
Nos complace compartir las últimas características nuevas y mejoras de rendimiento que hacen que Databricks SQL sea más simple, más rápido y más financiero que nunca. Con más de 7000 clientes que utilizan Databricks SQL como su almacén de datos en la ahora, este se ha convertido en el producto de más rápido crecimiento en nuestra historia.
El mejor almacén de datos es un laguna
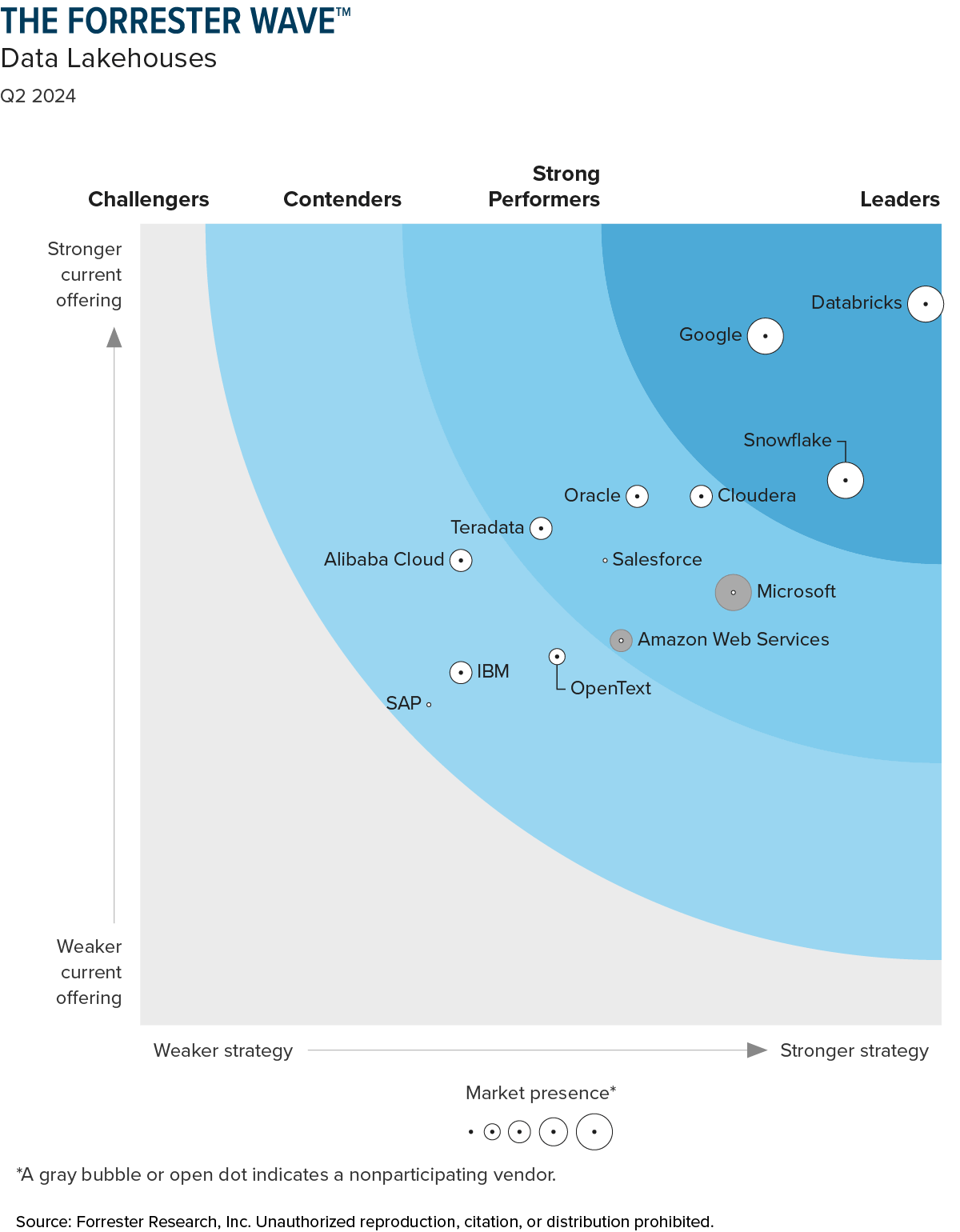
Databricks SQL se pedestal en construcción de la casa del lagunaFuimos pioneros en este enfoque en principios de 2020 y lanzamos Databricks SQL (DBSQL) como parte de la plataforma de inteligencia de datos de Databricks. Predijimos que los almacenes de datos independientes y separados se convertirían en sistemas heredados correcto a sus altos costos y su naturaleza propietaria, y hoy vemos evidencia sólida de que esto es cierto: Noticia de MIT Technology Insights muestra que el 74% de las empresas ya han adoptivo la construcción de la casa laguna. Las numerosas plataformas de datos basadas en casas laguna disponibles para estas empresas fueron analizadas recientemente en el Forrester Wave para lagos de datosque reconoció a Databricks como líder con los puntajes más altos en las categorías de ofrecimiento presente y logística en comparación con todos los demás.
