
Los LLM ya no están restringidos a un formato de respuesta-respuesta. Ahora forman la cojín de aplicaciones inteligentes que ayudan con los problemas del mundo existente en tiempo existente. En ese contexto, Kimi K2 viene como un LLM de múltiples usos que es inmensamente popular entre los usuarios de IA en todo el mundo. Si adecuadamente todos conocen sus poderosas capacidades de agente, no muchos están seguros de cómo se desempeña en la API. Aquí, probamos a Kimi K2 en un escena de producción del mundo existente, a través de un flujo de trabajo basado en API para evaluar si Kimi K2 defiende su promesa de una gran LLM.
Lea igualmente: ¿Quieres encontrar el mejor sistema de código despejado? Lea nuestra revisión de comparación entre Kimi K2 y Fogosidad 4 aquí.
¿Qué es Kimi K2?
Kimi K2 es un maniquí de habla despejado de código despejado de última reproducción construido por Moonshot AI. Emplea un Inmueble de mezcla de expertos (MOE) y tiene 1 billón de parámetros totales (32 mil millones activados por token). Kimi K2 incorpora particularmente los casos de uso de pensamiento a futuro para la inteligencia agente avanzadilla. Es capaz no solo de crear y comprender el habla natural, sino igualmente de resolver autónomos problemas complejos, utilizar herramientas y completar tareas de varios pasos en una amplia serie de dominios. Cubrimos todo sobre su punto de narración, rendimiento y puntos de golpe en detalle en un artículo precursor: Kimi K2 El mejor maniquí de agente de código despejado.
Variantes de maniquí
Hay dos variantes de Kimi K2:
- Saco Kimi-K2: El maniquí fundamental, un excelente punto de partida para investigadores y constructores que desean tener un control total sobre las soluciones personalizadas y personalizadas.
- Kimi-K2-Instructo: El maniquí post-entrenado que es mejor para un chat de uso caudillo y una experiencia de agente. Es un maniquí de punto refleja sin pensamiento profundo.
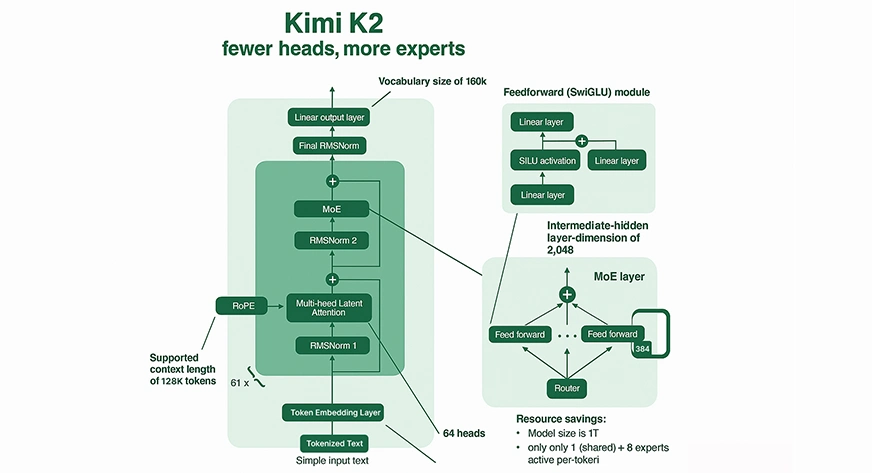
Mecanismo de mezcla de expertos (MOE)
Cálculo fraccional: Kimi K2 no activa todos los parámetros para cada entrada. En cambio, Kimi K2 enruta cada token en 8 de sus 384 «expertos» especializados (más un perito compartido), que ofrece una disminución significativa en el cálculo por inferencia en comparación con el maniquí MOE y los modelos densos de tamaño comparable.
Especialización de expertos: Cada perito adentro del MOE se especializa en diferentes dominios de conocimiento o patrones de razonamiento, lo que lleva a resultados ricos y eficientes.
Enrutamiento escaso: Kimi K2 utiliza actividades inteligentes para enrutar expertos relevantes para cada token, lo que respalda tanto la capacidad enorme como la inferencia computacionalmente factible.
Atención y contexto
Ventana de contexto masivo: Kimi K2 tiene una largura de contexto de hasta 128,000 tokens. Puede procesar documentos o bases de código extremadamente largos en un solo pase, una ventana de contexto sin precedentes, que excede la mayoría de las LLM heredadas.
Atención compleja: El maniquí tiene 64 cabezales de atención por capa, lo que le permite rastrear y utilizar relaciones y dependencias complicadas en la secuencia de tokens, típicamente hasta 128,000.
