
Estamos emocionados de anunciar que vistas materializadas (MV) y mesas de streaming (ST) ahora están disponibles con carácter caudillo en Databricks SQL en AWS y Azure. Las tablas de transmisión ofrecen una ingesta simple e incremental de fuentes como almacenamiento en la aglomeración y buses de mensajes con solo unas pocas líneas de SQL. Las vistas materializadas precalculan y actualizan incrementalmente los resultados de las consultas para que sus paneles y consultas puedan ejecutarse significativamente más rápido que antiguamente. Juntos, le permiten crear canales de datos eficientes y escalables desde la ingesta hasta la transformación utilizando solo SQL.
En este blog, profundizaremos en cómo estas herramientas permiten a los analistas e ingenieros analíticos entregar datos y aplicaciones de prospección de modo más efectiva adentro del almacén DBSQL. Encima, cubriremos nuevas capacidades de MV y ST que mejoran el monitoreo, la resolución de problemas y el seguimiento de costos.
Desafíos que enfrentan los usuarios del almacén de datos
Los almacenes de datos son la ubicación principal para prospección e informes internos a través de aplicaciones de inteligencia empresarial (BI). Los analistas de SQL deben incorporar y modificar de modo competente grandes conjuntos de datos, asegurar un rendimiento rápido de las consultas para prospección en tiempo efectivo y administrar el compensación entre el golpe rápido a los datos y los controles de costos. Se enfrentan a varios desafíos para conquistar estos objetivos:
- Consultas y paneles de control lentos del afortunado final: Los grandes paneles de BI procesan vistas complejas de grandes conjuntos de datos, lo que genera consultas lentas que dificultan la interactividad y aumentan los costos oportuno al reprocesamiento cliché de datos.
- Mejorar la aggiornamento de los datos manteniendo bajos los costos: Los resultados de precómputo pueden compendiar la latencia de las consultas, pero a menudo generan datos obsoletos y costos elevados, lo que requiere un procesamiento incremental arduo para abastecer datos actualizados a un costo regular.
- Hipermercado: Los canales de SQL tradicionales se basan en una codificación manual compleja, lo que ralentiza las respuestas a las evacuación empresariales.
Las vistas materializadas y las tablas de transmisión le brindan datos actualizados y rápidos
Los MV y ST resuelven estos desafíos combinando la facilidad de visualización con la velocidad de los datos precalculados, gracias al poder del procesamiento incremental automotriz de un extremo a otro. Esto permite a los ingenieros realizar consultas rápidas sin indigencia de escribir código arduo, al tiempo que garantiza que los datos estén tan actualizados como lo requiere el negocio.
Consultas rápidas y paneles con MV
Las vistas materializadas (MV) mejoran el rendimiento de los prospección SQL y los paneles de BI al precalcular y juntar los resultados de las consultas por aventajado, lo que reduce significativamente la latencia de las consultas. En lado de consultar repetidamente las tablas pulvínulo, los MV permiten que los paneles y las consultas de los usuarios finales recuperen datos preagregados o preunidos, lo que los hace mucho más rápidos. Encima, consultar MV es más rentable en comparación con las vistas, ya que solo se accede a los datos almacenados en el MV, lo que evita la sobrecarga de reprocesar las tablas pulvínulo subyacentes para cada consulta.
Pase a casos de uso en tiempo efectivo manteniendo los costos bajos
Los ST y MV trabajan juntos para crear canales de datos totalmente incrementales, ideales para casos de uso en tiempo efectivo. Los ST ingieren y procesan continuamente datos en streaming, lo que garantiza que los paneles de BI, los modelos de estudios automotriz y los sistemas operativos siempre tengan la información más actualizada. Los MV, por otro flanco, se actualizan automáticamente de forma incremental a medida que llegan nuevos datos, lo que mantiene los datos actualizados para los usuarios sin indigencia de ingresarlos manualmente y, al mismo tiempo, reduce los costos de procesamiento al evitar reconstrucciones de apariencia completa. La combinación de ST y MV proporciona el mejor compensación costo-rendimiento para prospección e informes en tiempo efectivo.