En nuestras conversaciones con los clientes, la delantera de Lakehouse proviene de dos cosas: el último costo total y una plataforma unificada para IA y BI. Lakehouse permite usar una copia de los datos, en un formato libre, para todas sus cargas de trabajo de IA y BI. Eso elimina la duplicación y replicación de datos necesarias para suministrar los datos sincronizados entre múltiples plataformas, lo que reduce drásticamente el costo y simplifica la construcción.
Rendimiento impulsado por IA: alivio 4 veces
El año pasado, declaramos que el enfoque clásico del rendimiento del sistema, basado en heurísticas y optimizadores de costos, era amañado la viejo parte del tiempo. Si proporcionadamente esas técnicas eran las mejores disponibles, la era presente de la IA ha permitido un enfoque completamente nuevo. Hoy, utilizamos una nueva gestación de sistemas de IA en todas las capas de nuestra plataforma que han llevado las mejoras del rendimiento del sistema a un nuevo nivel. Estos sistemas de IA analizan sus cargas de trabajo y mejoran la eficiencia y el rendimiento. automáticamente.
- Concentración de líquidosahora Georgiaadministra el diseño de sus datos, eligiendo automáticamente la secreto de concentración y brindando la flexibilidad para redefinir las claves de concentración sin tener que reescribir los datos. Esto permite que el diseño de sus datos evolucione cercano con las deyección analíticas a lo liberal del tiempo y reemplaza la partición de tablas y ZORDER, por lo que ya no tendrá que ajustar el diseño de sus datos.
- E/S predictivaincluso conocida como «indexación sin índices», le brinda el rendimiento de los índices, pero sin requerir la creación o el mantenimiento de los índices. Gracias a los avances en los sistemas de IA de Mosaic, ahora podemos ejecutar modelos y vectores de características de entrada con parámetros de un orden de magnitud viejo sin ningún aumento trascendental en la latencia de predicción. Esto permite que la E/S predictiva admita un conjunto mucho más amplio de cargas de trabajo.
- Papeleo inteligente de la carga de trabajo Utiliza modelos de educación necesario para optimizar los capital de los almacenes de SQL sin servidor para ofrecer un mejor soporte a la adhesión concurrencia. Esto es consumado para cargas de trabajo de BI a escalera cuando una gran cantidad de analistas y consultas están agobiando el almacén de datos. La encargo inteligente de cargas de trabajo garantiza que estas cargas de trabajo tengan la cantidad adecuada de capital rápidamente.
- Optimización predictivaahora Georgiamaneja automáticamente las operaciones de mantenimiento típicas de las tablas que ayudan a optimizar el rendimiento. Databricks identificará las tablas que se beneficiarían de las operaciones de mantenimiento, como la agrupación en clústeres, los ajustes del tamaño de los archivos y la honradez de archivos, y simplemente las ejecutará por usted, sin aprieto de tareas manuales.