Entrenamiento de innovaciones
Muonclip Optimizer: Para permitir el entrenamiento estable a esta escalera sin precedentes, Moonshot Ai desarrolló un nuevo optimizador llamado Muonclip. Limpia la escalera de los logits de atención al reescalizar las matrices de consulta y peso secreto en cada modernización para evitar la inestabilidad extrema (es sostener, títulos explosivos) comunes en modelos a gran escalera.
Escalera de datos: Kimi K2 fue previamente entrenado en 15.5 billones de tokens, lo que desarrolla el conocimiento y la capacidad del maniquí para difundir.
¿Cómo ceder a Kimi K2?
Como se mencionó, se puede ceder a Kimi K2 de dos maneras:
Interfaz web/de aplicación: Se puede ceder a Kimi instantáneamente para su uso desde el chat web oficial.
API: Kimi K2 se puede integrar con su código utilizando la API juntas o la API de Moonshot, que admite flujos de trabajo de agente y el uso de herramientas.
Pasos para obtener una secreto API
Para ejecutar Kimi K2 a través de una API, necesitará una secreto API. Aquí está cómo conseguirlo:
API Moonshot:
- Regístrese o inicie sesión en la consola de desarrollador de IA Moonshot.
- Vaya a la sección «API Keys».
- Haga clic en «Crear tecla API», proporcione un nombre y plan (o deje como predeterminado), luego guarde su secreto para su uso.
Juntos AI API:
- Regístrese o inicie sesión en juntos ai.
- Localice el radio de «teclas API» en su tablero.
- Genere una nueva secreto y registela para su uso posterior.
Instalación particular
Descargue los pesos de abrazar la cara o el github y ejecutarlos localmente con VLLM, Tensorrt-Llm o Sglang. Simplemente siga estos pasos.
Paso 1: crear un entorno de Python
Uso de condena:
conda create -n kimi-k2 python=3.10 -y
conda activate kimi-k2Usando Venv:
python3 -m venv kimi-k2
source kimi-k2/bin/activatePaso 2: Instale las bibliotecas requeridas
Para todos los métodos:
pip install torch transformers huggingface_hubVLLM:
pip install vllmTensorrt-llm:
Siga el oficial (documentación de instalación tensorrt-llm) (requiere pytorch> = 2.2 y cuda == 12.x; no PIP instalable para todos los sistemas).
Para Sglang:
pip install sglangPaso 3: Descargar pesos del maniquí
De la cara abrazada:
Con git-lfs:
git lfs install
git clone https://huggingface.co/moonshot-ai/Kimi-K2-InstructO usar huggingface_hub:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="moonshot-ai/Kimi-K2-Instruct",
local_dir="./Kimi-K2-Instruct",
local_dir_use_symlinks=False,
)Paso 4: Verifique su entorno
Para certificar que CUDA, Pytorch y las dependencias estén listas:
import torch
import transformers
print(f"CUDA Available: {torch.cuda.is_available()}")
print(f"CUDA Devices: {torch.cuda.device_count()}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"Transformers Version: {transformers.__version__}")Paso 5: Ejecute Kimi K2 con su backend preferido
Con vllm:
python -m vllm.entrypoints.openai.api_server
--model ./Kimi-K2-Instruct
--swap-space 512
--tensor-parallel-size 2
--dtype float16Ajuste el tensor-paralelo y el dtype en función de su hardware. Reemplace con pesos cuantificados si usa variantes int8 o de 4 bits.
Práctico con Kimi K2
En este entrenamiento, echaremos un vistazo a cómo los grandes modelos de idiomas como Kimi K2 funcionan en la vida existente con llamadas de API reales. El objetivo es probar su competencia en movimiento y ver si proporciona un rendimiento esforzado.
Tarea 1: Creación de un padre de informes de 360 ° usando Langgraph y Kimi K2:
En esta tarea, crearemos un padre de informes de 360 grados utilizando el Entorno de langgraph y el Kimi K2 LLM. La aplicación es una muestra de cómo los flujos de trabajo de agente se pueden coreografiar para recuperar, procesar y resumir la información automáticamente mediante el uso de interacciones API.
