
Amazon SageMaker ahora alivio los resultados de búsqueda en Estudio unificado de Amazon SageMaker con contexto adicional que alivio la transparencia y la interpretabilidad. Los usuarios pueden ver qué campos de metadatos coinciden con su consulta y comprender por qué aparece cada resultado, lo que aumenta la claridad y la confianza en el descubrimiento de datos. La capacidad introduce resaltado en raya para términos coincidentes y un panel de explicación que detalla dónde y cómo ocurrió cada coincidencia en campos de metadatos como nombre, descripción, diccionario y esquema. Los resultados de búsqueda mejorados reducen el tiempo dedicado a evaluar activos irrelevantes al presentar evidencia de coincidencias directamente en los resultados de búsqueda. Los usuarios pueden validar rápidamente la relevancia sin analizar activos individuales.
En esta publicación, demostramos cómo utilizar la búsqueda mejorada en Amazon SageMaker.
Resultados de búsqueda con contexto
Las coincidencias de texto incluyen concordancia de palabras secreto, comienza con, sinónimos y texto semánticamente relacionado. La búsqueda mejorada muestra coincidencias de texto de resultados de búsqueda en estas ubicaciones:
- Resultado de la búsqueda: Se resaltan las coincidencias de texto en el nombre, la descripción y los términos del diccionario de cada resultado de búsqueda.
- Acerca de este panel de resultados: Un nuevo Acerca de este resultado El panel se muestra a la derecha del resultado de búsqueda resaltado. El panel muestra las coincidencias de texto para el contenido de búsqueda del medio ambiente de resultado, incluido el nombre, la descripción, los términos del diccionario, los metadatos, los nombres comerciales y el esquema de la tabla. La repertorio de títulos únicos de coincidencia de texto se muestra en la parte superior del panel para una narración rápida.
Los catálogos de datos contienen miles de conjuntos de datos, modelos y proyectos. Sin transparencia, los usuarios no pueden enterarse por qué aparecen ciertos resultados ni dejarlo en Dios en el pedido. Los usuarios necesitan evidencia para la relevancia y comprensibilidad de la búsqueda.
La búsqueda mejorada con explicaciones de coincidencias alivio la búsqueda en el catálogo de cuatro maneras secreto:
1) la transparencia aumenta porque los usuarios pueden ver por qué apareció un resultado y ingresar confianza,
2) la eficiencia alivio ya que los aspectos destacados y las explicaciones reducen el tiempo dedicado a cascar activos irrelevantes,
3) la gobernanza se respalda al mostrar dónde y cómo coinciden los términos, lo que ayuda a los procesos de auditoría y cumplimiento, y
4) la coherencia se refuerza al revelar el diccionario y las relaciones semánticas, lo que reduce los malentendidos y alivio la colaboración entre equipos.
Cómo funciona la búsqueda mejorada
Cuando un sucesor ingresa una consulta, el sistema escudriñamiento en múltiples campos como nombre, descripción, términos del diccionario, metadatos, nombres comerciales y esquema de tabla. Con una transparencia de búsqueda mejorada, cada resultado de búsqueda incluye la repertorio de coincidencias de texto que fueron la almohadilla para incluir el resultado, incluido el campo que contenía la coincidencia de texto y una parte del valencia de texto del campo antaño y posteriormente de la coincidencia de texto, para proporcionar contexto. La interfaz de sucesor utiliza esta información para mostrar el texto devuelto con la coincidencia de texto resaltada.
Por ejemplo, un delegado escudriñamiento «pronóstico de ingresos» y se devuelve un activo con el nombre «Conjunto de datos de pronóstico de ventas Q2» y una descripción que contiene «cifras de ventas proyectadas». la palabra ventas está resaltado en el nombre y la descripción, tanto en el resultado de la búsqueda como en el panel de coincidencias de texto, porque ventas es igual de ingresos. El panel Acerca de este resultado igualmente muestra que el pronóstico coincidió en el nombre del campo del esquema. ventas_forecast_q2.
Descripción normal de la opción
En esta sección demostramos cómo utilizar las funciones de búsqueda mejorada. En este ejemplo, demostraremos el uso en una campaña de marketing donde necesitamos datos de preferencias del sucesor. Si perfectamente contamos con múltiples conjuntos de datos sobre los usuarios, demostraremos cómo la búsqueda mejorada simplifica la experiencia de descubrimiento.