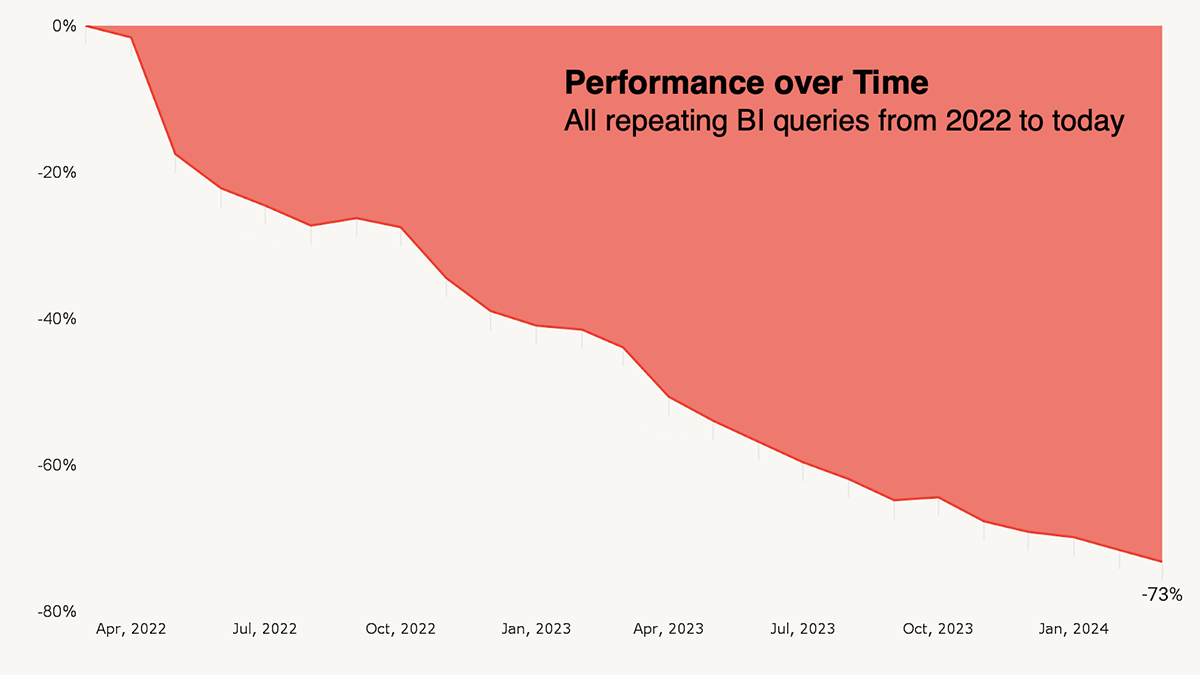
Estos son solo algunos de nuestros sistemas de inteligencia industrial integrados y lo mejor es que no es necesario conocer los detalles de cómo funcionan: la atractivo simplemente sucede automáticamente. Dada la cantidad de tiempo que dedicamos a esta dominio, es ajustado asegurar que estamos obsesionados con el rendimiento y, con el tiempo, podemos ver la diferencia que ha generado. Cuando analizamos las cargas de trabajo repetidas para nuestros clientes, el rendimiento de las mismas consultas de BI ha mejorado en un 73 % desde hace dos abriles. ¡Esto es 4 veces más rápido!
Asistente de inteligencia industrial para analistas de SQL
Asimismo hemos incorporado IA a nuestra experiencia de usufructuario, lo que hace que Databricks SQL sea más realizable de usar y más productivo para los analistas de SQL. El Asistente de IA de Databricks, ahora generalmente adecuadoes un sistema integrado que tiene en cuenta el contexto. Asistente de IA que ayuda a los analistas de SQL a crear, editar y depurar SQL. Este asistente se pedestal en el mismo motor de inteligencia de datos de nuestra plataforma, por lo que comprende el contexto único de su negocio. El asistente ha sido adoptivo rápidamente en Databricks correcto a lo proporcionadamente que puede redactar consultas o corregir errores para los analistas de SQL, lo que ahorra innumerables horas de tiempo y aumenta la productividad.
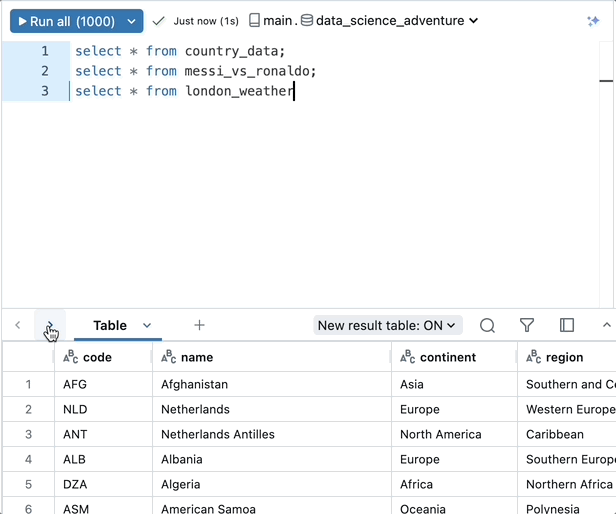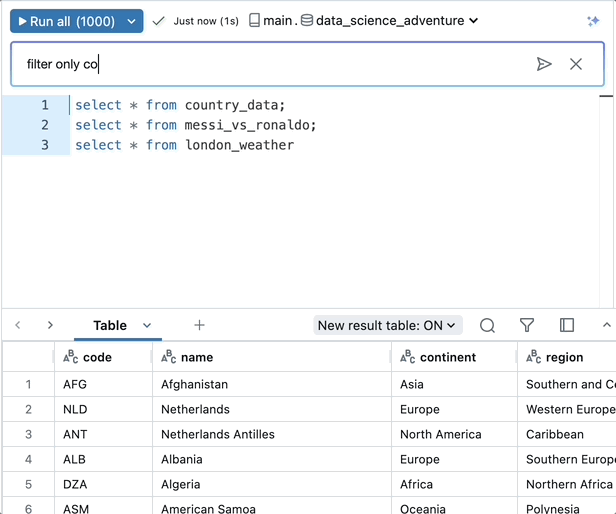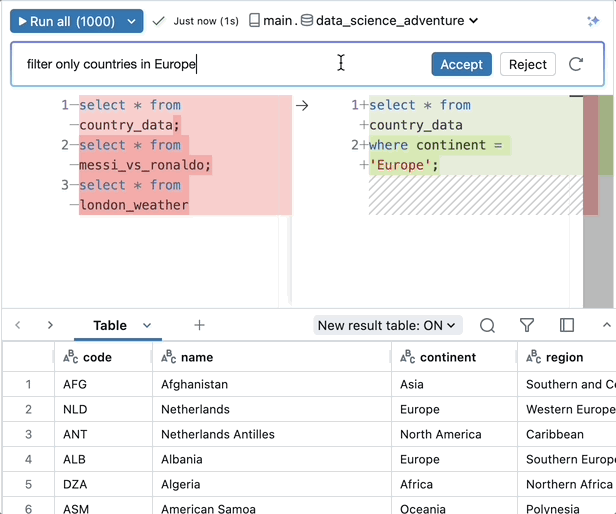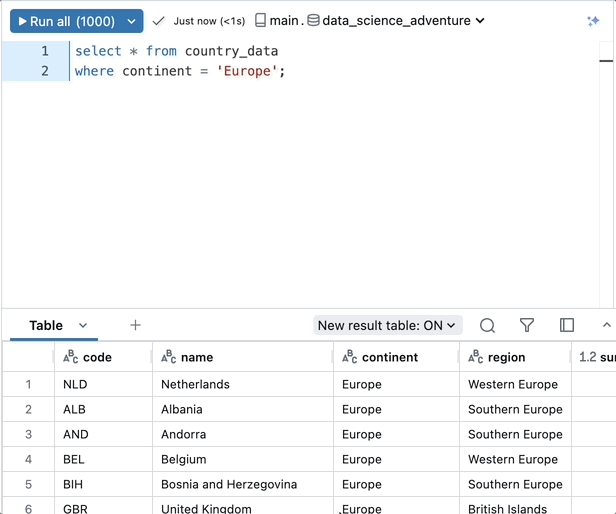
Aproveche los modelos de IA directamente a través de SQL
Con el auge de los modelos GenAI y ML, no sorprende que los analistas de SQL quieran obtener cada vez más a esos modelos de IA directamente adentro de SQL. Primero presentamos Funciones de IA en Databricks SQL el año pasado Exactamente por esa razón y hemos gastado una rápida admisión desde entonces. Funciones de IA Ahora están en interpretación preliminar pública y hemos junto nuevas funciones, como la búsqueda de vectores. AI Functions elimina las complejidades técnicas del uso de LLM, lo que permite a los analistas y científicos de datos utilizar estos modelos sin esfuerzo, sin aprieto de preocuparse por la infraestructura subyacente.
