
Recientemente anunciamos el Disponibilidad caudillo de nuestra computación sin servidor Ofertas para Notebooks, Jobs y Pipelines. La computación sin servidor ofrece un inicio rápido de la carga de trabajo, escalamiento necesario de la infraestructura y actualizaciones de versiones sin inconvenientes del entorno de ejecución de Databricks. Nos comprometemos a seguir innovando con nuestra proposición sin servidor y a mejorar continuamente la relación precio/rendimiento para sus cargas de trabajo. Hoy nos complace hacer algunos anuncios que ayudarán a mejorar su experiencia de costos sin servidor:
- Mejoras de eficiencia que resultan en un viejo que Reducción de costes del 25% para la mayoría de los clientes, especialmente aquellos con cargas de trabajo de corta duración.
- Maduro observabilidad de los costos que ayuda a rastrear y monitorear el desembolso a nivel individual de Notebook, Job y Pipeline.
- Controles simples (disponibles en el futuro) para trabajos y pipelines que Le permite indicar una preferencia para optimizar la ejecución de la carga de trabajo en función del costo sobre el rendimiento..
- Disponibilidad continua de la 50% de descuento introductorio en nuestras nuevas ofertas de computación sin servidor para trabajos y pipelines, y un 30 % para notebooks.
Mejoras de eficiencia
Basándonos en los conocimientos adquiridos a partir de la ejecución de cargas de trabajo de los clientes, hemos implementado mejoras de eficiencia que permitirán a la mayoría de los clientes conseguir una reducción del 25 % o más en su desembolso informático sin servidor. Estas mejoras reducen principalmente el costo de las cargas de trabajo cortas. Estos cambios se implementarán automáticamente en las próximas semanas, lo que garantiza que sus Notebooks, Jobs y Pipelines se beneficien de estas actualizaciones sin carencia de realizar ninguna hecho.
Maduro observabilidad de los costos
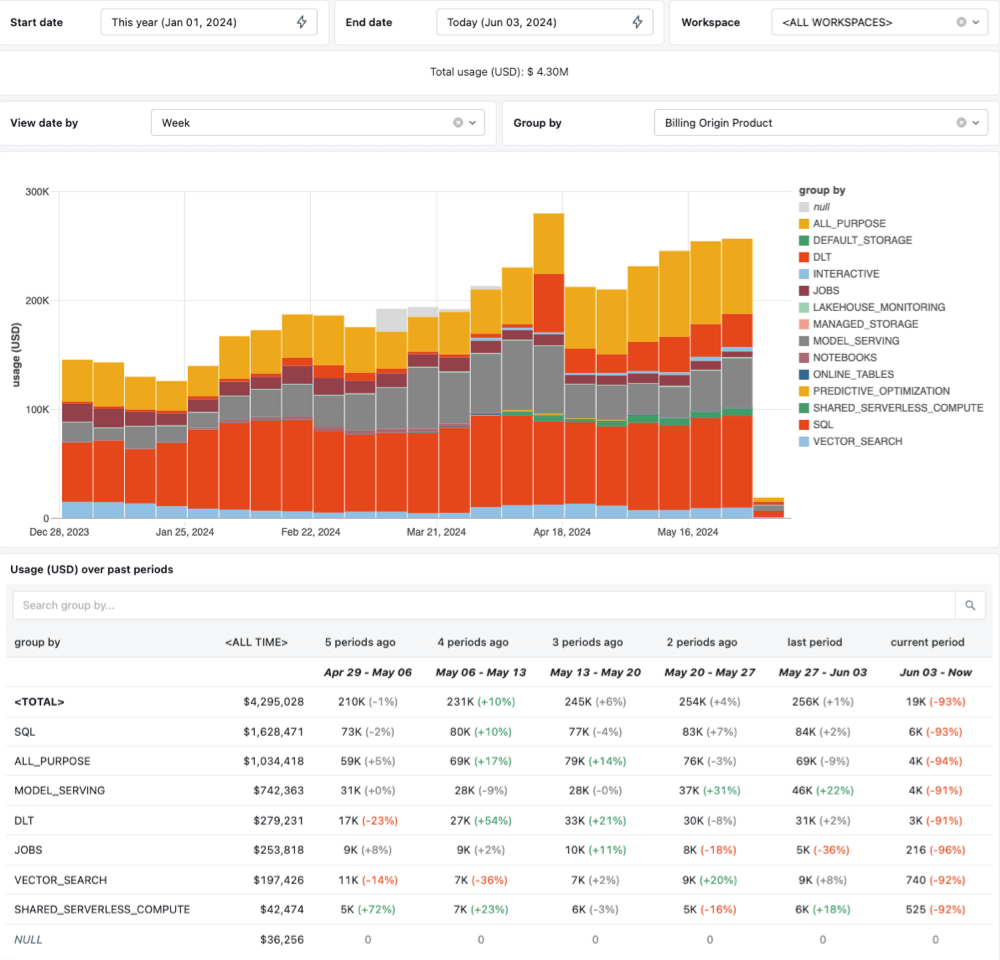
Para que la mandato de costos sea más transparente, hemos mejorado nuestras capacidades de seguimiento de costos. Todos los costos de enumeración asociados con la tecnología sin servidor ahora se podrán rastrear completamente hasta la ejecución individual de Notebook, Job o Pipeline. Esto significa que ya no verá costos de enumeración compartidos sin servidor que no estén atribuidos a ninguna carga de trabajo en particular. Esta atribución granular brinda visibilidad del costo total de cada carga de trabajo, lo que facilita el monitoreo y la mandato de los gastos. Encima, hemos asociado nuevos campos a la tabla del sistema de uso facturable, incluido el nombre del trabajo, la ruta de Notebook y la identidad del heredero para Pipelines para simplificar los informes de costos. Hemos creado una plantilla de panel que facilita la visualización de las tendencias de costos en sus espacios de trabajo. Puede obtener más información y descargar la plantilla aquí.