Requisitos previos
Para probar esta opción usted debe tener un Estudio unificado de Amazon SageMaker dominio configurado con privilegios de propietario de dominio o propietario de mecanismo de dominio. Asimismo debe tener un plan existente para informar activos y catalogar activos. Para obtener instrucciones para crear estos activos, consulte la Empezando dirección.
En este ejemplo, creamos un plan llamado Data_publish y cargamos datos desde Amazon Redshift. almohadilla de datos de muestra. Para ingerir los datos de muestra en SageMaker Catalog y crear metadatos comerciales, consulte Cree una fuente de datos de Amazon SageMaker Unified Studio para Amazon Redshift en el catálogo de proyectos.
Descubrimiento de activos con búsqueda explicable
Para agenciárselas activos con búsqueda explicable:
- Inicie sesión en SageMaker Unified Studio.
- Introduzca el texto de búsqueda
user-data. Si perfectamente obtenemos los resultados de la búsqueda en esta apariencia, queremos obtener más detalles sobre cada uno de estos conjuntos de datos. Presione enter para ir a la búsqueda completa.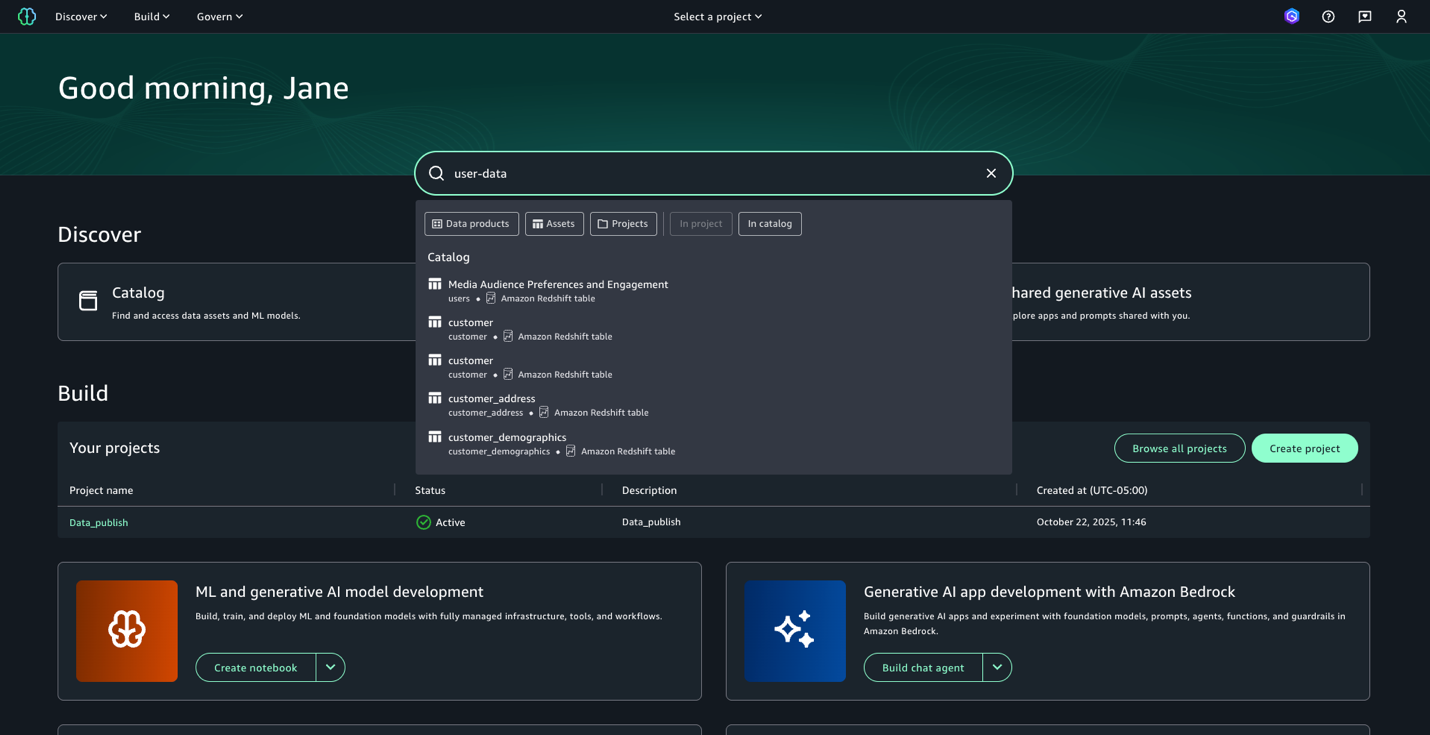
- En la búsqueda completa, los resultados de la búsqueda se devuelven cuando hay coincidencias de texto basadas en la búsqueda de palabras secreto, comienza con, igual y búsqueda semántica. Las coincidencias de texto se resaltan adentro del contenido de búsqueda que se muestra para cada resultado: en el nombre, la descripción y los términos del diccionario.