- La función ai_query() le permite consultar cualquier maniquí de IA desde SQL. Estos pueden ser modelos GenAI o modelos Classic ML. Incluso puede usar modelos LLM externos
SELECT sku_id, product_name, ai_query( "llama3-8B-instruct", "You are a marketing expert for a winter holiday promotion targeting GenZ. Generate a promotional text in 30 words mentioning a 50% discount for product: " || product_name ) FROM uc_catalog.schema.retail_products WHERE inventory > 2 * forecasted_sales - Funciones LLM integradas
Asimismo hay 9 nuevas funciones GenAI que le permiten analizar texto no estructurado con el poder de los LLM. Por ejemplo:Extraer información importante del texto que está presente en una columna de una tabla:
SELECT ai_extract( 'John Doe lives in New York and works for Acme Corp.', array('person', 'location', 'organization'))Clasifique los comentarios de revisión de un producto según el contenido:
SELECT review_comments, ai_classify(description, ARRAY('clothing', 'shoes', 'accessories', 'furniture')) AS category FROM ProductsVer las 9 funciones aquí
- Búsqueda de vectores: la nueva función de búsqueda de vectores le permite realizar búsquedas KNN y permite usar RAG de forma sencilla y serie para usar. Esta función utiliza Databricks Búsqueda de vectores producto. Al combinar las capacidades de búsqueda de vectores y las capacidades de AI_query, los analistas de SQL ahora pueden ejecutar fácilmente descomposición complejos. Por ejemplo, ahora se pueden agenciárselas todos los tweets
SELECT Tweet FROM vector_search( index => “main.default.ai_tweets_2024_idx”, query => “retail”, num_results => 10 ) - AI_Forecast: Una nueva previsión de series temporales función incorporada para que pueda pronosticar métricas (por ejemplo, ingresos) rápidamente a través de SQL sin aprieto de crear un maniquí ML personalizado.
