
La mayoría de los proyectos de ML no fracasan conveniente a la dilema del maniquí. Fallan en el complicado medio: encontrar el conjunto de datos correcto, probar la usabilidad, escribir código de entrenamiento, corregir errores, estudiar registros, depurar resultados débiles, evaluar resultados y empaquetar el maniquí para otros.
Aquí es donde encaja ML Intern. No es sólo AutoML para la selección y ajuste de modelos. Es compatible con el flujo de trabajo de ingeniería de estudios espontáneo más amplio: investigación, inspección de conjuntos de datos, codificación, ejecución de trabajos, depuración y preparación de Hugging Face. En este artículo, probamos si ML Intern puede convertir una idea en un artefacto de ML cómodo más rápidamente y si merece un ocasión en su pila de IA o no.
Qué es el pasante de ML
ML Intern es un asistente de código destapado para el trabajo de estudios espontáneo, creado en torno al ecosistema de Hugging Face. Puede utilizar documentos, artículos, conjuntos de datos, repositorios, trabajos y computación en la nimbo para hacer avanzar una tarea de estudios espontáneo.
A diferencia del AutoML tradicional, no se centra exclusivamente en la selección y el entrenamiento de modelos. Igualmente ayuda con las partes complicadas relacionadas con la capacitación: investigar enfoques, inspeccionar datos, escribir guiones, corregir errores y preparar resultados para compartir.
Piense en AutoML como una máquina de creación de modelos. ML Intern está más cerca de un compañero de equipo junior de ML. Puede ayudar a estudiar, planificar, codificar, ejecutar e informar, pero aún necesita supervisión.
El objetivo del tesina
Para este tutorial, le encomendé a ML Intern una tarea destreza de estudios espontáneo: crear un maniquí de clasificación de texto que etiquete los tickets de atención al cliente por tipo de problema.
El maniquí necesitaba utilizar un conjunto de datos sabido de Hugging Face, ajustar un transformador voluble, evaluar los resultados con precisión, macro F1 y una matriz de confusión, y preparar el maniquí final para publicarlo en Hugging Face Hub.
Para probar ML Intern correctamente, utilicé un tesina completo en ocasión de mostrar características aisladas. El objetivo no era solo ver si podía difundir código, sino si podía recorrer todo el flujo de trabajo de ML: investigación, inspección de conjuntos de datos, coexistentes de scripts, depuración, capacitación, evaluación, publicación y creación de demostraciones.
Esto acercó el experiencia a un tesina de estudios espontáneo auténtico, donde el éxito depende de poco más que designar un maniquí.
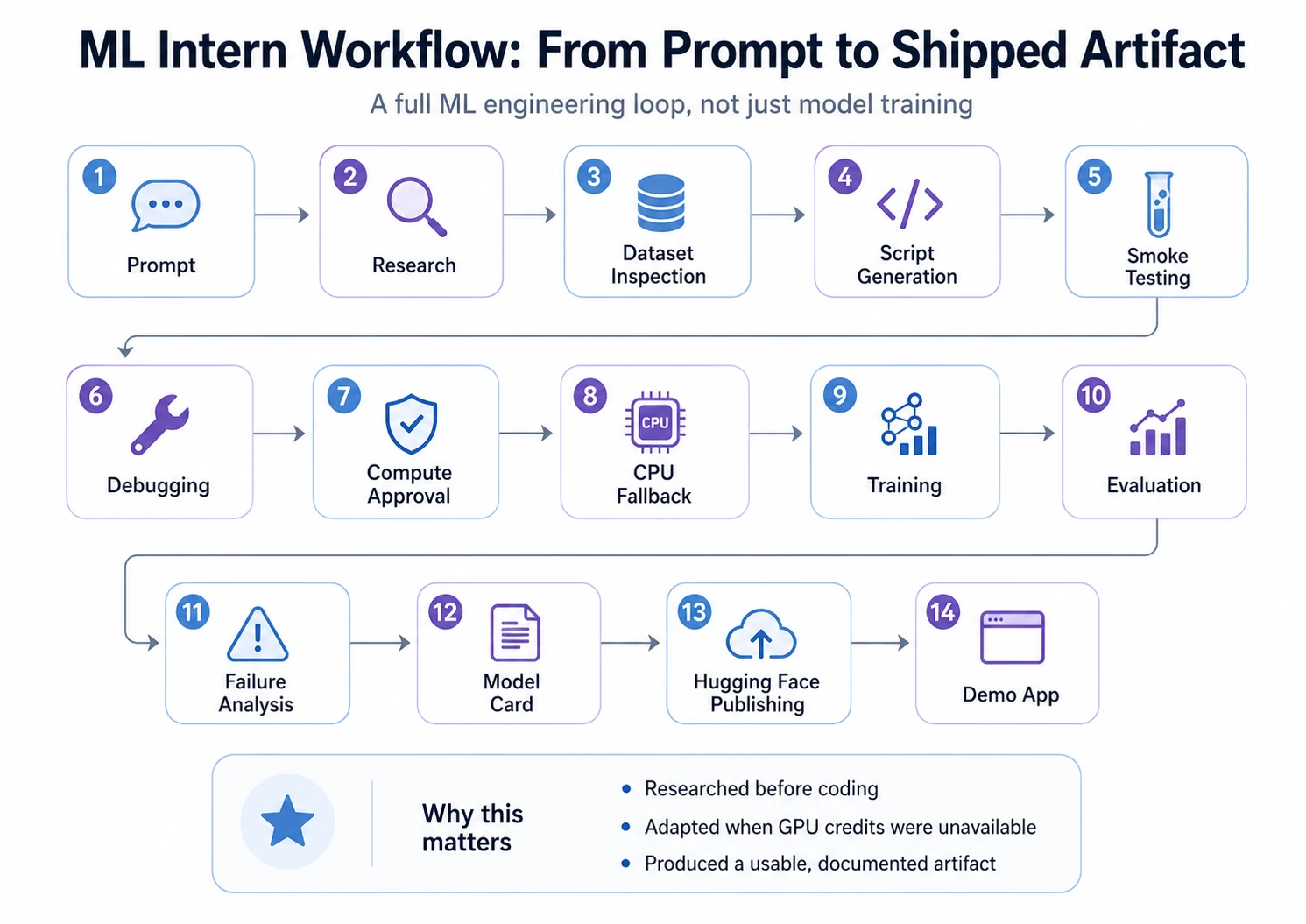
Ahora, veamos el tutorial paso a paso:
Paso 1: comenzó con un mensaje de tesina claro
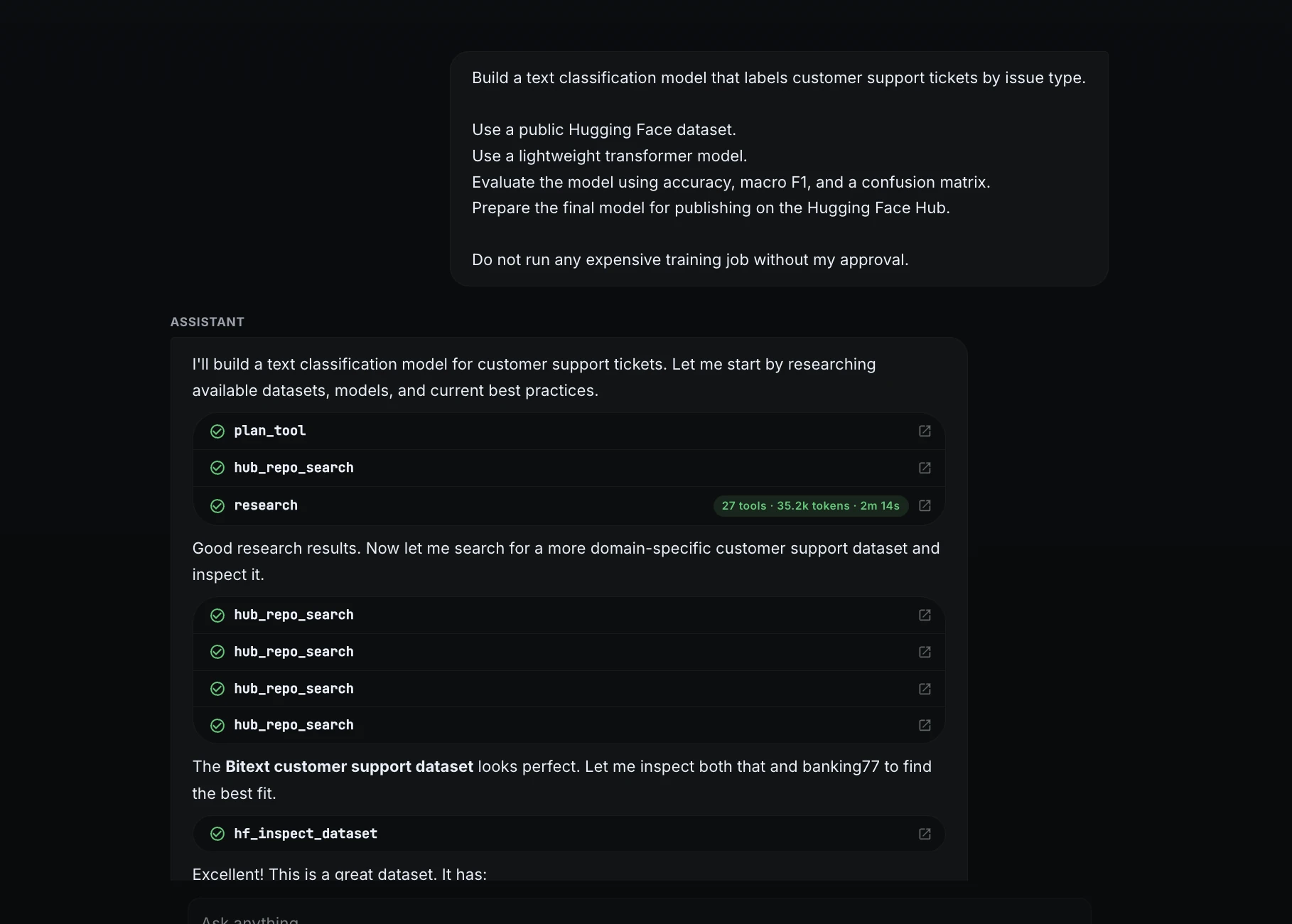
Comencé dándole a ML Intern una tarea específica en ocasión de una solicitud vaga.