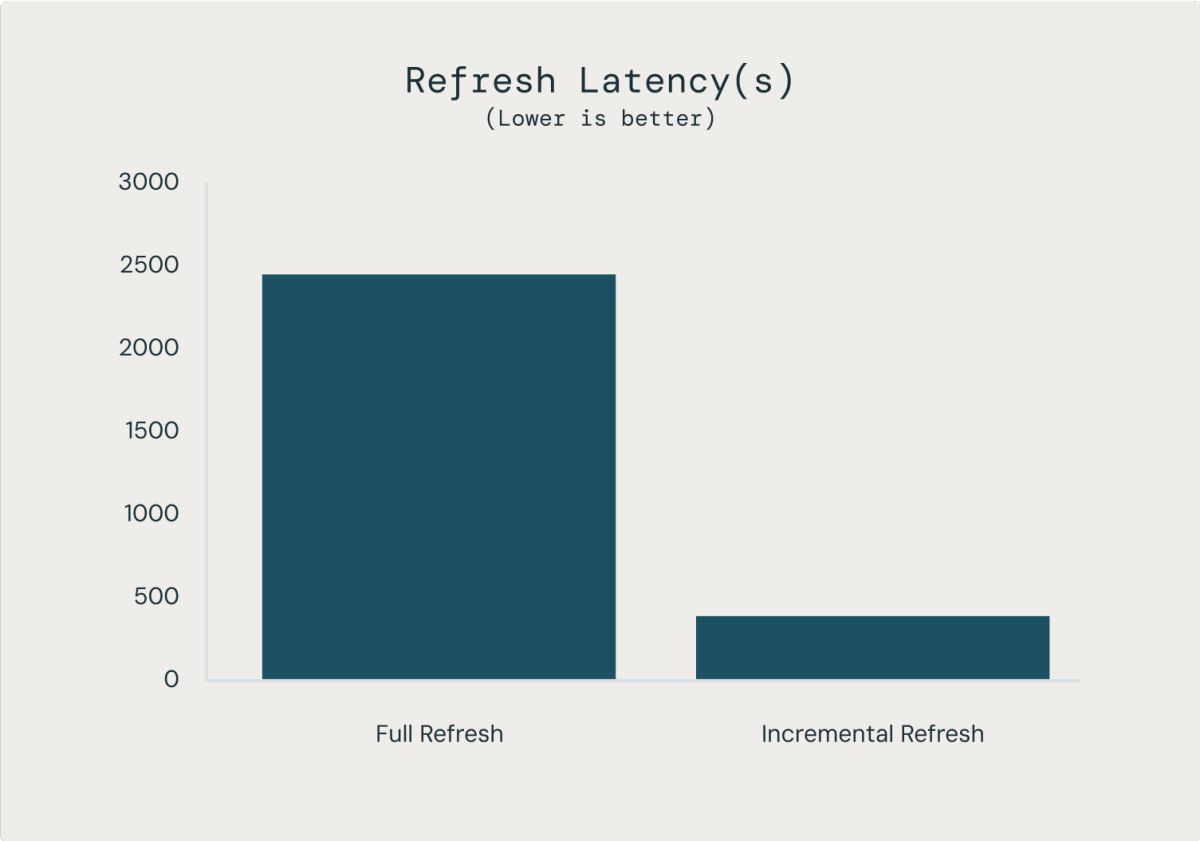
Los MV con aggiornamento incremental todavía pueden economizar mucho tiempo y parné. en nuestro puntos de narración internos en una tabla de 200 mil millones de filas, las actualizaciones de MV fueron un 98 % más baratas y un 85 % más rápidas que poner al día toda la tabla, lo que resultó en una aggiornamento de datos ~7 veces mejor a 1/50 del costo de una afirmación CREATE TABLE AS similar.