Enlace de código: https://github.com/sjsoumil/tutorials/blob/main/kimi_k2_hands_on.py
Salida del código:
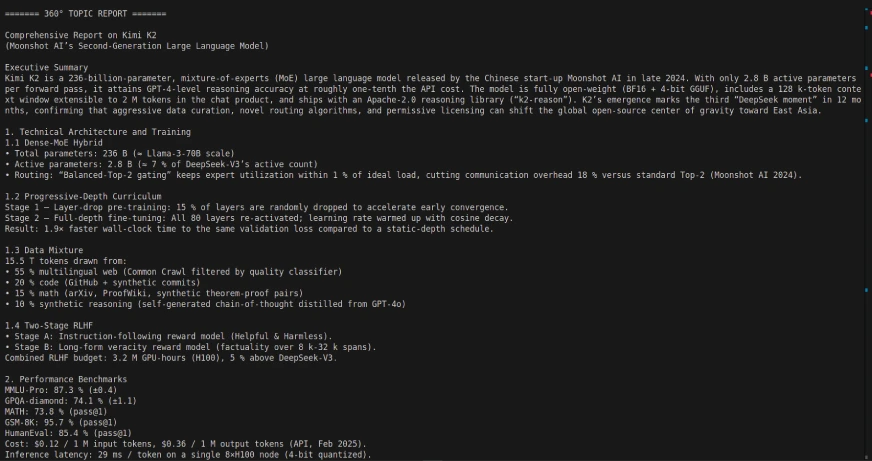
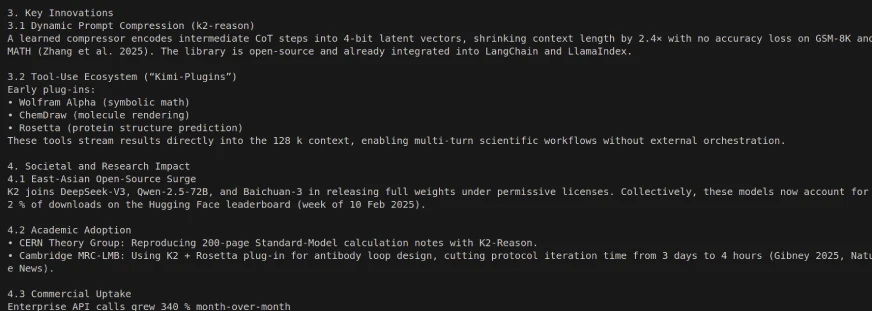
El empleo de Kimi K2 con Langgraph puede permitir un flujo de trabajo de agente de múltiples pasos potente y autónomo, ya que Kimi K2 está diseñada para descomponer autónomas tareas de múltiples pasos, como consultas de bases de datos, informes y procesamiento de documentos, utilizando integraciones de herramientas/API. Simplemente modifique sus expectativas para algunos de los tiempos de respuesta.
Tarea 2: Crear un chatbot simple usando Kimi K2
Código:
from dotenv import load_dotenv
import os
from openai import OpenAI
load_dotenv()
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
if not OPENROUTER_API_KEY:
raise EnvironmentError("Please set your OPENROUTER_API_KEY in your .env file.")
client = OpenAI(
api_key=OPENROUTER_API_KEY,
base_url="https://openrouter.ai/api/v1"
)
def kimi_k2_chat(messages, model="moonshotai/kimi-k2:free", temperature=0.3, max_tokens=1000):
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
return response.choices(0).message.content
# Conversation loop
if __name__ == "__main__":
history = ()
print("Welcome to the Kimi K2 Chatbot (type 'exit' to quit)")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
history.append({"role": "user", "content": user_input})
reply = kimi_k2_chat(history)
print("Kimi:", reply)
history.append({"role": "assistant", "content": reply})Producción:
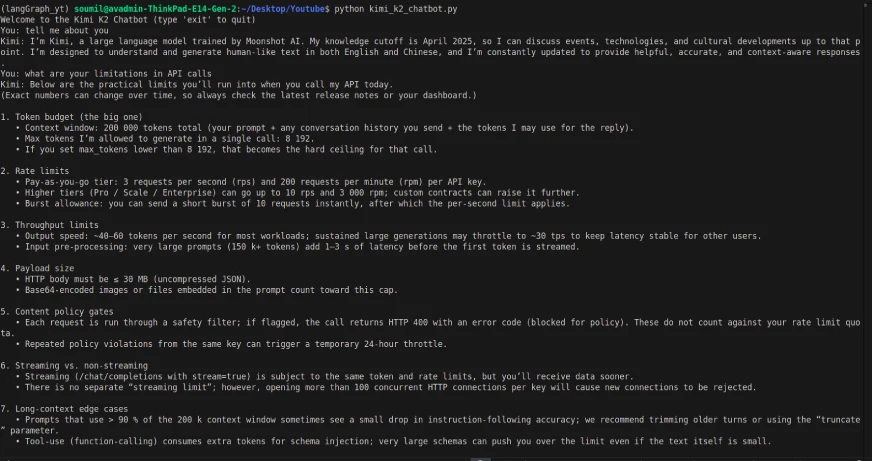
A pesar de que el maniquí era multimodal, las llamadas API solo tenían la capacidad de proporcionar entrada/salida basada en texto (y la entrada de texto tenía un retraso). Entonces, la interfaz y la API llamadas actúan de forma un poco diferente.