SELECT * FROM ai_forecast( TABLE(historical_revenue_table), horizon => '2016-03-31', time_col => 'ds', value_col => 'revenue' )
AI/BI: un nuevo tipo de producto de inteligencia empresarial (BI)
Con el objetivo de democratizar verdaderamente los conocimientos obtenidos a partir de los datos, incluso presentó Databricks AI/BIun producto de inteligencia empresarial que aprovecha la IA generativa para comprender en profundidad la semántica de los datos y permitir el descomposición de datos por cuenta propia para todos en su estructura. sistema de IA compuestoAI/BI aprovecha los conocimientos de todo su patrimonio de datos, incluidos los metadatos de Unity Catalog, las consultas SQL de los pipelines ETL y más. Cuenta con dos componentes principales: AI/BI Dashboards, una ofrecimiento de BI de código bajo para crear rápidamente visualizaciones de datos y paneles, y Genie, una interfaz conversacional para sus datos que aprende continuamente de los comentarios de los usuarios para contestar una amplia tono de preguntas comerciales del mundo vivo sin alucinaciones. Estas innovaciones mejoran significativamente el descomposición de hipermercado adentro de Databricks SQL, lo que permite una tono más amplia de usuarios no técnicos al tiempo que garantiza una gobernanza unificada, seguimiento de género, uso compartido seguro y stop rendimiento a través de la integración con su plataforma de inteligencia de datos.
Almacenamiento de datos completo de extremo a extremo con Databricks SQL
Adicionalmente de las nuevas funciones de IA, incluso hemos enérgico una serie de funciones básicas de SQL Warehouse. Miles de clientes han migrado sus almacenes de datos heredados a DBSQL. Para que esas migraciones sean posibles, nos aseguramos de que DBSQL tuviera todas las funciones necesarias para proporcionar las mismas funciones de almacenamiento de datos en el servidor de almacenamiento:
- Vistas materializadas:Asegure la puesta al día de los datos mediante el uso MV para potenciar sus paneles de controlLas vistas materializadas se actualizan automáticamente cuando las tablas subyacentes tienen datos nuevos en empleo de cuando se consultan.
- Utilice restricciones PK/FK Para optimizar el rendimiento de las consultas. Al utilizar RELY, las consultas se pueden acelerar eliminando automáticamente las uniones redundantes y las agregaciones distintas.
- Modificación es un nuevo tipo de datos para procesar datos semiestructurados que ofrece un aumento significativo del rendimiento en comparación con el almacenamiento de datos como cadenas JSON, al mismo tiempo que proporciona la flexibilidad para soportar esquemas en gran medida anidados y en cambio.
- Apodo de columnas laterales Simplificar la escritura de SQL al poder hacer relato a una expresión reutilizada especificada anteriormente en la misma consulta. Esto puede ayudar a simplificar las consultas al estrechar las CTE o subconsultas innecesarias.
- Características como Variables SQL, Argumentos nombrados & UDF de Python Asimismo están facilitando la creación de scripts en Databricks SQL directamente.
No lo olvides, todo esto funciona con una gran inteligencia industrial. Editor de SQL y incorporado aparejo de panel de control.
Adicionalmente, gracias a nuestros excelentes socios, incluso contamos con un ecosistema rico, libre e integrado de sus herramientas de inteligencia industrial y datos favoritas, como Power BI, Tableau y dbt. Es casi seguro que las herramientas que esté utilizando hoy ya funcionan con DBSQL.
Obtenga más información y comience a utilizar Databricks SQL
Para obtener más información sobre las últimas novedades en almacenamiento de datos y Databricks SQL, consulte Discurso inaugural sobre el almacén de datos de Data + AI Summit cercano con las numerosas sesiones de la Pista de almacenamiento de datos, descomposición y BI.
Si desea portar su almacén existente a un almacén de datos sin servidor y de stop rendimiento con una excelente experiencia de usufructuario y un costo total más bajo, entonces Databricks SQL es la alternativa. Pruébalo de forma gratuita.