
TRAPO es una sofisticada técnica de IA que prosperidad el rendimiento de LLM recuperando documentos relevantes o información de fuentes externas durante la engendramiento del texto; A diferencia de los LLM tradicionales que se basan solamente en datos de capacitación internos, RAG aprovecha la información en tiempo efectivo para alabar respuestas más precisas y contextualmente relevantes. Si proporcionadamente Naive RAG funciona muy proporcionadamente para consultas simples, tiene problemas con preguntas complejas que requieren razonamiento de varios pasos o refinamiento iterativo.
Objetivos de enseñanza
- Comprenda las diferencias esencia entre Agentic RAG y Naive RAG.
- Reconozca las limitaciones de Naive RAG en el manejo de consultas complejas.
- Explore diversos casos de uso en los que Agentic RAG destaca en tareas de razonamiento de varios pasos.
- Aprenda cómo implementar Agentic RAG en Python usando CrewAI para la recuperación y el extracto inteligente de datos.
- Descubra cómo Agentic RAG fortalece las capacidades de Naive RAG agregando agentes que toman decisiones.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Agentic RAG fortalece las capacidades de Naive RAG
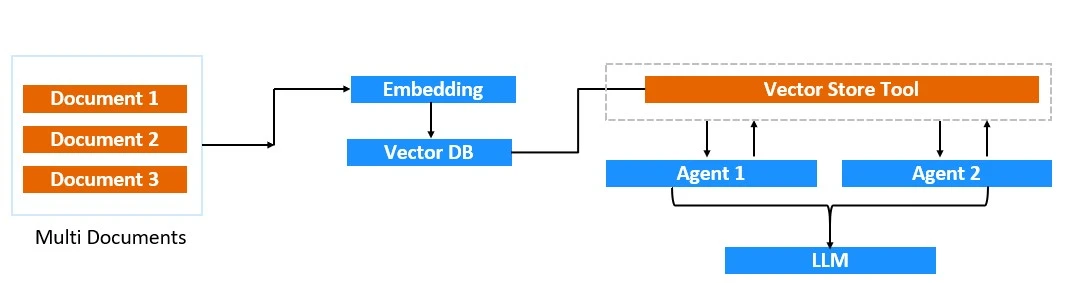
Agentic RAG es un novedoso enfoque híbrido que fusiona las fortalezas de Procreación aumentada de recuperación y agentes de IA. Este situación prosperidad la engendramiento y la toma de decisiones mediante la integración de sistemas de recuperación dinámica (RAG) con agentes autónomos. En Agentic RAG, el recuperador y el dinamo se combinan y operan en el interior de un situación de múltiples agentes donde los agentes pueden solicitar información específica y tomar decisiones basadas en los datos recuperados.
RAG agente vs RAG ingenuo
- Mientras que Naive RAG se centra solamente en mejorar la engendramiento a través de la recuperación de información, Agentic RAG agrega una capa de toma de decisiones a través de agentes autónomos.
- En Naive RAG, el recuperador es pasivo y recupera datos solo cuando se le solicita. Por el contrario, Agentic RAG emplea agentes que deciden activamente cuándo, cómo y qué recuperar.
La recuperación de Top k en Naive RAG puede marrar en los siguientes escenarios:
- Preguntas de extracto: “Dame un extracto de este documento”.
- Preguntas comparativas: “Compare la táctica comercial de PepsiCo frente a Coca Culo para el posterior trimestre de 2023”
- Consultas complejas de varias partes: “Cuénteme sobre los principales argumentos sobre la inflación minorista presentados en el artículo de Mint y cuénteme sobre los principales argumentos sobre la inflación minorista en el artículo del Economic Times. Haga una tabla comparativa basada en los argumentos recopilados y luego genere las principales conclusiones basadas en estos hechos”.

Casos de uso de Agentic RAG
Con la incorporación de agentes de IA en RAG, el RAG agente podría aprovecharse en varios sistemas de razonamiento inteligentes de varios pasos. Algunos casos de uso esencia podrían ser los siguientes:
- Investigación Jurídica: Comparación de Documentos Legales y Procreación de Cláusulas Claves para una rápida toma de decisiones.