Mi revisión luego de la ejercicio
El Kimi K2 es un maniquí de habla despejado y de código despejado, lo que significa que es de gorra, y esta es una gran delantera para los desarrolladores e investigadores. Para este entrenamiento, accedí a Kimi K2 con una zancadilla API OpenRouter. Si adecuadamente accedí previamente al maniquí a través de la interfaz web hacedero de usar, preferí usar la API para obtener más flexibilidad y construir un flujo de trabajo de agente personalizado en Langgraph.
Durante la prueba del chatbot, los tiempos de respuesta que experimenté con las llamadas API se retrasaron notablemente, y el maniquí no puede, sin bloqueo, conceder capacidades multimodales (por ejemplo, procesamiento de imágenes o archivos) a través de la API como puede en la interfaz. De todos modos, el maniquí funcionó adecuadamente con Langgraph, lo que me permitió diseñar una tubería completa para crear informes dinámicos de 360 °.
Si adecuadamente no fue devastador, ilustra cómo modelos de código despejado Se están poniendo al día con los líderes propietarios, como Operai y Gemini, y continuarán cerrando los huecos con modelos como Kimi K2. Es un rendimiento y flexibilidad impresionante para un maniquí de balde, y muestra que la mostrador está aumentando en capacidades multimodales con LLM que son de código despejado.
Conclusión
Kimi K2 es una gran opción en el panorama LLM de código despejado, especialmente para flujos de trabajo de agente y facilidad de integración. Si adecuadamente nos encontramos con algunas limitaciones, como los tiempos de respuesta más lentos a través de API y la descuido de soporte de multimodalidad, proporciona un excelente espacio para comenzar a desarrollar aplicaciones inteligentes en el mundo existente. Encima, no tener que enriquecer por estas capacidades es una gran delantera que ayuda a desarrolladores, investigadores y nuevas empresas. A medida que el ecosistema evoluciona y madura, veremos modelos como Kimi K2 obteniendo capacidades avanzadas rápidamente a medida que cierran rápidamente la brecha con compañías patentadas. En caudillo, si está considerando LLM de código despejado para el uso de producción, Kimi K2 es una posible opción que vale la pena su tiempo y experimentación.
Preguntas frecuentes
A. Kimi K2 es el maniquí de habla ínclito de la próxima reproducción de lunarshot Ai (MOE) con 1 billón de parámetros totales (32 mil millones de parámetros activados por interacción). Está diseñado para tareas de agente, razonamiento liberal, reproducción de códigos y uso de herramientas.
– Procreación y depuración de código liberal
– Ejecución de tareas de agente automatizado
-Razonamiento y resolución de problemas complejos de múltiples pasos
– Observación y visualización de datos
– Planificación, concurso de investigación y creación de contenido
– Inmueble: Transformador de mezcla de expertos
– Parámetros totales: 1T (billón)
– Parámetros activados: 32B (mil millones) para cada consulta
– Distancia del contexto: Hasta 128,000 tokens
– Especialización: Uso de herramientas, flujos de trabajo de agente, codificación, procesamiento de secuencias largas
– Camino de API: Habitable en la consola API de Moonshot AI (y igualmente apoyada desde juntos AI y Openrouter)
– Despliegue particular: Posible localmente; requiere un potente hardware particular típicamente (para el uso efectivo requiere múltiples GPU de inscripción serie)
– Variantes del maniquí: Arrojado como «Kimi-K2-Saco» (para personalización/ajuste fino) y «Kimi-K2-Instructo» (para chat de uso caudillo, interacciones de agente).
A. Kimi K2 generalmente equivale o excede, liderando modelos de código despejado (por ejemplo, Deepseek V3, Qwen 2.5). Es competitivo con modelos propietarios en puntos de narración para la codificación, el razonamiento y las tareas de agente. ¡Todavía es notablemente apto y de bajo costo en comparación con otros modelos de escalera similar o beocio!
Verificado de datos | AWS Certified Solutions Architect | AI y ML Progresista
Como investigador de datos en Analytics Vidhya, me especializo en estudios automotriz, estudios profundo y soluciones impulsadas por IA, aprovechando las tecnologías de la PNL, la visión por computadora y la cirro para construir aplicaciones escalables.
Con un B.Tech en Ciencias de la Computación (ciencia de datos) de VIT y certificaciones como el arquitecto de soluciones certificadas de AWS y TensorFlow, mi trabajo zapatilla la IA generativa, la detección de anomalías, la detección de informativo falsas y el inspección de emociones. Apasionado por la innovación, me esfuerzo por desarrollar sistemas inteligentes que dan forma al futuro de la IA.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.