Capacite a sus analistas para crear canales de datos en DBSQL
El uso de MV y ST para desarrollar canales de datos automatiza gran parte del trabajo manual involucrado en la dependencia de tablas y código DML, lo que libera a los ingenieros analíticos para que se concentren en la método empresarial y brinden veterano valía a la ordenamiento con una sintaxis SQL simple. Los ST simplifican aún más la ingesta de datos de diversas fuentes, como el almacenamiento en la aglomeración y los buses de mensajes, al eliminar la indigencia de configuraciones complejas.
La utilización eficaz de vistas materializadas sobre las tablas de transacciones ha cedido como resultado una progreso drástica en el rendimiento de las consultas en la capa analítica, con una disminución del tiempo de consulta hasta un 85 % en una tabla de 500 millones de hechos. Esto permite a nuestro equipo empresarial consumir paneles analíticos de modo más competente y tomar decisiones más rápidas basadas en los conocimientos obtenidos de los datos.
— Shiv Nayak / Presidente de edificación de datos e inteligencia fabricado, EasyJet
Hemos corto significativamente el tiempo necesario para manejar grandes volúmenes mediante vistas materializadas de Databricks. Esta progreso ha corto nuestro tiempo de ejecución en un 85 %, lo que permite a nuestro equipo trabajar de modo más competente y centrarse en el estudios automotriz y la inteligencia empresarial. El proceso simplificado admite volúmenes de datos más importantes y contribuye al hucha de costos generales y a una veterano agilidad del plan.
— Sam Adams, ingeniero sénior de estudios automotriz, Paylocity
«La conversión a Vistas Materializadas ha resultado en una progreso drástica en el rendimiento de las consultas… Encima, los ahorros de costos adicionales han ayudado mucho».
— Karthik Venkatesan, director sénior de ingeniería de software de seguridad, Adobe
«Hemos manido que el rendimiento de las consultas progreso en un 98 % con algunas de nuestras tablas que tienen varios terabytes de datos».
— Gal Doron, directora de datos, AnyClip
«La utilización de vistas materializadas sobre las tablas de transacciones ha mejorado drásticamente el rendimiento de las consultas en nuestra capa analítica, y el tiempo de ejecución se ha corto hasta un 85 % en una tabla de 500 millones de hechos».
— Nikita Raje, directora de ingeniería de datos, DigiCert
Ejemplo: ingesta y transformación de datos de un grosor en Databricks
Un caso de uso global para ST y MV es la ingesta y transformación continua de datos a medida que llegan a un depósito de almacenamiento en la aglomeración. El sucesivo ejemplo muestra cómo puede hacer esto completamente en SQL sin indigencia de ninguna configuración u orquestación externa. Crearemos una tabla de transmisión para despachar datos a la casa del charca y luego crearemos una apariencia materializada para contar la cantidad de filas ingeridas.
- Cree ST para ingerir datos de un grosor cada 5 minutos. La tabla de transmisión garantiza la entrega de nuevos datos exactamente una vez. Y oportuno a que los ST utilizan computación en segundo plano sin servidor para el procesamiento de datos, escalarán automáticamente para manejar picos en el grosor de datos.
CREATE OR REFRESH STREAMING TABLE my_bronze
REFRESH EVERY 5 minutes
AS
SELECT count(distinct event_id)
FROM event_count from '/Volumes/bucket_name'- Crea MV para modificar datos cada hora. El MV siempre reflejará los resultados de la consulta con la que está definido y se actualizará incrementalmente cuando sea posible.