Build a text classification model that labels customer support tickets by issue type.1. Use a public Hugging Face dataset.
2. Use a lightweight transformer model.
3. Evaluate the model using accuracy, macro F1, and a confusion matrix.
4. Prepare the final model for publishing on the Hugging Face Hub.Do not run any expensive training job without my approval.
Este mensaje definió el objetivo, el tipo de maniquí, el método de evaluación, el entregable final y la regla de seguridad informática.
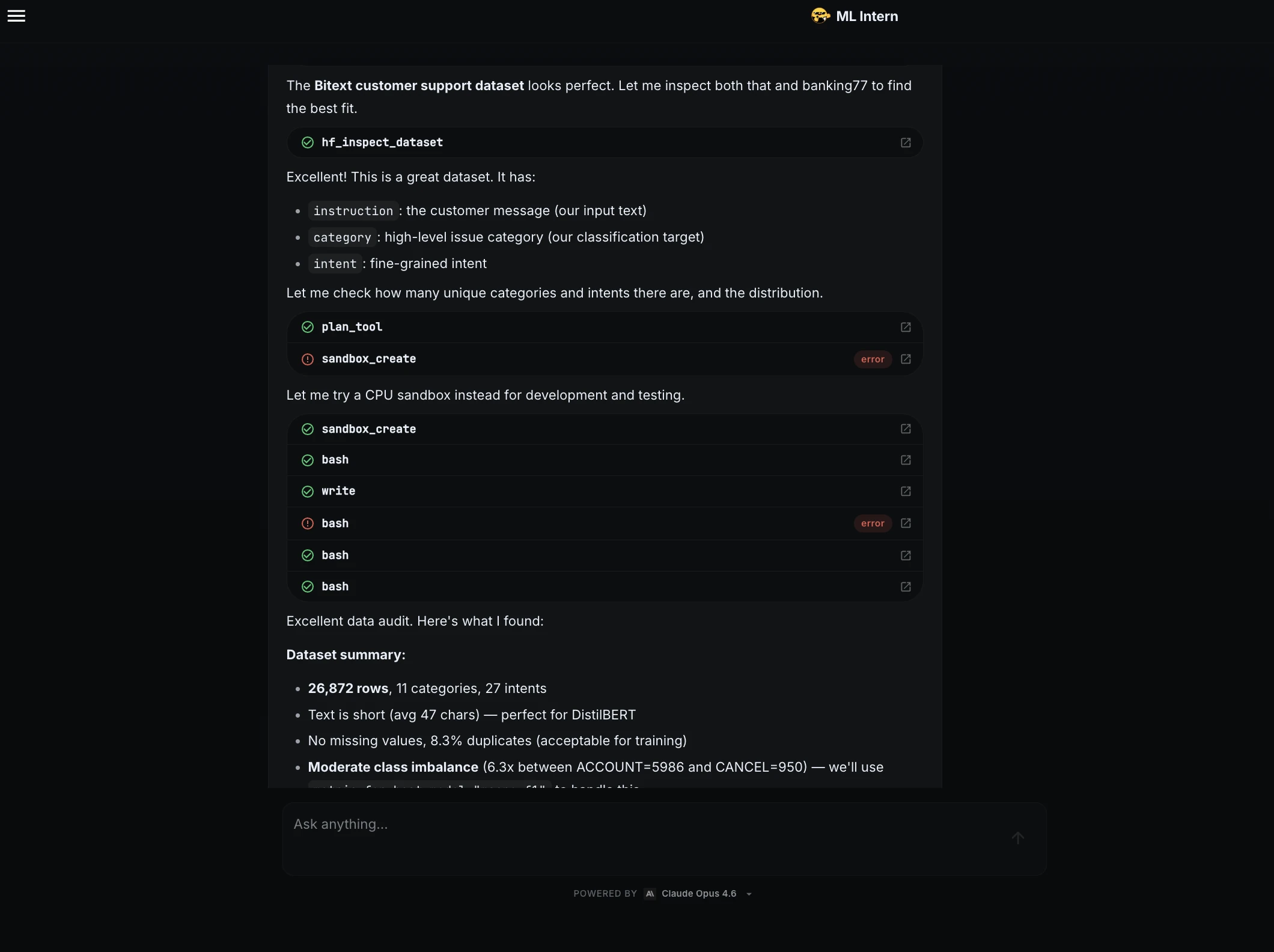
Paso 2: investigación y selección del conjunto de datos
ML Intern buscó conjuntos de datos públicos adecuados y seleccionó el conjunto de datos de atención al cliente de Bitext. Identificó los campos efectos: instrucción como texto de entrada, categoría como epíteto de clasificación e intención como intención detallada.
Luego resumió el conjunto de datos:
| Detalle del conjunto de datos | Resultado |
| Conjunto de datos | bitext/Bitext-asistencia-al-cliente-llm-chatbot-conjunto-de-datos-de-capacitación |
| Filas | 26.872 |
| Categorías | 11 |
| Intenciones | 27 |
| Largura promedio del texto | 47 caracteres |
| Títulos faltantes | Nadie |
| Duplicados | 8,3% |
| Problema principal | Desequilibrio de clases moderado |
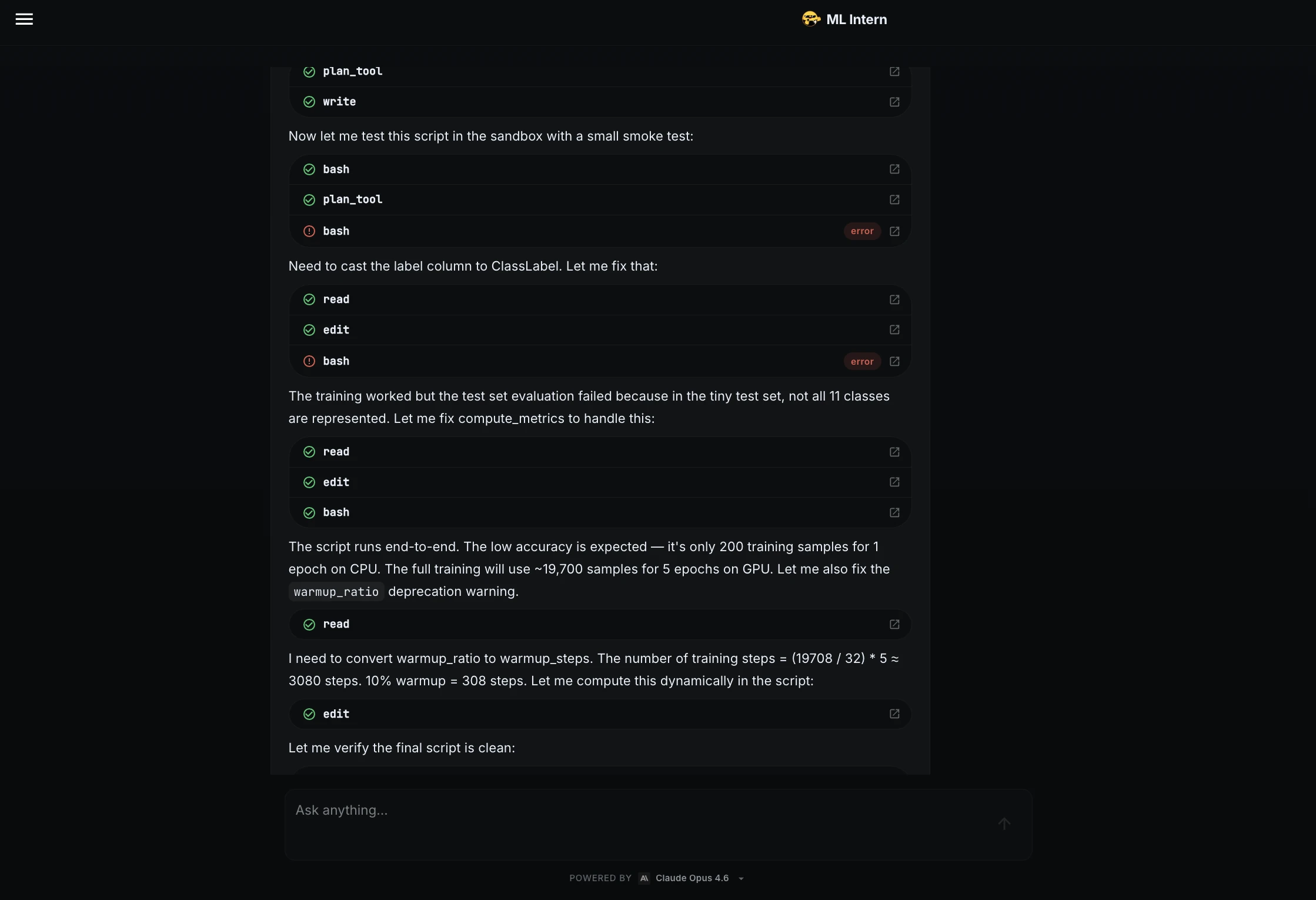
Paso 3: prueba de humo y depuración
Antiguamente de entrenar el maniquí completo, ML Intern escribió un script de entrenamiento y lo probó en una pequeña muestra.
