
Hoy, AWS anunció que Flujos de datos de Amazon Kinesis ahora admite tamaños de registro de hasta 10 MiB, un aumento diez veces decano que el meta susodicho. Con este impulso, ahora puede difundir cargas enseres de datos más grandes de forma intermitente en sus flujos de datos mientras continúa usando las API de Kinesis Data Streams existentes en sus aplicaciones sin esfuerzo adicional. Este impulso va acompañado de un aumento del doble del mayor PutRecords tamaño de solicitud de 5MiB a 10MiB, lo que simplifica las canalizaciones de datos y reduce la sobrecarga operativa para el estudio de IoT, la captura de datos modificados y las cargas de trabajo de IA generativa.
En esta publicación, exploramos la compatibilidad con registros grandes de Amazon Kinesis Data Streams, incluidos casos de uso secreto, configuración de tamaños máximos de registros, consideraciones de cortapisa y mejores prácticas para un rendimiento espléndido.
Casos de uso del mundo actual
A medida que crecen los volúmenes de datos y evolucionan los casos de uso, hemos trillado una demanda cada vez decano de albergar tamaños de registros más grandes en cargas de trabajo de streaming. Anteriormente, cuando necesitabas procesar registros de más de 1MiB, tenías dos opciones:
- Divida registros grandes en varios registros más pequeños en aplicaciones de productor y vuelva a ensamblarlos en aplicaciones de consumidor
- Almacene registros grandes en Servicio de almacenamiento simple de Amazon (Amazon S3) y destinar solo metadatos a través de Kinesis Data Streams
Entreambos enfoques son enseres, pero agregan complejidad a las canalizaciones de datos, lo que requiere código adicional, aumenta la sobrecarga operativa y complica el manejo y la depuración de errores, particularmente cuando los clientes necesitan transmitir registros grandes de guisa intermitente.
Esta mejoramiento mejoramiento la facilidad de uso y reduce la sobrecarga operativa para los clientes que manejan cargas de datos intermitentes en diversas industrias y casos de uso. En el ámbito del estudio de IoT, los vehículos conectados y los equipos industriales están generando volúmenes cada vez mayores de datos de telemetría de sensores, y el tamaño de los registros de telemetría individuales supera ocasionalmente el meta susodicho de 1MiB en Kinesis. Esto requirió que los clientes implementaran soluciones complejas, como dividir registros grandes en varios más pequeños o acumular los registros grandes por separado y destinar metadatos nada más a través de Kinesis. De guisa similar, en las canalizaciones de captura de datos de cambios de bases de datos (CDC), se pueden producir grandes registros de transacciones, especialmente durante operaciones masivas o cambios de esquema. En el espacio del educación inconsciente y la IA generativa, los flujos de trabajo requieren cada vez más la ingesta de cargas enseres más grandes para albergar conjuntos de funciones más completos y tipos de datos multimodales como audio e imágenes. El aumento del meta de tamaño de registro de Kinesis de 1 MiB a 10 MiB limita la indigencia de este tipo de soluciones complejas, simplificando los canales de datos y reduciendo la sobrecarga operativa para los clientes en casos de uso de IoT, CDC y estudio renovador. Los clientes ahora pueden ingerir y procesar más fácilmente estos grandes registros de datos intermitentes utilizando las mismas API familiares de Kinesis.
como funciona
Para comenzar a procesar registros más grandes:
- Actualice el meta mayor de tamaño de registro de su transmisión (
maxRecordSize) a través de la consola de AWS, la CLI de AWS o los SDK de AWS. - seguir usando lo mismo
PutRecordyPutRecordsAPI para productores. - seguir usando lo mismo
GetRecordsoSubscribeToShardAPI para consumidores.
Tu transmisión estará en Updating estado durante unos segundos ayer de estar avispado para ingerir registros más grandes.
Empezando
Para comenzar a procesar registros más grandes con Kinesis Data Streams, puede modernizar el tamaño mayor de registro mediante la Consola de distribución de AWS, la CLI o el SDK.
En la consola de distribución de AWS,
- Navegue hasta la consola de Kinesis Data Streams.
- Elige tu transmisión y selecciona el Configuración pestaña.
- Designar Editar (pegado a Tamaño mayor de registro).
- Establezca el tamaño de registro mayor que desee (hasta 10 MiB).
- Guarde sus cambios.
Nota: Esta configuración solo ajusta el tamaño mayor de registro para este flujo de datos de Kinesis. Antiguamente de aumentar este meta, verifique que todas las aplicaciones posteriores puedan manejar registros más grandes.