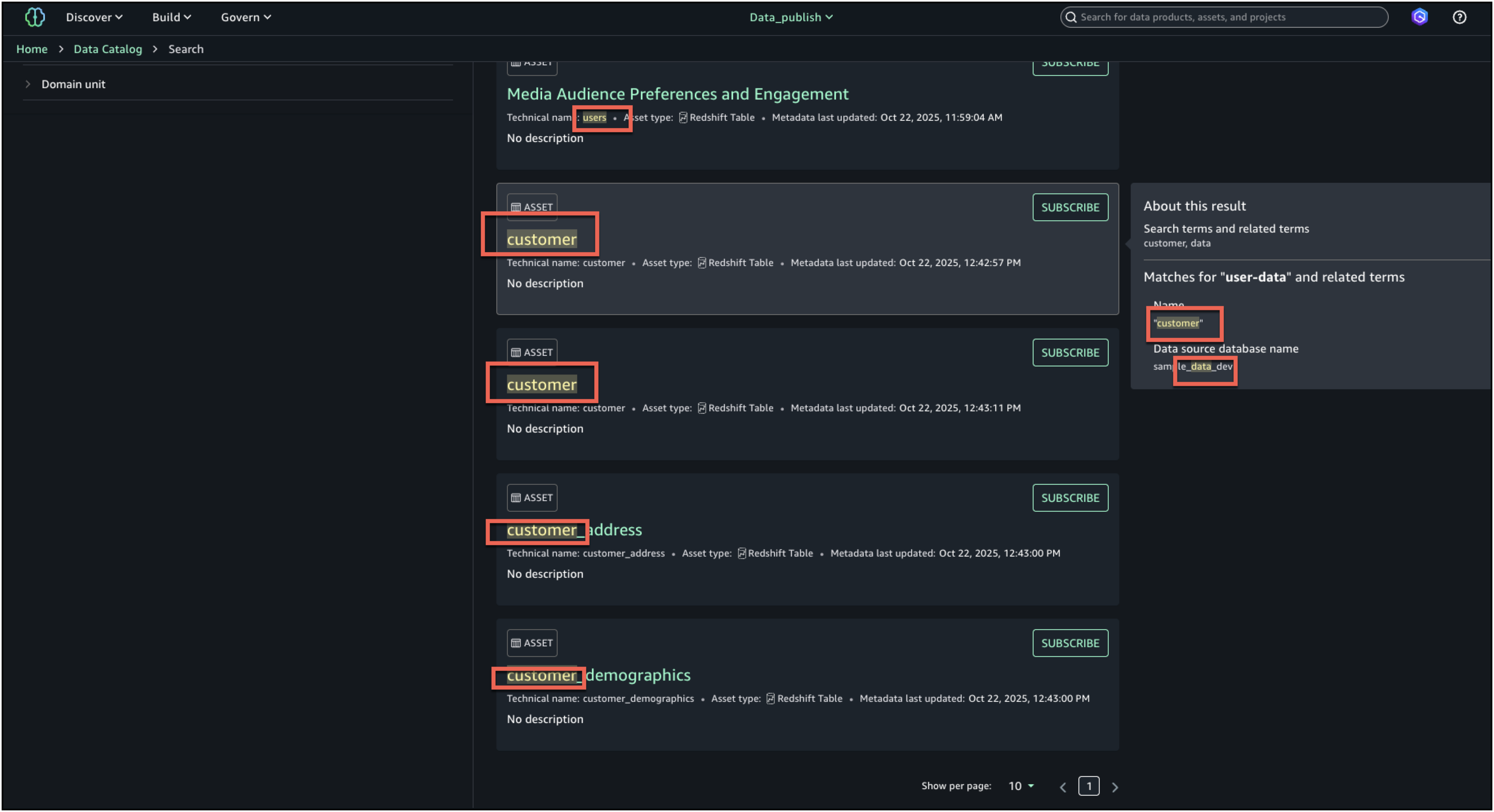
- Para mejorar aún más la experiencia de descubrimiento y encontrar el activo adecuado, puede consultar el Acerca de este resultado panel de la derecha y vea las otras coincidencias de texto, por ejemplo, en el extracto, el nombre de la tabla, el nombre de la almohadilla de datos de la fuente de datos o el nombre comercial de la columna, para comprender mejor por qué se incluyó el resultado.