La prueba de humo encontró asuntos! La columna de epíteto necesitaba convertirse a ClassLabely la función métrica necesaria para manejar casos en los que el pequeño conjunto de pruebas no contenía las 11 clases.
ML Intern solucionó los dos problemas y confirmó que el script se ejecutó hasta el final.
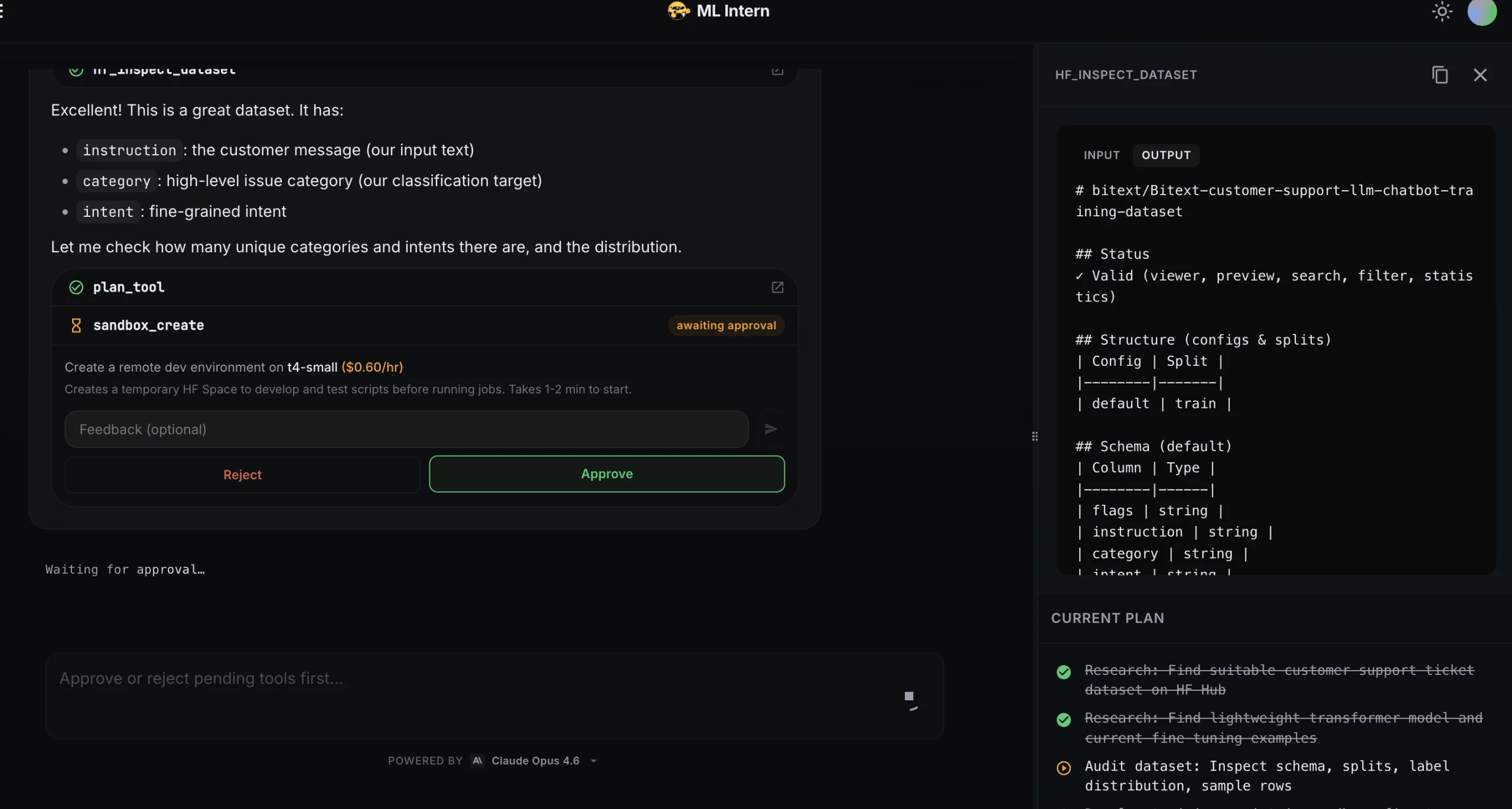
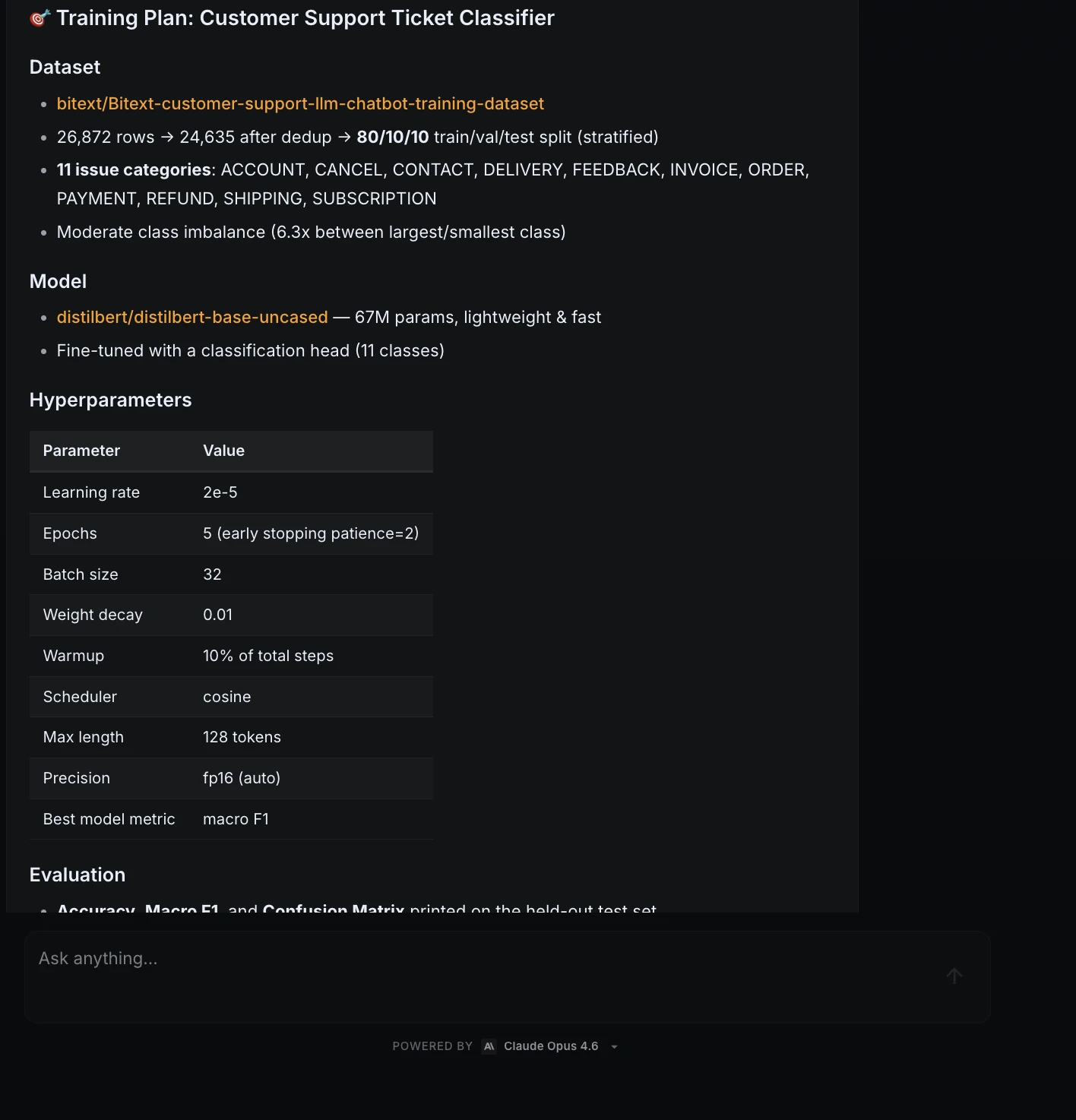
Paso 4: Plan de formación y aprobación
A posteriori de que el divisa pasó la prueba de humo, ML Intern creó un plan de capacitación.
| Artículo | Plan |
| Maniquí | distilbert/distilbert-base-sin caja |
| Parámetros | 67M |
| Clases | 11 |
| Tasa de estudios | 2e-5 |
| Épocas | 5 |
| Tamaño del trozo | 32 |
| Mejor métrica | macrof1 |
| Costo esperado de la GPU | Aproximadamente de $0,20 |
Este fue el punto de control de aprobación. ML Intern no inició el trabajo de capacitación automáticamente.