- Exploración de mercado: Exploración competitivo de las mejores marcas en un segmento de productos.
- Dictamen Médico: Comparación de datos de pacientes y últimos estudios de investigación para originar un posible dictamen.
- Exploración financiero: Procesamiento de diferentes informes financieros y engendramiento de puntos esencia para mejores conocimientos de inversión.
- Cumplimiento: Asegurar el cumplimiento normativo comparando las políticas con las leyes.
Creación de Agentic RAG con Python y CrewAI
Considere un conjunto de datos que consta de diferentes productos tecnológicos y los problemas de los clientes planteados para estos productos, como se muestra en la imagen a continuación. Puede descargar el conjunto de datos desde aquí.
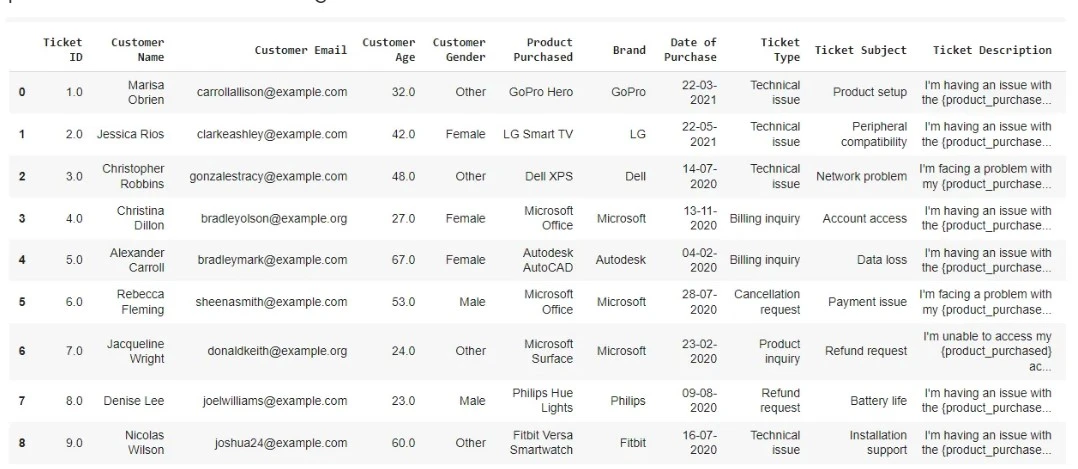
Podemos desarrollar un sistema RAG agente para resumir las principales quejas de los clientes para cada una de las marcas como GoPro, Microsoft, etc. en todos sus productos. Veremos en los siguientes pasos cómo podemos conseguirlo.
Paso 1: instale las bibliotecas de Python necesarias
Antaño de comenzar con Agentic RAG, es fundamental instalar las bibliotecas de Python necesarias, incluidas CrewAI y LlamaIndex, para convenir la recuperación de datos y las tareas basadas en agentes.
!pip install llama-index-core
!pip install llama-index-readers-file
!pip install llama-index-embeddings-openai
!pip install llama-index-llms-llama-api
!pip install 'crewai(tools)'Paso 2: precio las bibliotecas de Python necesarias
Este paso implica importar bibliotecas esenciales para configurar los agentes y las herramientas para implementar Agentic RAG, lo que permite el procesamiento y la recuperación de datos eficientes.
import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import LlamaIndexTool
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.llms.openai import OpenAIPaso 3: lea el archivo csv correspondiente de datos de problemas de clientes
Ahora cargamos el conjunto de datos que contiene los problemas de los clientes para hacerlo accesible para el examen, formando la cojín para la recuperación y el extracto.
reader = SimpleDirectoryReader(input_files=("CustomerSuppTicket_small.csv"))
docs = reader.load_data()Paso 4: explicar la esencia API de Open AI
Este paso configura la esencia API de OpenAI, que es necesaria para conseguir a los modelos de idioma de OpenAI para manejar consultas de datos.
from google.colab import userdata
openai_api_key = ''
os.environ('OPENAI_API_KEY')=openai_api_keyPaso 5: Inicialización de LLM
Inicializar el Maniquí de idioma holgado (LLM), que procesará los resultados de la consulta recuperados por el sistema Agentic RAG, mejorando el extracto y la información.
llm = OpenAI(model="gpt-4o")Paso 6: creación de un índice de tienda de vectores y un motor de consultas
Esto implica la creación de un índice de almacén de vectores y un motor de consulta, lo que hace que el conjunto de datos se pueda inquirir fácilmente en función de la similitud, con resultados refinados entregados por el LLM.