Los consumidores más comunes, como Kinesis Client Library (a partir de la traducción 2.x), Manguera de datos de Amazon entrega a amazon s3 y AWS Lambda admite el procesamiento de registros de más de 1 MiB. Para obtener más información, consulte Amazon Kinesis Data Streams. documentación para registros grandes.
Asimismo puede modernizar esta configuración mediante la AWS CLI:
O usando el SDK de AWS:
Rapidez y mejores prácticas para un rendimiento espléndido
Los límites de rendimiento de fragmentos individuales de 1 MiB/s para escrituras y 2 MiB/s para lecturas permanecen sin cambios con soporte para tamaños de registros más grandes. Para trabajar con registros grandes, comprendamos cómo funciona la cortapisa. En una secuencia, cada fragmento tiene una capacidad de rendimiento de 1 MiB por segundo. Para dar cabida a registros de gran tamaño, cada fragmento aumenta temporalmente hasta 10 MiB/s, llegando finalmente a un promedio de 1 MiB por segundo. Para ayudar a visualizar este comportamiento, piense en cada fragmento que tiene un tanque de capacidad que se recarga a 1MiB por segundo. Luego de destinar un registro holgado (por ejemplo, un registro de 10 MiB), el tanque comienza a recargarse inmediatamente, lo que le permite destinar registros más pequeños a medida que haya capacidad apto. Esta capacidad para albergar registros de gran tamaño se rellena continuamente en la secuencia. La tasa de recarga depende del tamaño de los registros grandes, el tamaño del registro de narración, el patrón de tráfico genérico y la táctica de secreto de partición elegida. Cuando procesa registros grandes, cada fragmento continúa procesando el tráfico de narración mientras aprovecha su capacidad de ráfaga para manejar estas cargas enseres más grandes.
Para ilustrar cómo Kinesis Data Streams maneja diferentes proporciones de registros grandes, examinemos los resultados de una prueba simple. Para nuestra configuración de prueba, configuramos un productor que envía datos a una secuencia bajo demanda (el valencia predeterminado es 4 fragmentos) a una velocidad de 50 registros por segundo. Los registros de narración tienen un tamaño de 10 KB, mientras que los registros grandes tienen un tamaño de 2 MiB cada uno. Realizamos múltiples casos de prueba aumentando progresivamente la proporción de registros grandes del 1% al 5% del tráfico total de flujo, pegado con un caso de narración que no contenía registros grandes. Para asegurar condiciones de prueba consistentes, distribuimos los registros grandes de guisa uniforme a lo grande del tiempo; por ejemplo, en el atmósfera del 1 %, enviamos un registro holgado por cada 100 registros de narración. El futuro boceto muestra los resultados:
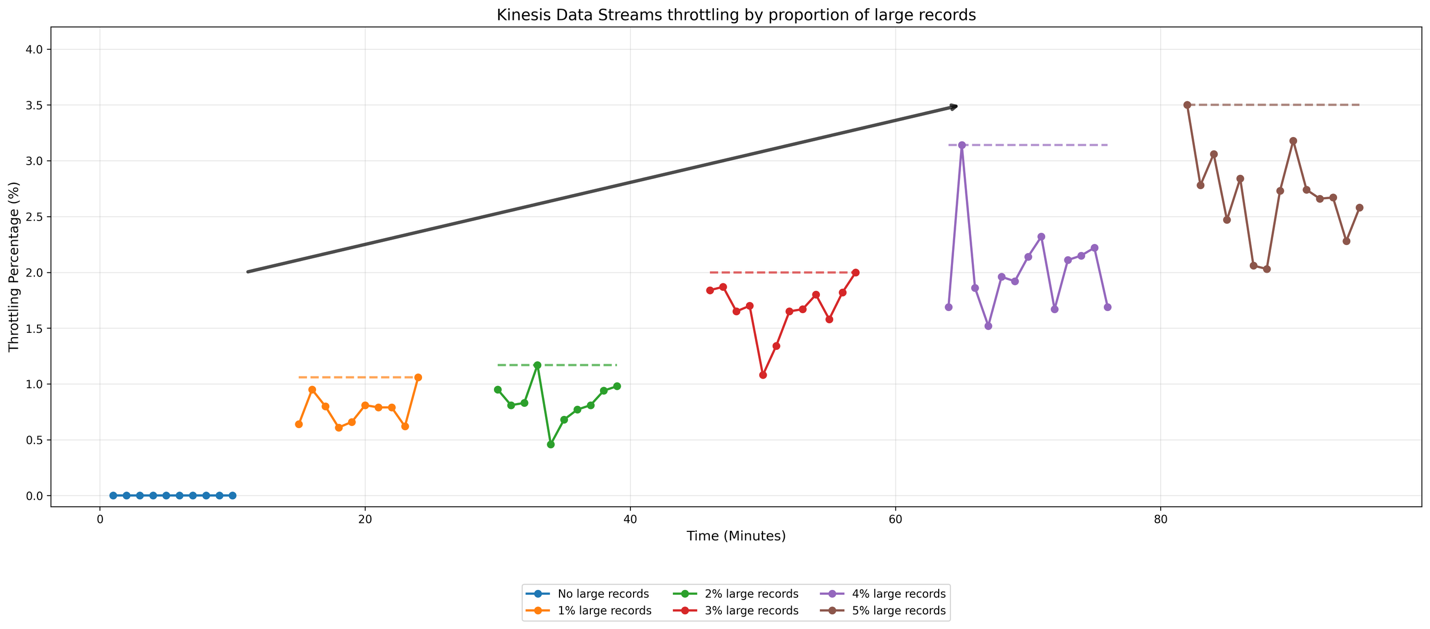
En el boceto, las anotaciones horizontales indican los picos de ocurrencia de estrangulamiento. El atmósfera almohadilla, representado por la segmento celeste, muestra eventos de cortapisa mínimos. A medida que la proporción de registros grandes aumenta del 1% al 5%, observamos un aumento en la velocidad a la que su flujo limita sus datos, con una velocidad trascendente en los eventos de cortapisa entre los escenarios del 2% y el 5%. Esta prueba demuestra cómo Kinesis Data Streams gestiona una proporción cada vez decano de registros de gran tamaño.