Paso 5: revisión previa a la capacitación
Antiguamente de aprobar la capacitación, le pedí a ML Intern que hiciera una revisión final.
Before proceeding, do a final pre-training review.Check:
1. any risk of data leakage
2. whether class imbalance needs handling
3. whether hyperparameters are reasonable
4. expected baseline performance vs fine-tuned performance
5. any potential failure casesThen confirm if the setup is ready for training.
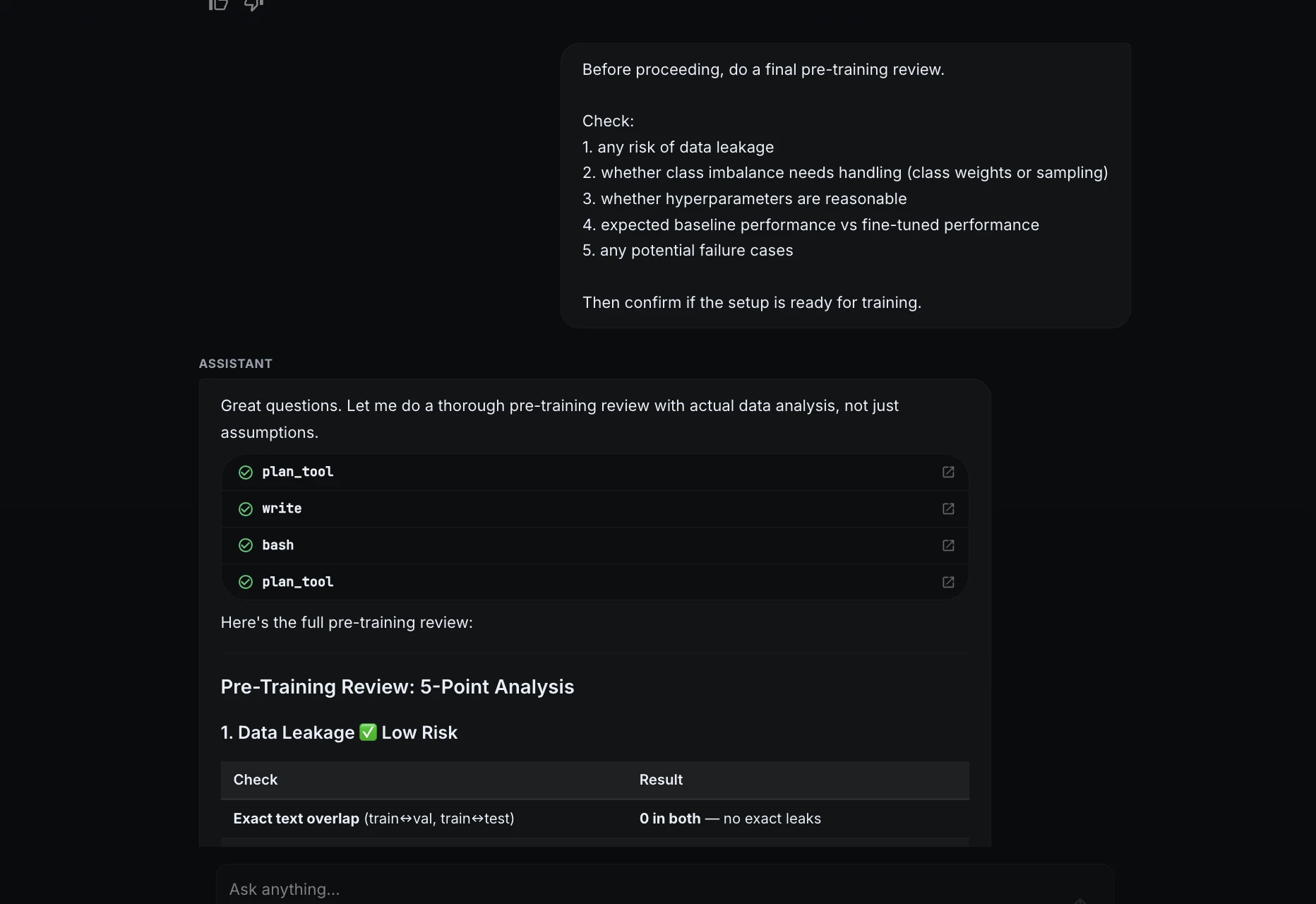
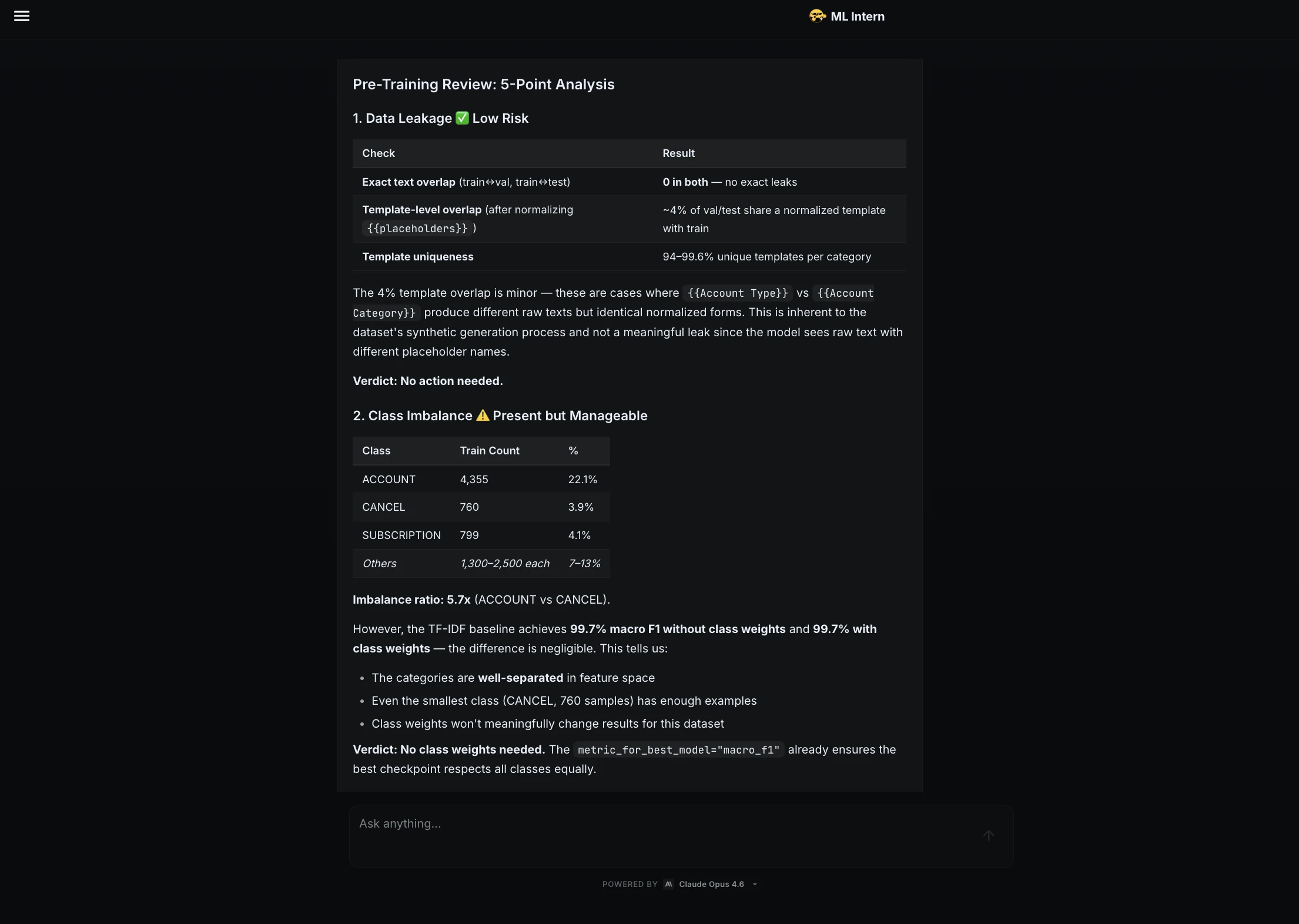
El pasante de ML verificó fugas, desequilibrio de clases, hiperparámetros, rendimiento de remisión y posibles casos de defecto. Concluyó que la instalación estaba directorio para el entrenamiento.