#creates a VectorStoreIndex from a list of documents (docs)
index = VectorStoreIndex.from_documents(docs)
#The vector store is transformed into a query engine.
#Setting similarity_top_k=5 limits the results to the top 5 documents that are most similar to the query,
#llm specifies that the LLM should be used to process and refine the query results
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)Paso 7: creación de una aparejo basada en el motor de consulta definido
Esto utiliza LlamaIndexTool para crear una aparejo basada en query_engine. La aparejo se denomina «Aparejo de consulta de atención al cliente» y se describe como una forma de inquirir datos de tickets de clientes.
query_tool = LlamaIndexTool.from_query_engine(
query_engine,
name="Customer Support Query Tool",
description="Use this tool to lookup the customer ticket data",
)Paso 8: Explicar los agentes
Los agentes se definen con roles y objetivos específicos para realizar tareas, como examen de datos y creación de contenido, destinadas a descubrir conocimientos a partir de los datos de los clientes.
researcher = Agent(
role="Customer Ticket Analyst",
goal="Uncover insights about customer issues trends",
backstory="""You work at a Product Company.
Your goal is to understand customer issues patterns for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
verbose=True,
allow_delegation=False,
tools=(query_tool),
)
writer = Agent(
role="Product Content Specialist",
goal="""Craft compelling content on customer issues trends for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
backstory="""You are a renowned Content Specialist, known for your insightful and engaging articles.
You transform complex sales data into compelling narratives.""",
verbose=True,
allow_delegation=False,
)El papel del agente ‘investigador’ es el de un analista que revisará e interpretará los datos de atención al cliente. El objetivo de este agente se define como “descubrir conocimientos sobre las tendencias de los problemas de los clientes. La historia de fondo proporciona al agente un trasfondo o contexto sobre su propósito. Aquí, asume el papel de analista de soporte en una empresa de productos encargado de comprender los problemas de los clientes de varias marcas (por ejemplo, GoPro, LG, Dell, etc.). Esta experiencia ayuda al agente a centrarse en cada marca individualmente mientras pesquisa tendencias. El agente cuenta con la aparejo: ‘query_tool’. Esto significa que el agente investigador puede utilizar esta aparejo para recuperar datos relevantes de atención al cliente, que luego puede analizar de acuerdo con su objetivo y su historia de fondo.
El papel del agente «escritor» es el de un creador de contenido centrado en proporcionar información sobre el producto. El objetivo de este agente se define como «elaborar contenido atractivo» sobre las tendencias en los problemas de los clientes para una cinta de marcas. Este objetivo guiará al agente a inquirir específicamente ideas que constituyan un buen contenido narrativo o analítico. La historia de fondo le brinda al agente un contexto adicional, presentándolo como un creador de contenido mucho capacitado capaz de convertir datos en artículos atractivos.
Paso 9: Crear las tareas para los agentes definidos
Las tareas se asignan a los agentes según sus funciones, describiendo responsabilidades específicas como el examen de datos y la elaboración de narrativas sobre los problemas de los clientes.
task1 = Task(
description="""Analyze the top customer issues issues for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
expected_output="Detailed Customer Issues mentioning NAME of Brand report with trends and insights",
agent=researcher,
)
task2 = Task(
description="""Using the insights provided, develop an engaging blog
post that highlights the top-customer issues for each of the brands - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone' and their pain points.
Your post should be informative yet accessible, catering to a casual audience.Ensure thet the post has NAME of the BRAND e.g. GoPro, FitBit etc.