CREATE OR REPLACE MATERIALIZED VIEW my_silver
REFRESH EVERY 1 hour
AS
SELECT count(distinct event_id) as event_count from my_bronzeNuevas capacidades
Desde el emanación de la apariencia previa, hemos mejorado el Explorador de catálogos para MV y ST, lo que le permite entrar al estado en tiempo efectivo y a los programas de aggiornamento. Encima, los MV ahora admiten la funcionalidad CREAR O REEMPLAZAR, lo que permite actualizaciones in situ. Los MV todavía ofrecen capacidades de aggiornamento incremental ampliadas en una abanico más amplia de consultas, incluido nuevo soporte para uniones internas, uniones izquierdas, UNION ALL y funciones de ventana. Profundicemos en estas nuevas características:
Observabilidad
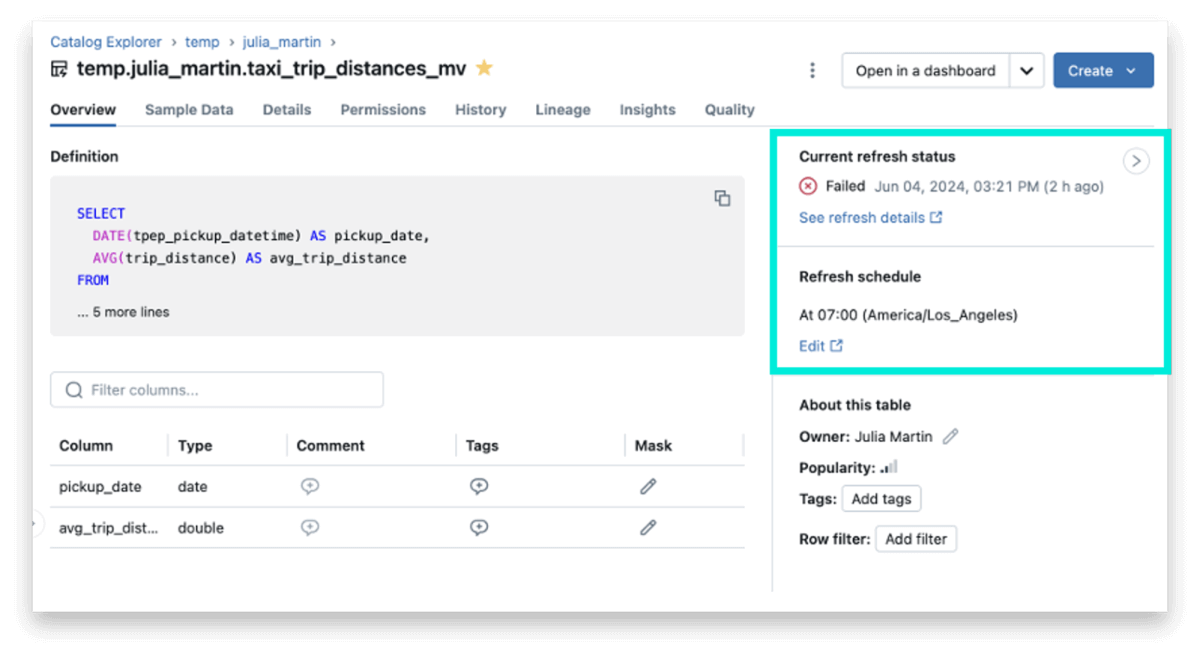
Hemos mejorado el explorador de catálogos con información contextual y en tiempo efectivo sobre el estado y programación de MV y ST.
- Estado de aggiornamento presente: Muestra la hora exacta en la que se actualizó por última vez el MV o ST. Esta es una buena señal de cuán actualizados están los datos.
- Renovar horario: Si su apariencia materializada está configurada para actualizarse automáticamente en un horario basado en el tiempoel explorador del catálogo ahora muestra el cronograma en un formato posible de interpretar. Esto permite a los usuarios finales ver fácilmente la frescura del MV.
Programación y administración más sencillas
Hemos introducido TODAS las sintaxis para programar actualizaciones de MV y ST utilizando DDL. EVERY simplifica la configuración de programaciones basadas en tiempo sin indigencia de escribir la sintaxis CRON. Continuaremos admitiendo la programación CRON para los usuarios que requieran la vehemencia de esa sintaxis.