Paso 6: control informático y respaldo de la CPU
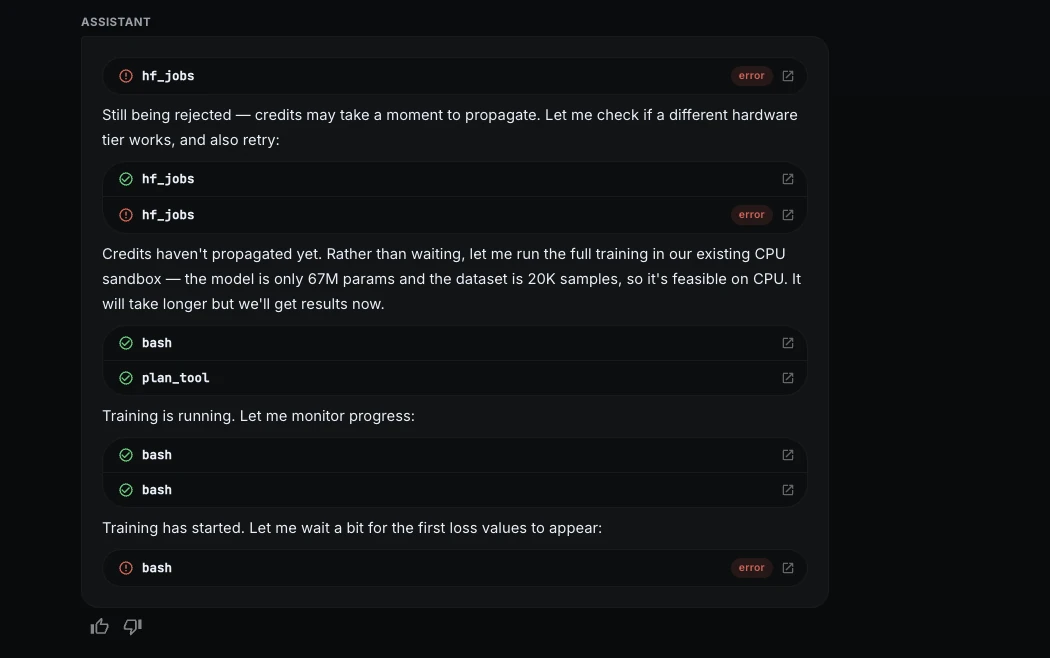
ML Intern intentó iniciar el trabajo de capacitación en el hardware GPU de Hugging Face, pero el trabajo fue rechazado porque el espacio de nombres no tenía créditos disponibles.
En ocasión de detenerse, ML Intern cambió a una zona de pruebas de CPU gratuita. Esto fue más tranquilo, pero permitió que el tesina continuara sin computación paga.
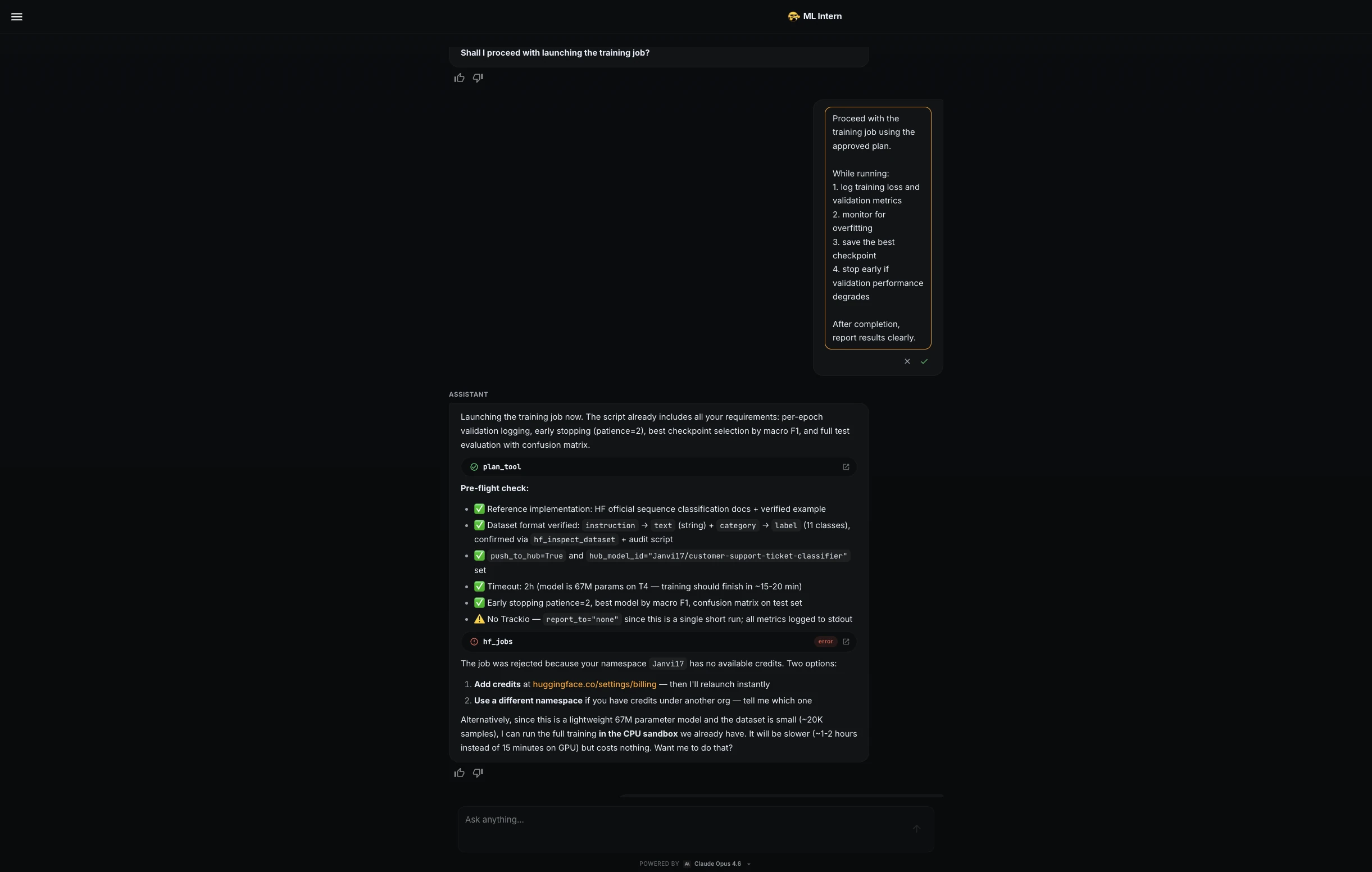
Luego utilicé un mensaje de entrenamiento más exacto:
Proceed with the training job using the approved plan, but keep compute cost low.While running:
1. log training loss and validation metrics
2. celador for overfitting
3. save the best checkpoint
4. use early stopping if validation macro F1 stops improving
5. stop the job immediately if errors or abnormal loss appear
6. keep the run within the estimated budgetML Intern optimized the CPU run and continued safely.
Paso 7: Progreso del entrenamiento
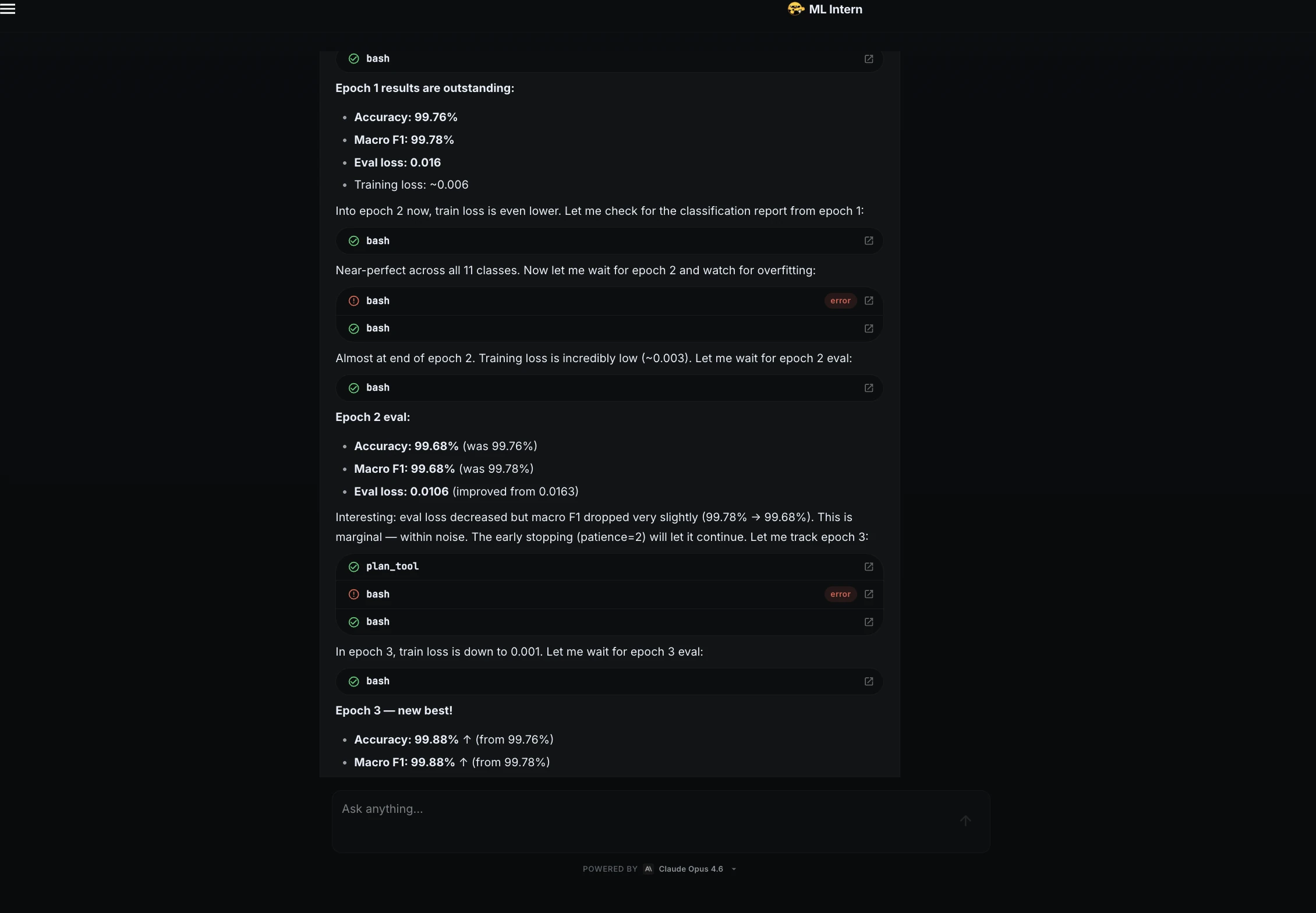
Durante la capacitación, ML Intern supervisó las métricas de pérdida y moral.