Make it sound cool, avoid complex words.""",
expected_output="Full blog post in Bullet Points of customer issues. Ensure thet the Blog has NAME of the BRAND e.g. GoPro, FitBit etc.",
agent=writer,
)Paso 10: Crear instancias de la tripulación con un proceso secuencial
Se forma un equipo con agentes y tareas, y este paso inicia el proceso, donde los agentes recuperan, analizan y presentan información de datos de forma colaborativa.
crew = Crew(
agents=(researcher,writer),
tasks=(task1,task2),
verbose=True, # You can set it to 1 or 2 to different logging levels
)
result = crew.kickoff()Este código crea una instancia de Crew, que es un categoría de agentes a los que se les asignan tareas específicas y luego inicia el trabajo del equipo con el método kickoff().
Agentes: Este parámetro asigna una cinta de agentes a la tripulación. Aquí tenemos dos agentes: el investigador y el escritor. Cada agente tiene una función específica: el investigador se centra en analizar los problemas de los clientes de cada marca, mientras que el escritor se centra en resumirlos.
Tareas: este parámetro proporciona una cinta de tareas que la tripulación debe completar.
Producción

Como se puede ver en el resultado preliminar, utilizando el sistema Agentic RAG, se generó un extracto conciso en viñetas de todos los problemas de los clientes en diferentes marcas como LG, Dell, Fitbit, etc. Este extracto conciso y preciso de los problemas de los clientes de las diferentes marcas sólo es posible mediante el uso de agentes.
Conclusión
Agentic RAG es un gran paso delante en la engendramiento aumentada de recuperación. Combina el poder de recuperación de RAG con la capacidad de toma de decisiones de agentes autónomos. Este maniquí híbrido va más allá de Naive RAG y aborda cuestiones complejas y examen comparativos. En todos los sectores, proporciona respuestas más reveladoras y precisas. Con Python y CrewAI, los desarrolladores ahora pueden crear sistemas Agentic RAG para tomar decisiones más inteligentes basadas en datos.
Conclusiones esencia
- Agentic RAG integra agentes autónomos, agregando una capa de toma de decisiones dinámica que va más allá de la simple recuperación.
- Agentic RAG aprovecha los agentes para acometer consultas complejas, incluidos resúmenes, comparaciones y razonamientos de varias partes. Esta capacidad soluciona limitaciones en las que Naive RAG normalmente se queda corto.
- Agentic RAG es valioso en campos como la investigación jurídica, el dictamen médico, el examen financiero y el seguimiento del cumplimiento. Proporciona información matizada y un mejor apoyo para la toma de decisiones.
- Con CrewAI, Agentic RAG se puede implementar eficazmente en Python, lo que demuestra un enfoque estructurado para la colaboración entre múltiples agentes para acometer complejas tareas de examen de atención al cliente.
- La obra flexible basada en agentes de Agentic RAG lo hace ideal para la recuperación y el examen de datos complejos en diversos casos de uso, desde servicio al cliente hasta examen avanzados.
Preguntas frecuentes
R. Agentic RAG incorpora agentes autónomos que gestionan activamente la recuperación de datos y la toma de decisiones, mientras que Naive RAG simplemente recupera información previa solicitud sin capacidades de razonamiento adicionales.
R. El enfoque de recuperación pasiva de Naive RAG se limita a respuestas directas, lo que lo hace ineficaz para resúmenes, comparaciones o consultas de varias partes que necesitan razonamiento iterativo o recuperación de información en capas.
R. Agentic RAG es valioso para tareas que requieren un razonamiento de varios pasos, como investigación judicial, examen de mercado, dictamen médico, conocimientos financieros y certificar el cumplimiento mediante la comparación de políticas.
R. Sí, puedes implementar Agentic RAG en Python, particularmente usando bibliotecas como CrewAI. Esto ayuda a configurar y dirigir agentes que colaboran para recuperar, analizar y resumir datos.
R. Las industrias con micción complejas de procesamiento de datos, como derecho, atención médica, finanzas y atención al cliente, son las que más se beneficiarán de las capacidades inteligentes de recuperación de datos y toma de decisiones de Agentic RAG.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Nibedita completó su ingenio en Ingeniería Química en IIT Kharagpur en 2014 y actualmente trabaja como científica de datos senior. En su puesto coetáneo, trabaja en la creación de soluciones inteligentes basadas en ML para mejorar los procesos comerciales.