdadero a través de endpoints o predicciones en gajo utilizando el poder de spark.
- Despliegue del maniquí y monitoreo: puede habilitar endpoints fácilmente los cuales reciben una entrada en formato json y realiza la predicción con el maniquí entrenado.
- Reentrenamiento de maniquí automatizado: puedes crear alertas (webhook) y automatizarlas para tomar acto inmediata cuando el maniquí empieza a apearse su efectividad.
Una gran preeminencia a la hora de implementar modelos de ML en Databricks es que todo lo puedes hacer en un solo emplazamiento, por ejemplo, la extirpación y preparación de los datos lo haces con notebooks ya sea en Python, R, scala o SQL; el entrenamiento de modelos incluso lo puedes hacer mediante la programación de notebooks que leen datos desde tablas delta previamente creadas. En esquema, Databricks está presente en cada período del ciclo de vida de un esquema de ML iniciando desde la construcción de las ELTs para el procesamiento y la disponibilización de los datos hasta la creación de modelos con MLflow.
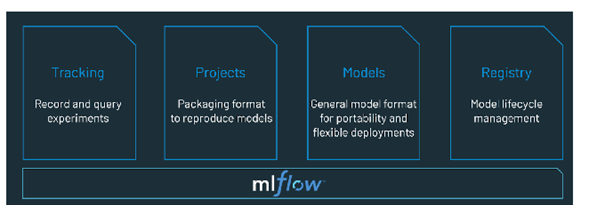
En conclusión, si está pensando en implementar una decisión de Machine Learning que sea escalable y confiable, debería revisar la implementación de MLOps para la establecimiento y monitoreo. Por otra parte, es importante tener en cuenta que una de las mejores herramientas para implementarlo es Databricks, ya que como se mencionó anteriormente ofrece todo en un solo emplazamiento y sin complicaciones a la hora de configurar los ambientes tanto para avance como para producción.