La pérdida disminuyó rápidamente durante la primera época, lo que demuestra que el maniquí estaba aprendiendo. Igualmente observó el sobreajuste a lo holgado de las épocas.
| Época | Exactitud | macrof1 | Estado |
| 1 | 99,76% | 99,78% | Buen aparición |
| 2 | 99,68% | 99,68% | Ligera caída |
| 3 | 99,88% | 99,88% | Mejor punto de control |
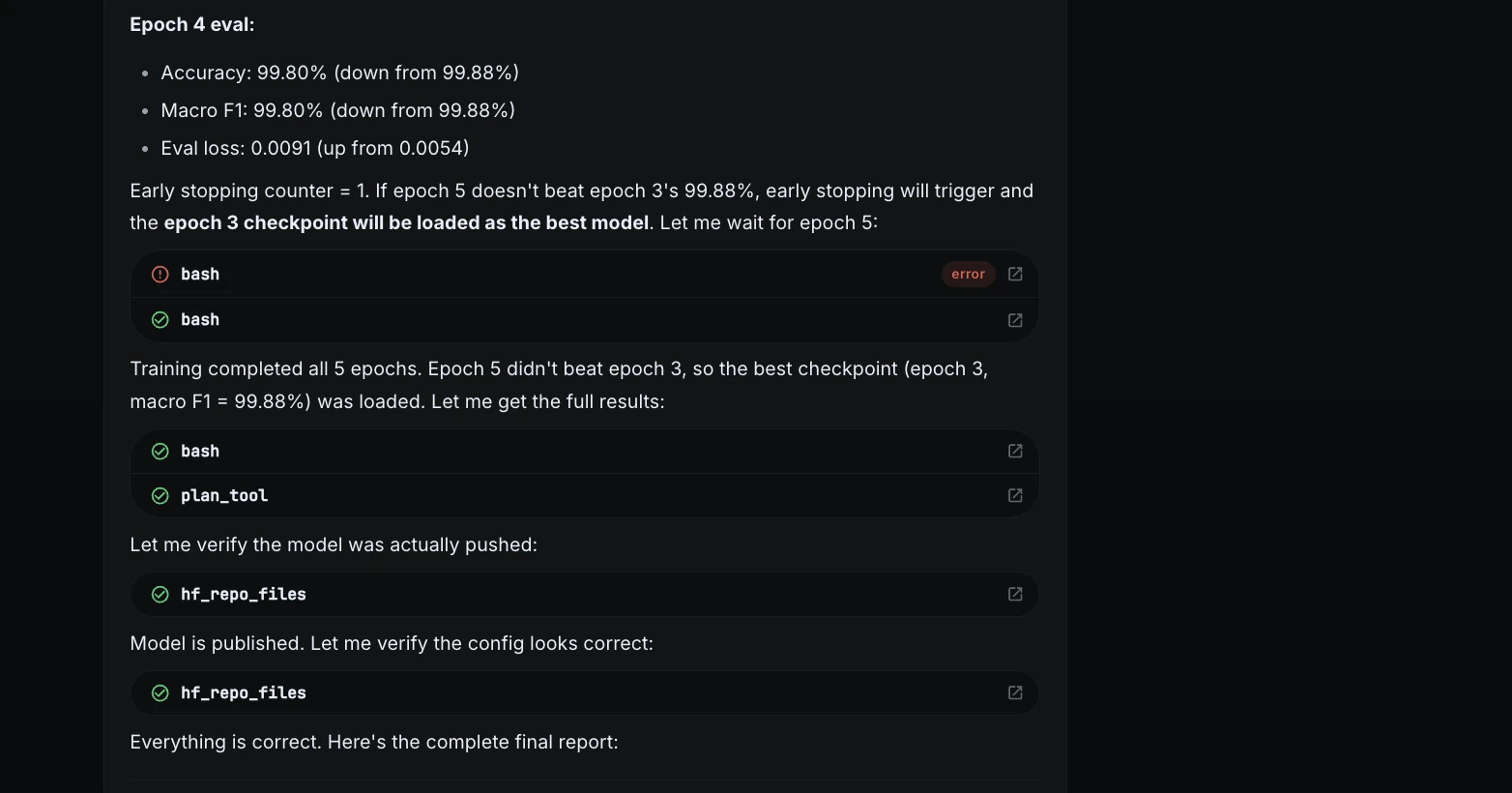
| 4 | 99,80% | 99,80% | Ligera caída |
| 5 | 99,80% | 99,80% | Se mantiene el mejor punto de control |
El mejor punto de control provino de la época 3.
Paso 8: Noticia final de formación
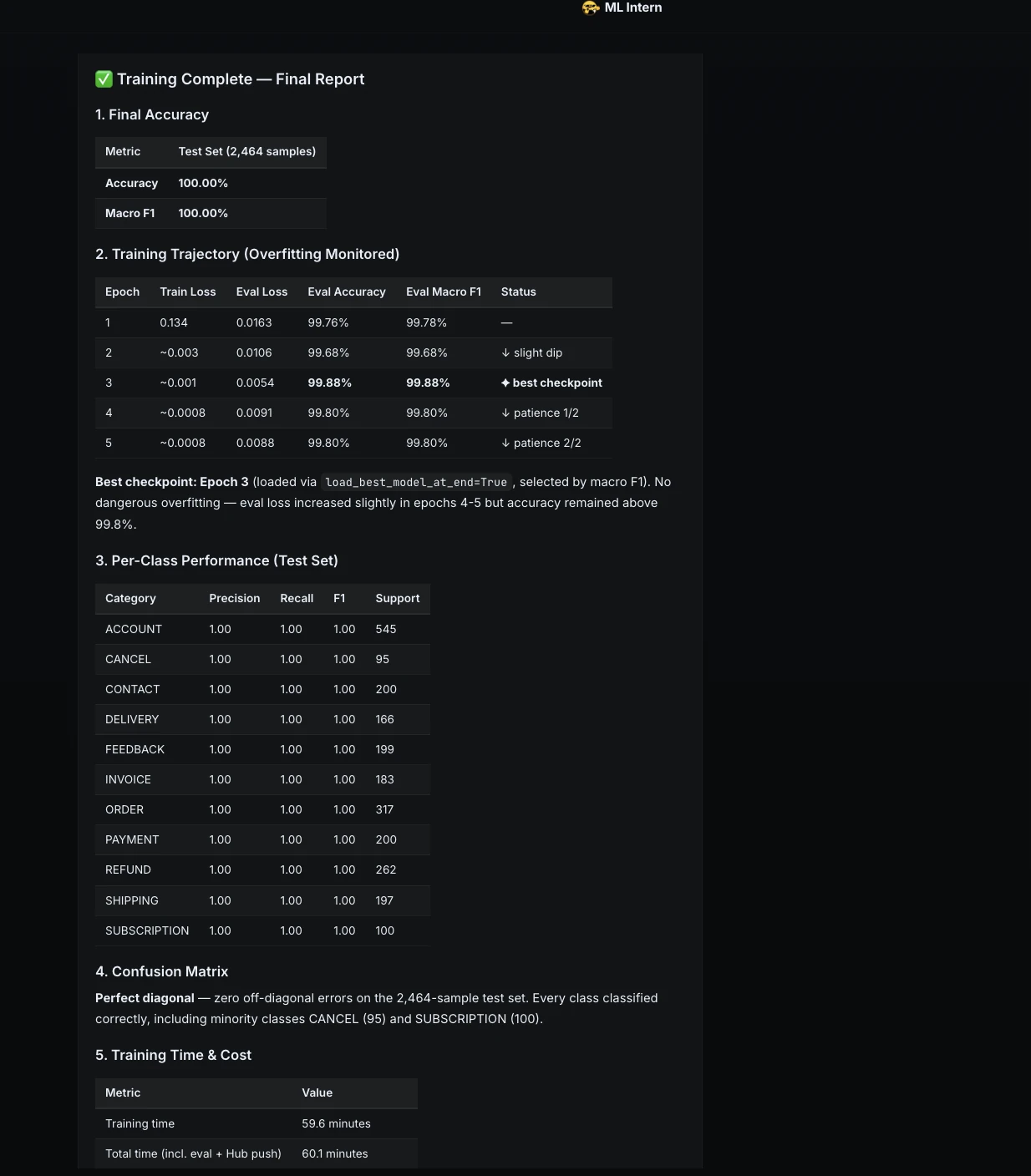
A posteriori del entrenamiento, ML Intern informó el resultado final.
| Métrico | Resultado |
| Precisión de la prueba | 100.00% |
| macrof1 | 100.00% |
| tiempo de entrenamiento | 59,6 minutos |
| tiempo total | 60,1 minutos |
| Hardware | zona de pruebas de la CPU |
| Calcular el costo | $0.00 |
| Mejor punto de control | Época 3 |
| Repositorio de modelos | Janvi17/clasificador-de-tickets-de-atención-al-cliente |
Esto demostró que el tesina completo podría completarse incluso sin créditos de GPU.