Ejemplo:
CREATE OR REPLACE MATERIALIZED VIEW | STREAMING TABLE <name>
SCHEDULE EVERY 1 HOUR|DAY|WEEK
AS... Encima, hemos junto soporte para CREAR O REEMPLAZAR para vistas materializadas, lo que permite actualizaciones más fáciles de sus definiciones en el lado sin la indigencia de eliminarlas y retornar a crearlas, al mismo tiempo que se conservan los permisos y las ACL existentes.
Renovar incrementalmente uniones izquierdas, uniones internas y funciones de ventana
Recalcular grandes MV puede resultar costoso y sosegado. Los MV resuelven esto mediante actualizaciones informáticas incrementales, lo que genera menores costos y actualizaciones más rápidas. Esto le brinda una veterano aggiornamento de los datos a una fracción del costo, al tiempo que permite a sus usuarios finales consultar datos precalculados. Los MV se actualizan de forma incremental en DBSQL Pro y almacenes sin servidor, o canalizaciones de Delta Live Tables (DLT).
Los MV se actualizan automáticamente de forma incremental si sus consultas lo admiten. Si una consulta incluye expresiones no admitidas, se realizará una aggiornamento completa. Una aggiornamento incremental procesa solo los cambios desde la última aggiornamento y luego agrega o actualiza los datos en la tabla.
Los MV admiten la aggiornamento incremental para uniones internas, uniones izquierdas, UNION ALL y funciones de ventana (OVER). Puede especificar cualquier cantidad de tablas en la combinación y las actualizaciones de todas las tablas de la combinación se reflejan en los resultados de la consulta. Continuamente agregamos soporte para más tipos de consultas; por merced vea el documentación para las últimas capacidades.
Atribución de costos
Ahora puede ver información de identidad para las actualizaciones en la tabla del sistema de uso facturable. Para obtener esta información, simplemente envíe una consulta a la tabla del sistema de uso facturable para obtener registros donde use_metadata.dlt_pipeline_id esté configurado en el ID de la canalización asociada con la apariencia materializada o la tabla de transmisión. Puede encontrar el ID de la canalización en la pestaña Detalles del Explorador de catálogos al visualizar la apariencia materializada o la tabla de transmisión. Para obtener más información, consulte nuestro documentación.
La sucesivo consulta proporciona un ejemplo:
SELECT sku_name, usage_date, identity_metadata, SUM(usage_quantity) AS `DBUs`
FROM
system.billing.usage
WHERE
usage_metadata.dlt_pipeline_id = <pipeline_id>
GROUP BY ALL Lo que viene para MV y ST
MV y ST son poderosas capacidades de almacenamiento de datos que se basan en lo mejor del almacenamiento de datos en DBSQL. Más de 1400 clientes ya los están utilizando para impulsar la ingesta y aggiornamento incrementales. Igualmente estamos muy entusiasmados con la forma en que mejoraremos aún más los MV y ST en el futuro cercano. Aquí hay una apariencia previa de algunas de esas próximas funciones:
- Renovar según los cambios de datos ascendentes. Podrá configurar actualizaciones automáticas basadas en cambios de datos ascendentes y, al mismo tiempo, podrá dirigir los costos controlando la celeridad con la que se realiza una aggiornamento a posteriori de una aggiornamento.
- Modificar dueño y valer como un director de servicio
- Posibilidad de modificar MV y ST. comentarios directamente en el Explorador de catálogos.
- Monitoreo consolidado MV/ST en la UI. Vea todos sus MV y ST en la interfaz de afortunado de Databricks, para que pueda monitorear fácilmente la información operativa y de estado de todo el espacio de trabajo.
- Seguimiento de costes. El nombre de MV y ST se incluirá en la tabla de sistemas de facturación para que pueda monitorear más fácilmente el uso de DBU, identificar datos y poner al día el historial sin indigencia de inquirir el ID de la tubería.
- Compartir delta: Apto ahora en apariencia previa privada
- Soporte de Google Cloud: ¡Muy pronto!
Comience con MV y ST hoy
Para despuntar hoy: