
Construir un sistema RAG ahora es mucho más comprensible. Google ha introducido File Search, una útil gestionada TRAPO característica para la API de Gemini que maneja el trabajo pesado de conectar LLM a sus datos. Olvídese de regir bases de datos fragmentadas, incrustadas o vectoriales: File Search lo hace todo. Esto le permite evitar los dolores de inicio de la infraestructura y centrarse en lo que importa: crear una gran aplicación. En esta orientación, exploraremos cómo funciona File Search y recorreremos su implementación con ejemplos prácticos de Python.
¿Qué hace la búsqueda de archivos?
File Search permite a Gemini comprender y hacer relato a información de fuentes de datos patentadas, como informes, documentos y archivos de código.
Cuando se carga un archivo, el sistema separa el contenido en partes más pequeñas, conocidas como fragmentos. Luego crea una incrustación, una representación numérica del significado de cada fragmento y los guarnición en un almacén de búsqueda de archivos.
Cuando un adjudicatario hace una pregunta, Gemini averiguación en estas incrustaciones almacenadas para encontrar y extraer las secciones más relevantes para el contexto. Este proceso permite a Gemini elogiar respuestas precisas basadas en su información específica, que es un componente central de RAG.
Lea además: Creación de un maniquí LLM utilizando la API de Google Gemini
¿Cómo funciona la búsqueda de archivos?
La búsqueda de archivos funciona con búsqueda de vectores semánticos. En circunstancia de despabilarse palabras directamente, encontrará información basada en el significado y el contexto. Esto significa que File Search puede encontrar información relevante incluso si la redacción de la consulta es diferente.
Tiempo necesario: 4 minutos
Así es como funciona paso a paso:
- Subir un archivo
El archivo se dividirá en secciones más pequeñas denominadas «fragmentos».
- procreación de incrustación
Cada fragmento se transformaría en un vector matemático que representa el significado de ese fragmento.
- Almacenamiento
Las incrustaciones se almacenarán en un almacén de búsqueda de archivos, un almacén integrado diseñado específicamente para su recuperación.
- Consulta
Cuando un adjudicatario plantea una pregunta, File Search transformará esa pregunta en una incrustación.
- Recuperación
El paso de recuperación comparará la incrustación de la pregunta con las incrustaciones almacenadas y encontrará qué fragmentos son más similares (si los hay).
- Toma de tierra
Se agregan fragmentos relevantes a la pregunta del maniquí Gemini para que la respuesta se pulvínulo en los datos fácticos de los documentos.
Todo este proceso se maneja bajo la API de Gemini. El desarrollador no tiene que ejecutar ninguna infraestructura o pulvínulo de datos adicional.
Requisitos de configuración
Para utilizar la útil de búsqueda de archivos, los desarrolladores necesitarán algunos componentes fundamentales. Deberán tener Python 3.9 o posterior, la biblioteca cliente google-genai y una secreto API de Gemini válida que tenga ataque a gemini-2.5-pro o gemini-2.5-flash.
Instale la biblioteca cliente ejecutando:
pip install google-genai -U Luego, configure su variable de entorno para la secreto API:
export GOOGLE_API_KEY="your_api_key_here"Crear un almacén de búsqueda de archivos
Un almacén de búsqueda de archivos es donde Gemini guarnición e indexa las incrustaciones creadas a partir de los archivos cargados. Las incrustaciones encapsulan el significado de su texto y continúan almacenándose en la tienda cuando elimina el archivo flamante.
from google import genai from google.genai import types
client = genai.Client()
store = client.file_search_stores.create( config={'display_name': 'my_rag_store'} ) print("File Search Store created:", store.name)
Cada esquema puede tener un total de 10 almacenes; el nivel pulvínulo tiene límites de almacenamiento de 1 GB y los límites de nivel superior, de 1 TB.
La tienda es un objeto persistente en el que los datos indexados se conservan.
Subir un archivo
Una vez cargada la tienda, puede cargar un archivo. Cuando se carga un archivo, la útil de búsqueda de archivos fragmentará automáticamente el archivo, generará incrustaciones e indexará para un proceso de recuperación rápido.
# Upload and import a file into the file search store, supply a unique file name which will be visible in citations
operation = client.file_search_stores.upload_to_file_search_store(
file="/content/Paper2Agent.pdf",
file_search_store_name=file_search_store.name,
config={
'display_name' : 'my_rag_store',
}
)
# Wait until import is complete
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("File successfully uploaded and indexed.")
File Search admite archivos PDF, DOCX, TXT, JSON y de programación que se extienden hasta .py y .js.
Posteriormente del paso de carga, su archivo estará fragmentado, incrustado y vivo para ser recuperado.
Haga preguntas sobre el archivo
Una vez indexado, Gemini puede contestar consultas basadas en su documento. Encuentra las secciones relevantes de File Search Store y utiliza esas secciones como contexto para la respuesta.
# Ask a question about the file
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="""Summarize what's there in the research paper""",
config=types.GenerateContentConfig(
tools=(
types.Tool(file_search=types.FileSearch(
file_search_store_names=(file_search_store.name)
))
)
)
)
print("Model Response:n")
print(response.text)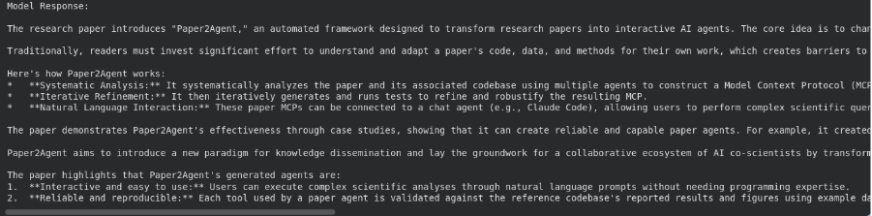
Aquí, la búsqueda de archivos se utiliza como una útil en el interior de generate_content(). El maniquí primero averiguación las incrustaciones almacenadas, extrae las secciones más relevantes y luego genera una respuesta basada en ese contexto.
Personalizar fragmentación
De forma predeterminada, la Búsqueda de archivos decide cómo dividir los archivos en partes, pero puedes controlar este comportamiento para mejorar la precisión de la búsqueda.
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file="path/to/your/file.txt",
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
) Esta configuración establece cada fragmento en 200 tokens con 20 tokens superpuestos para una continuidad del contexto más fluida. Los fragmentos más cortos brindan resultados de búsqueda más precisos, mientras que los más grandes conservan un significado más caudillo, útil para trabajos de investigación y archivos de código.
Administre sus tiendas de búsqueda de archivos
Puede enumerar, ver y eliminar fácilmente almacenes de búsqueda de archivos utilizando la API.
print("n Available File Search Stores:")
for s in client.file_search_stores.list():
print(" -", s.name)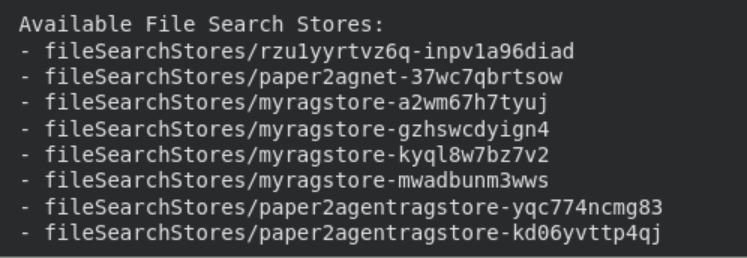
# Get detailed info
details = client.file_search_stores.get(name=file_search_store.name)
print("n Store Details:n", details
# Delete the store (optional cleanup)
client.file_search_stores.delete(name=file_search_store.name, config={'force': True})
print("File Search Store deleted.")
Estas opciones de oficina ayudan a sustentar su entorno organizado. Los datos indexados permanecen almacenados hasta que se eliminan manualmente, mientras que los archivos cargados a través de la API de archivos temporales se eliminan automáticamente posteriormente de 48 horas.
Lea además: 12 cosas que puedes hacer con la API gratuita de Gemini
Precios y límites
La útil de búsqueda de archivos pretende ser sencilla y asequible para todos los desarrolladores. Cada archivo cargado puede tener un tamaño de hasta 100 MB y puedes crear hasta 10 almacenes de búsqueda de archivos por esquema. El nivel tirado permite 1 GB de almacenamiento total en almacenes de búsqueda de archivos, mientras que los niveles superiores permiten 10 GB, 100 GB y 1 TB para los niveles 1, 2 y 3, respectivamente.
La indexación de incrustaciones cuesta 0,15 dólares por cada millón de tokens procesados, pero tanto las incrustaciones de almacenamiento como las consultas de incrustación que indexan datos en tiempo de ejecución son gratuitas. Los tokens de documentos recuperados se facturan como tokens de contexto normales si se utilizan en la procreación. El almacenamiento utiliza aproximadamente 3 veces el tamaño del archivo, ya que las incrustaciones ocupan espacio adicional.
La útil de búsqueda de archivos se creó para tiempos de respuesta de desvaloración latencia y obtendrá consultas de forma rápida y confiable incluso si tiene un gran conjunto de documentos. Esto garantizará una experiencia de respuesta fluida para sus recuperaciones y tareas generativas.
Modelos compatibles
La búsqueda de archivos está acondicionado tanto en el Géminis 2.5 Pro y modelos Gemini 2.5 Flash. Uno y otro admiten la conexión a tierra, el filtrado de metadatos y las citas. Esto significa que puede señalar las secciones precisas de los documentos utilizados para formular respuestas, agregando precisión y comprobación a las respuestas.
Lea además: ¿Cómo conseguir y utilizar la API de Gemini?
Conclusión
La útil de búsqueda de archivos Gemini está diseñada para que RAG sea más comprensible para todos. Se encarga de los aspectos complicados, como la fragmentación, la incrustación y la búsqueda directamente en el interior de la API de Gemini. Los desarrolladores no tienen que crear canales de recuperación por sí mismos ni trabajar con una pulvínulo de datos externa. Posteriormente de favor subido un archivo, todo se realiza automáticamente.
Con almacenamiento tirado, citas integradas y tiempos de respuesta rápidos, File Search lo ayuda a crear sistemas de inteligencia químico sólidos, confiables y con agradecimiento de datos. Alivia a los desarrolladores de la construcción ansiosa y meticulosa para atesorar tiempo y al mismo tiempo sustentar un control firme, precisión e integridad.
Puede comenzar a configurar la búsqueda de archivos ahora en Google AI Studio o desde la API de Gemini. Es una forma en realidad comprensible, rápida y segura de crear aplicaciones sólidamente inteligentes que utilizan datos reales de forma responsable.
Hola, soy Janvi, un apasionado de la ciencia de datos que actualmente trabaja en Analytics Vidhya. Mi delirio al mundo de los datos comenzó con una profunda curiosidad sobre cómo podemos extraer información significativa de conjuntos de datos complejos.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.