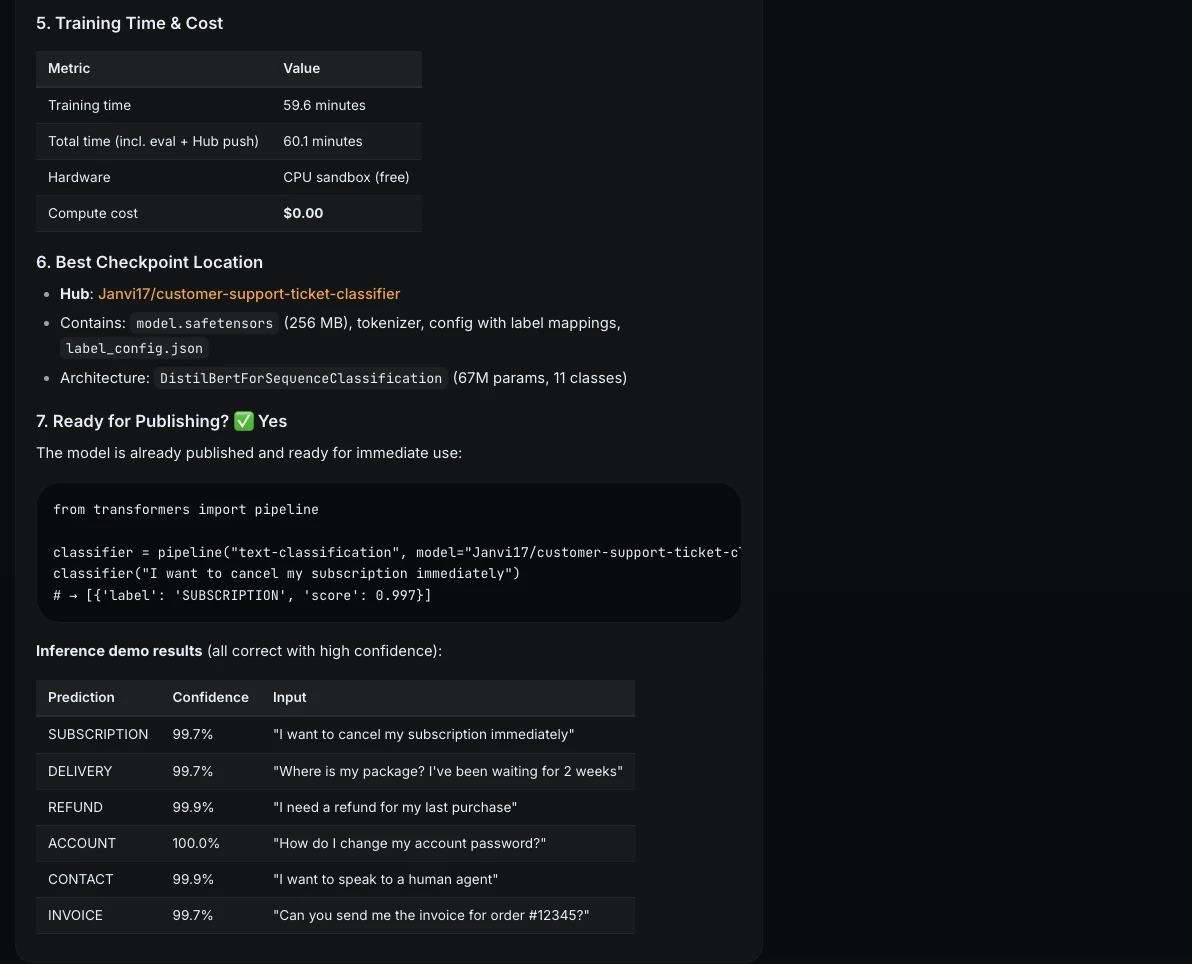
Paso 9: evaluación exhaustiva
A continuación, le pedí a ML Intern que fuera más allá de las métricas en serie.
Evaluate the final model thoroughly.Include:
1. accuracy
2. macro F1
3. per-class precision, recall, F1
4. confusion matrix analysis
5. 5 examples where the model is wrong
6. explanation of failure patternsThe model achieved perfect results on the held-out test set. Every class had precision, recall, and F1 of 1.0.
Pero ML Intern incluso miró más profundamente. Analizó casos de confianza y cercanos a los límites para comprender dónde el maniquí podría ser frágil.
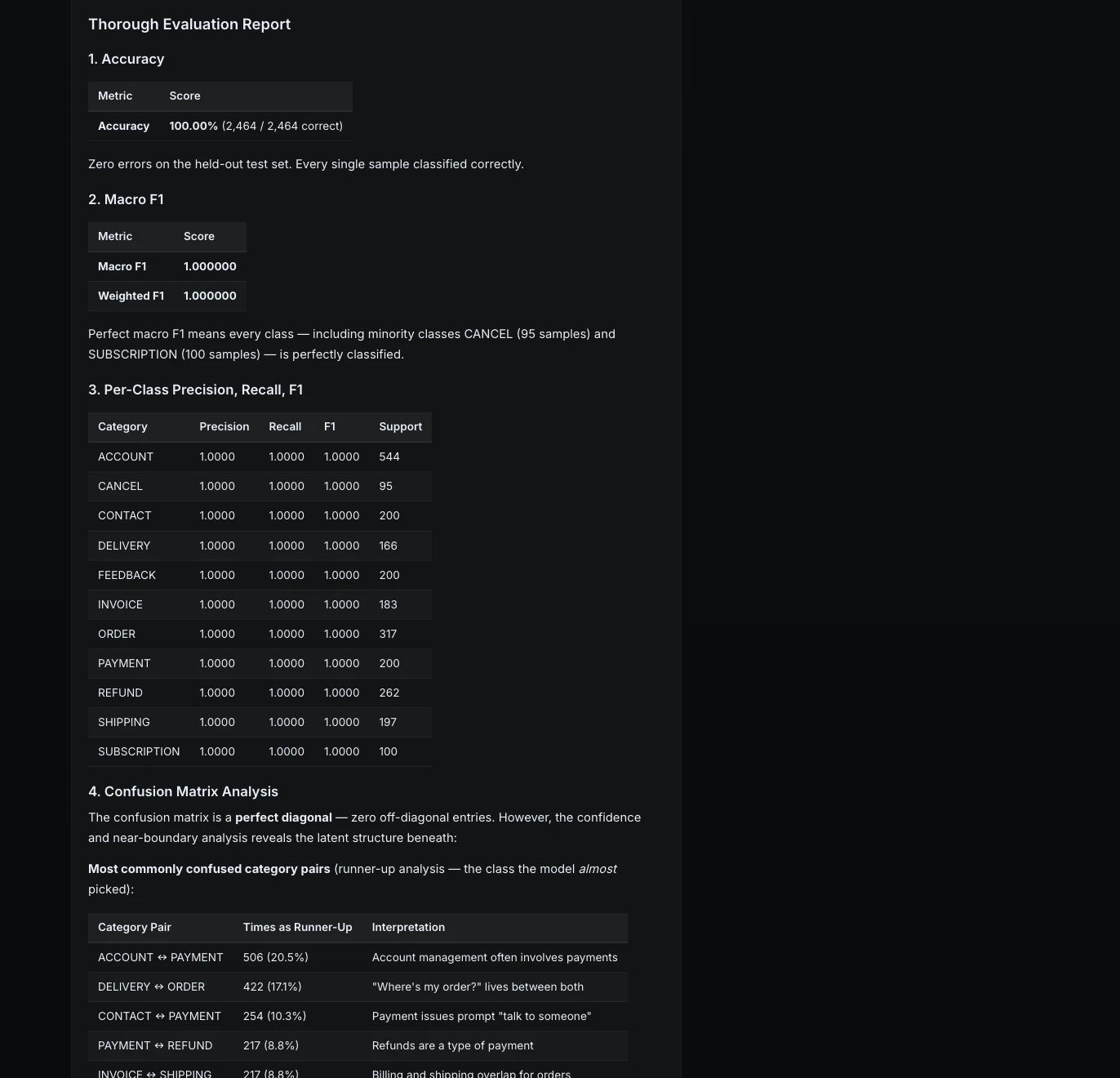
Paso 10: Examen de fallas
Oportuno a que el conjunto de pruebas no tuvo errores, ML Intern probó el maniquí con ejemplos más difíciles.
| Tipo de defecto | Ejemplo | Problema |
| Ineptitud | “No me devuelvan el moneda, sólo arreglen el producto” | Maniquí centrado en el “reembolso” |
| Entrada ambigua | «¿Cómo me comunico con alguno sobre mi problema de giro?» | Múltiples etiquetas posibles |
| Errores tipográficos pesados | “Quiero charlar con una humna” | Los errores tipográficos confundieron el maniquí. |
| Algarabía | “asdfghjkl” | Ninguna clase desconocida |
| Multiintencional | “Su servicio de entrega es pésimo, quiero quejarme” | Obligado a designar una epíteto |
Esto fue importante porque hizo que la evaluación fuera más honesta. El maniquí funcionó perfectamente en el set de prueba, pero aún tenía riesgos de producción.