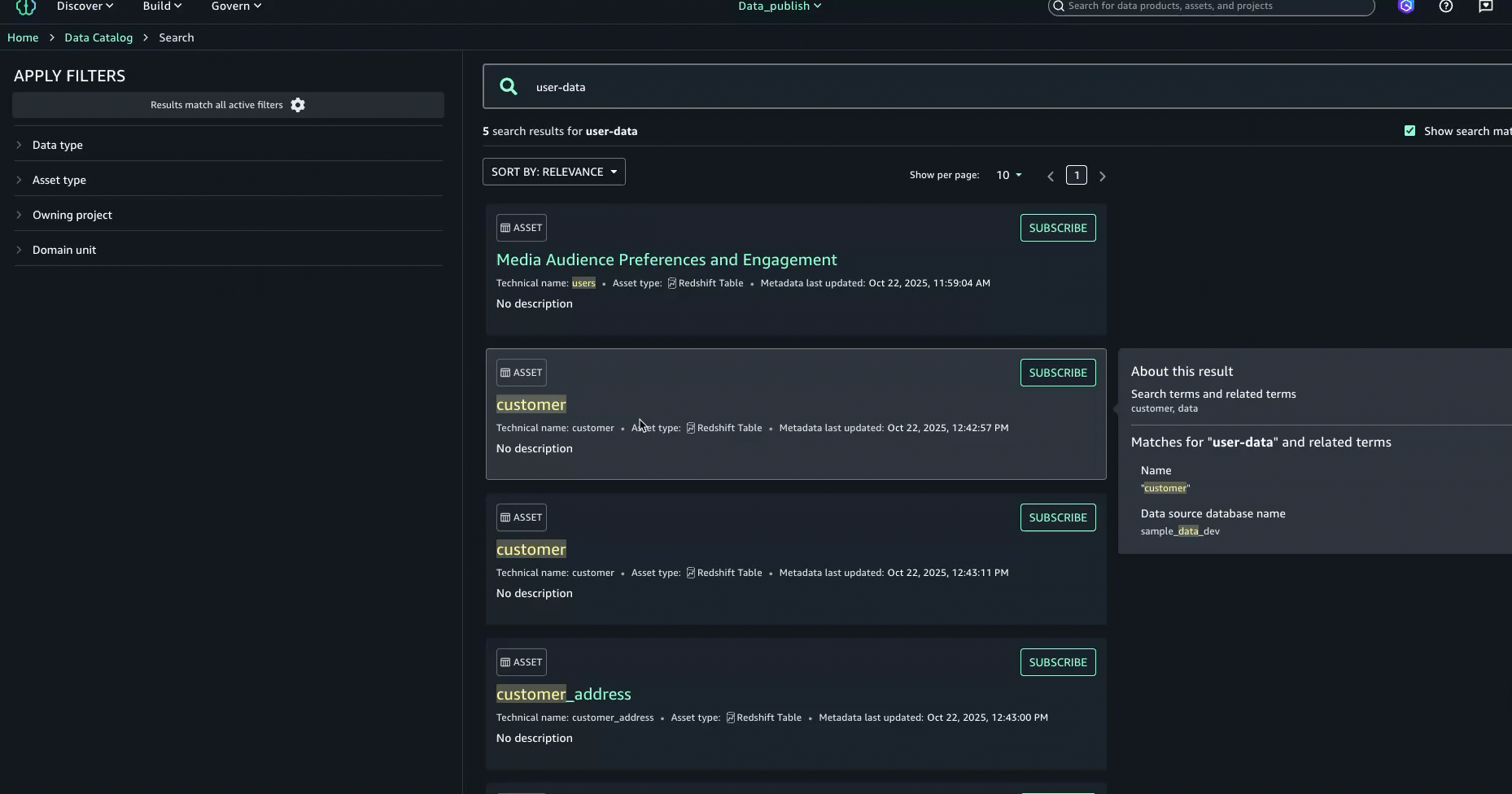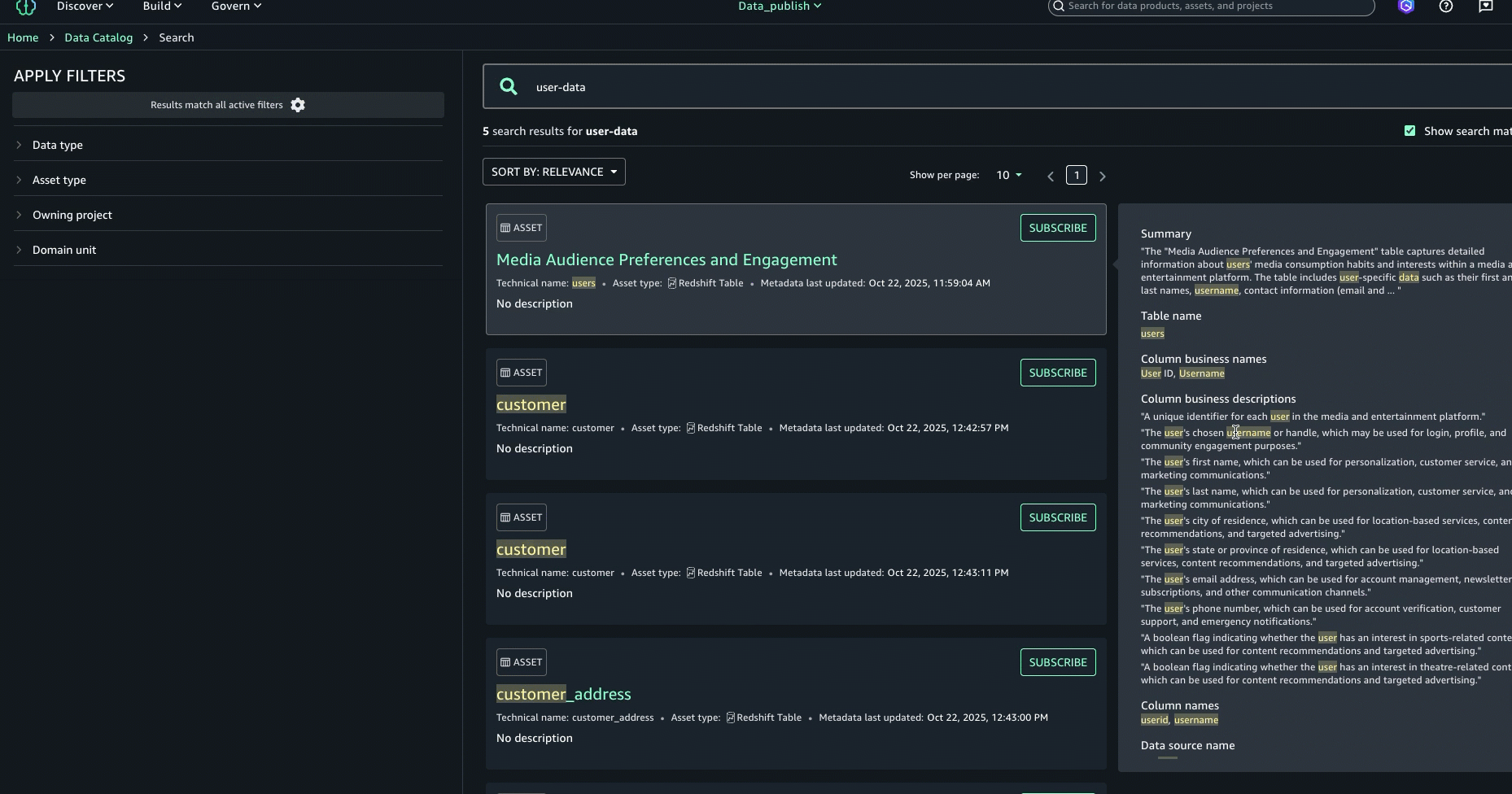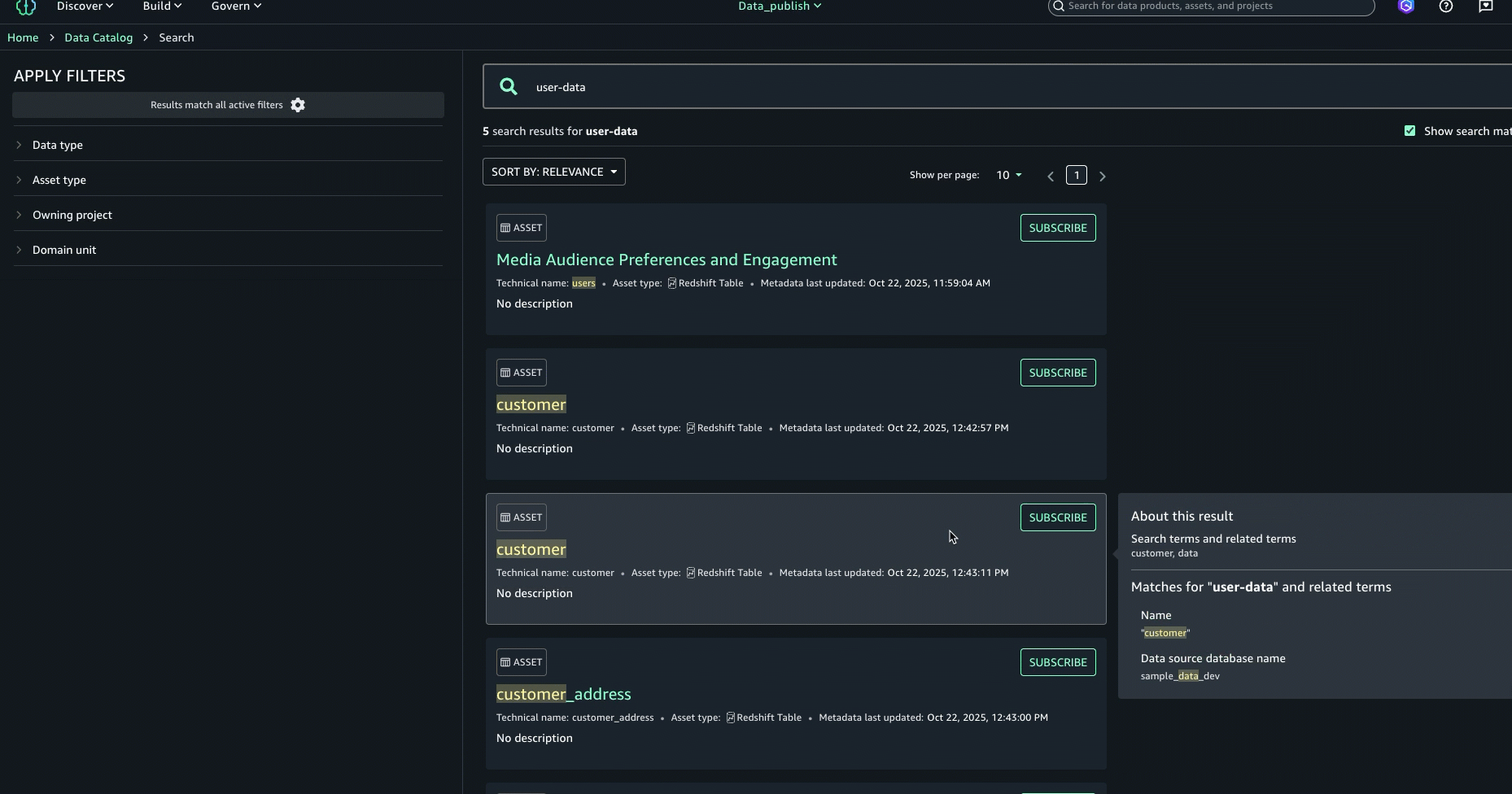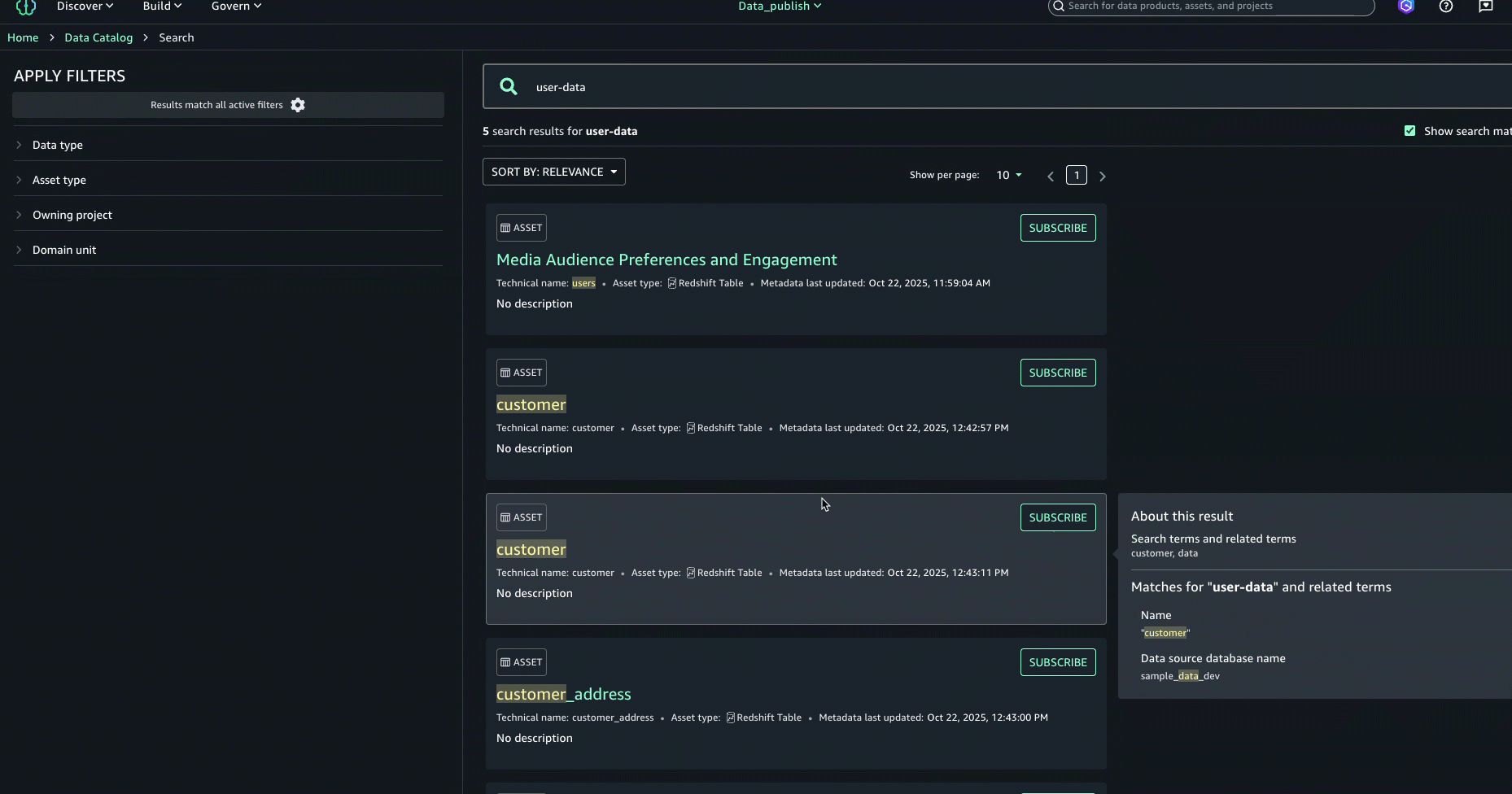
- A posteriori de examinar los resultados de la búsqueda y las explicaciones de coincidencia de texto, identificamos el activo denominado
Media Audience Preferences and Engagementcomo el activo adecuado para la campaña y lo seleccionó para su descomposición.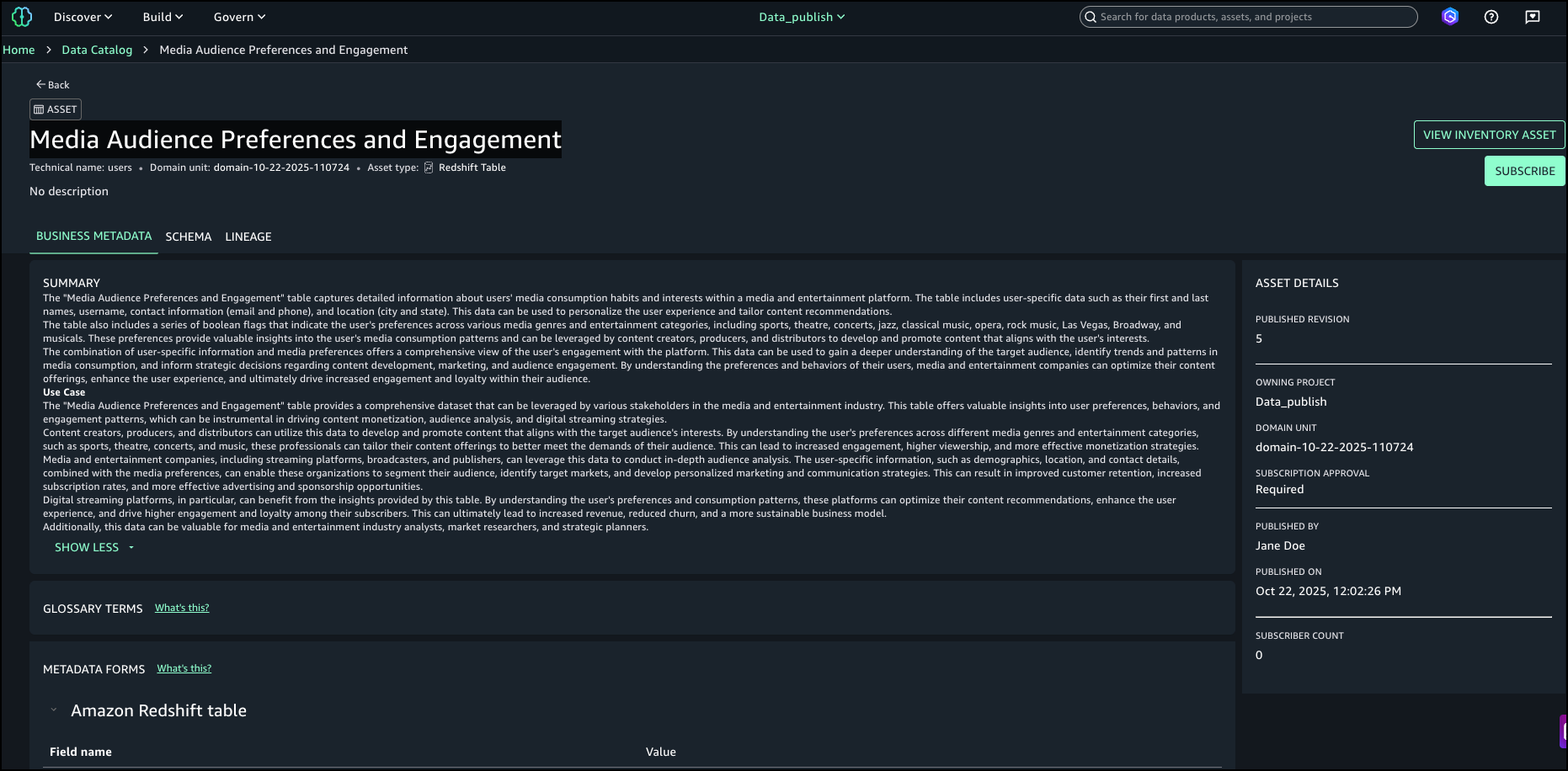
Conclusión
La transparencia de búsqueda mejorada en Amazon SageMaker Unified Studio transforma el descubrimiento de datos al alabar una visibilidad clara de por qué los activos aparecen en los resultados de búsqueda. El resaltado en raya y las explicaciones detalladas de las coincidencias ayudan a los usuarios a identificar rápidamente conjuntos de datos relevantes y, al mismo tiempo, generan confianza en el catálogo de datos. Al mostrar exactamente qué campos de metadatos coinciden con sus consultas, los usuarios dedican menos tiempo a evaluar activos irrelevantes y más tiempo a analizar los datos correctos para sus proyectos.
La búsqueda mejorada ahora está habitable en las regiones de AWS donde se admite Amazon SageMaker.
Para obtener más información sobre Amazon SageMaker, consulte Amazon SageMaker. documentación.
Sobre los autores