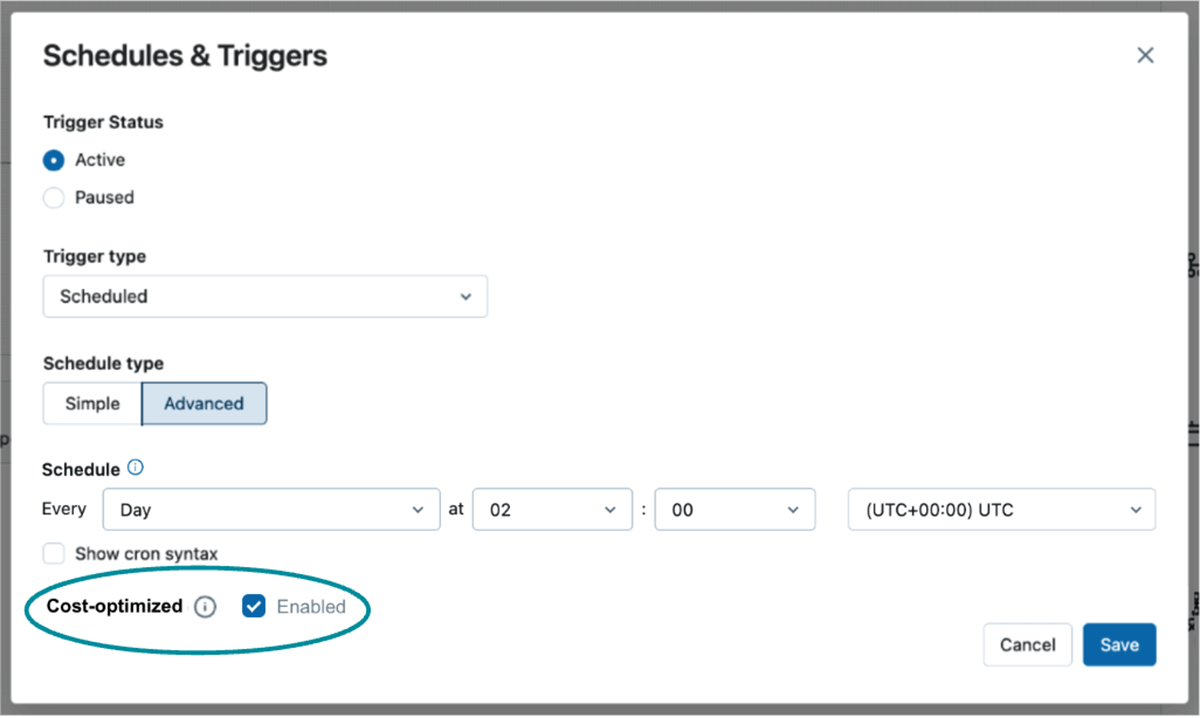
Controles futuros que le permiten indicar una preferencia por la optimización de costos
Para cada una de las cargas de trabajo de su plataforma de datos, debe determinar el estabilidad adecuado entre rendimiento y costo. Con la computación sin servidor, nos comprometemos a simplificar la forma en que cumple con los objetivos de precio y rendimiento de sus cargas de trabajo específicas. Actualmente, nuestra proposición sin servidor se centra en el rendimiento: optimizamos la infraestructura y administramos nuestra flota de computación para que sus cargas de trabajo experimenten un inicio rápido y tiempos de ejecución cortos. Esto es ideal para cargas de trabajo con micción de mengua latencia y cuando no desea gobernar ni retribuir por grupos de instancias.
Sin bloqueo, incluso hemos escuchado sus comentarios sobre la carencia de opciones más rentables para ciertos trabajos y pipelines. Para algunas cargas de trabajo, está dispuesto a inmolar poco de tiempo de inicio o velocidad de ejecución para ceñir los costos. En respuesta, estamos encantados de presentar un conjunto de controles simples y directos que le permiten priorizar el parquedad de costos sobre el rendimiento. Esta nueva flexibilidad le permitirá personalizar su táctica de enumeración para cumplir mejor con los requisitos específicos de precio y rendimiento de sus cargas de trabajo. Esté atento a más actualizaciones sobre este emocionante exposición en los próximos meses y suscríbase a la cinta de paciencia de presencia previa. aquí.
¡Desbloquea un parquedad del 50 % en computación sin servidor: proposición introductoria por tiempo circunscrito!
Aproveche nuestros descuentos introductorios: obtenga un 50 % de descuento en computación sin servidor para Empleos y Tuberías y 30% de descuento para Cuadernosapto hasta el 31 de octubre de 2024. ¡Esta proposición por tiempo circunscrito es la oportunidad perfecta para explorar la computación sin servidor a un costo estrecho! ¡No la dejes ocurrir!
Comience a utilizar la computación sin servidor hoy mismo:
- Habilite el procesamiento sin servidor en su cuenta en AWS o Azur
- Asegúrese de que su espacio de trabajo esté Capacitado para utilizar Unity Catalog y en una región apoyada en AWS o Azur
- Para las cargas de trabajo de PySpark existentes, asegúrese de que sean compatibles con modo de comunicación compartido y Lectura 14.3+ de DBR
- Siga las instrucciones específicas para conectar su Cuadernos, Empleos, Tuberías Para computación sin servidor
- Aproveche la computación sin servidor desde cualquier sistema de terceros utilizando Conexión de DatabricksDesarrolle localmente desde su IDE o integre sin problemas sus aplicaciones con Databricks en Python para un flujo de trabajo fluido y capaz.