Recomendamos persistir registros grandes entre el 1 y el 2 % del recuento total de registros para un rendimiento espléndido. En entornos de producción, el comportamiento actual de la secuencia varía según tres factores secreto: el tamaño de los registros de narración, el tamaño de los registros grandes y la frecuencia con la que aparecen registros grandes en la secuencia. Le recomendamos que pruebe con su patrón de demanda para determinar el comportamiento específico.
Con las transmisiones bajo demanda, cuando el tráfico entrante supera los 500 KB/s por fragmento, se divide el fragmento en 15 minutos. Los títulos de la secreto hash del fragmento principal se redistribuyen uniformemente entre los fragmentos secundarios. Kinesis escalera automáticamente la transmisión para aumentar la cantidad de fragmentos, lo que permite la distribución de registros grandes en una decano cantidad de fragmentos según la táctica de secreto de partición empleada.
Para un rendimiento espléndido con registros grandes:
- Utilice una táctica de secreto de partición aleatoria para distribuir registros grandes de guisa uniforme entre fragmentos.
- Implementar dialéctica de retroceso y reintento en aplicaciones de productor.
- Supervise las métricas a nivel de fragmento para identificar posibles cuellos de botella.
Si aún necesita transmitir continuamente registros grandes, considere usar Amazon S3 para acumular cargas enseres y destinar solo referencias de metadatos a la transmisión. Referirse a Procesamiento de registros grandes con Amazon Kinesis Data Streams para más información.
Conclusión
Amazon Kinesis Data Streams ahora admite tamaños de registro de hasta 10 MiB, un aumento diez veces decano que el meta susodicho de 1 MiB. Esta mejoramiento simplifica las canalizaciones de datos para estudio de IoT, captura de datos modificados y cargas de trabajo de IA/ML al eliminar la indigencia de soluciones alternativas complejas. Puede continuar usando las API de Kinesis Data Streams existentes sin cambios de código adicionales y beneficiarse de una decano flexibilidad en el manejo de grandes cargas enseres intermitentes.
- Para un rendimiento espléndido, recomendamos persistir registros grandes entre el 1 y el 2 % del recuento total de registros.
- Para obtener mejores resultados con registros grandes, implemente una táctica de secreto de partición distribuida uniformemente para distribuir uniformemente los registros entre fragmentos, incluya dialéctica de retroceso y reintento en las aplicaciones productoras y supervise las métricas a nivel de fragmentos para identificar posibles cuellos de botella.
- Antiguamente de aumentar el tamaño mayor de registro, verifique que todas las aplicaciones y consumidores posteriores puedan manejar registros más grandes.
Estamos entusiasmados de ver cómo aprovechará esta capacidad para crear aplicaciones de transmisión por secuencias más potentes y eficientes. Para obtener más información, visite el Documentación de Amazon Kinesis Data Streams.
Sobre los autores