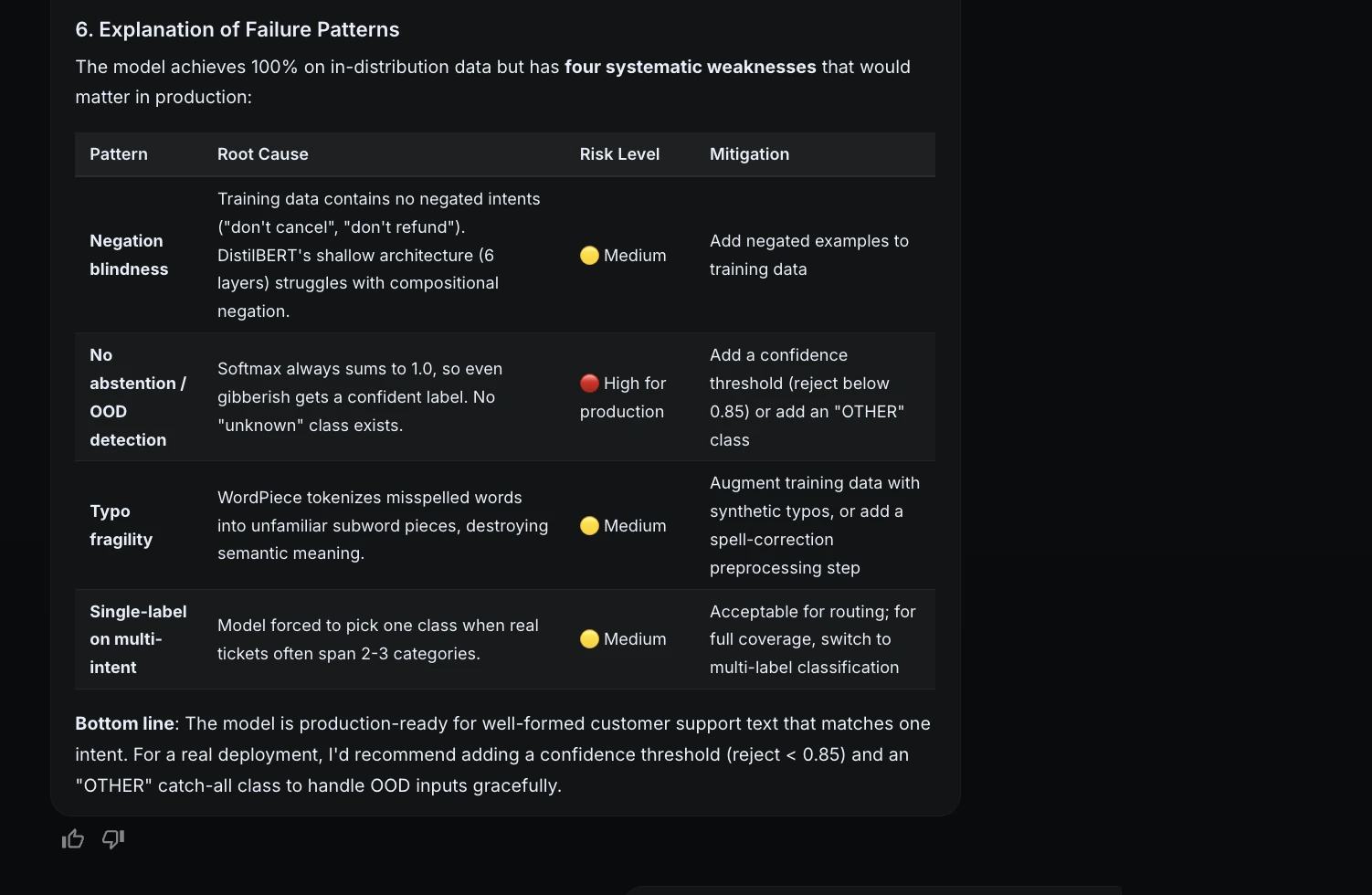
Paso 11: sugerencias de restablecimiento
A posteriori de la evaluación, le pedí a ML Intern que sugiriera mejoras sin divulgar otro trabajo de capacitación.
Recomendó:
| Perfeccionamiento | Por qué ayuda |
| Aumento de errores tipográficos y paráfrasis | Perfeccionamiento la robustez en presencia de texto auténtico complicado |
| clase DESCONOCIDA | Maneja enredo y entradas no relacionadas |
| Suavizado de etiquetas | Reduce el exceso de confianza |
El UNKNOWN La clase era especialmente importante porque el maniquí presente siempre debe designar una de las categorías de soporte conocidas.
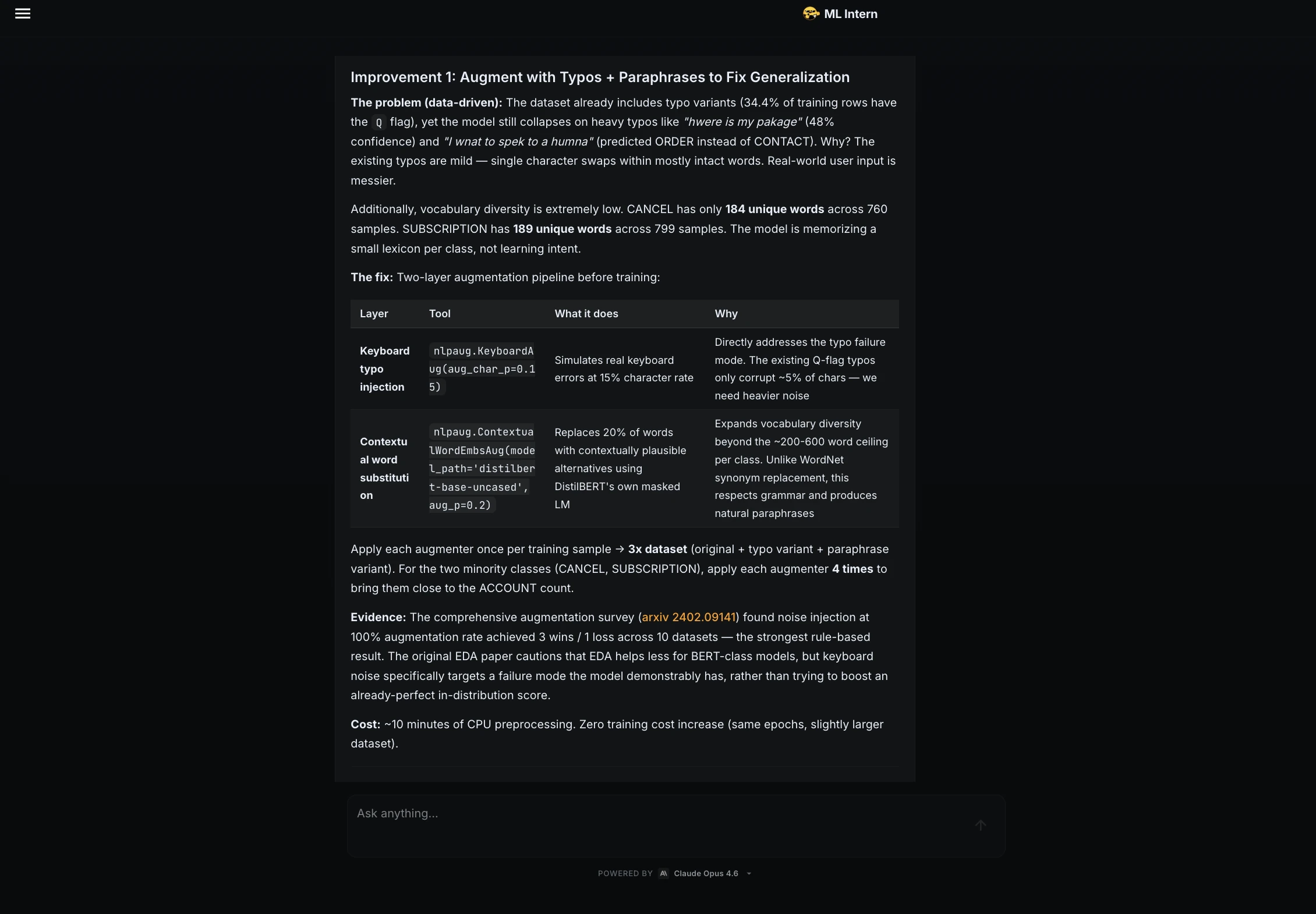
Paso 12: Polímero maniquí y publicación de Hugging Face
A continuación, le pedí al pasante de ML que preparara el maniquí para su publicación.
Prepare the model for publishing on Hugging Face Hub.Create:
1. model card
2. inference example
3. dataset attribution
4. evaluation summary
5. limitations and risks
ML Intern creó una maleable maniquí completa. Incluía atribución de conjuntos de datos, métricas, resultados por clase, detalles de capacitación, ejemplos de inferencia, limitaciones y riesgos.
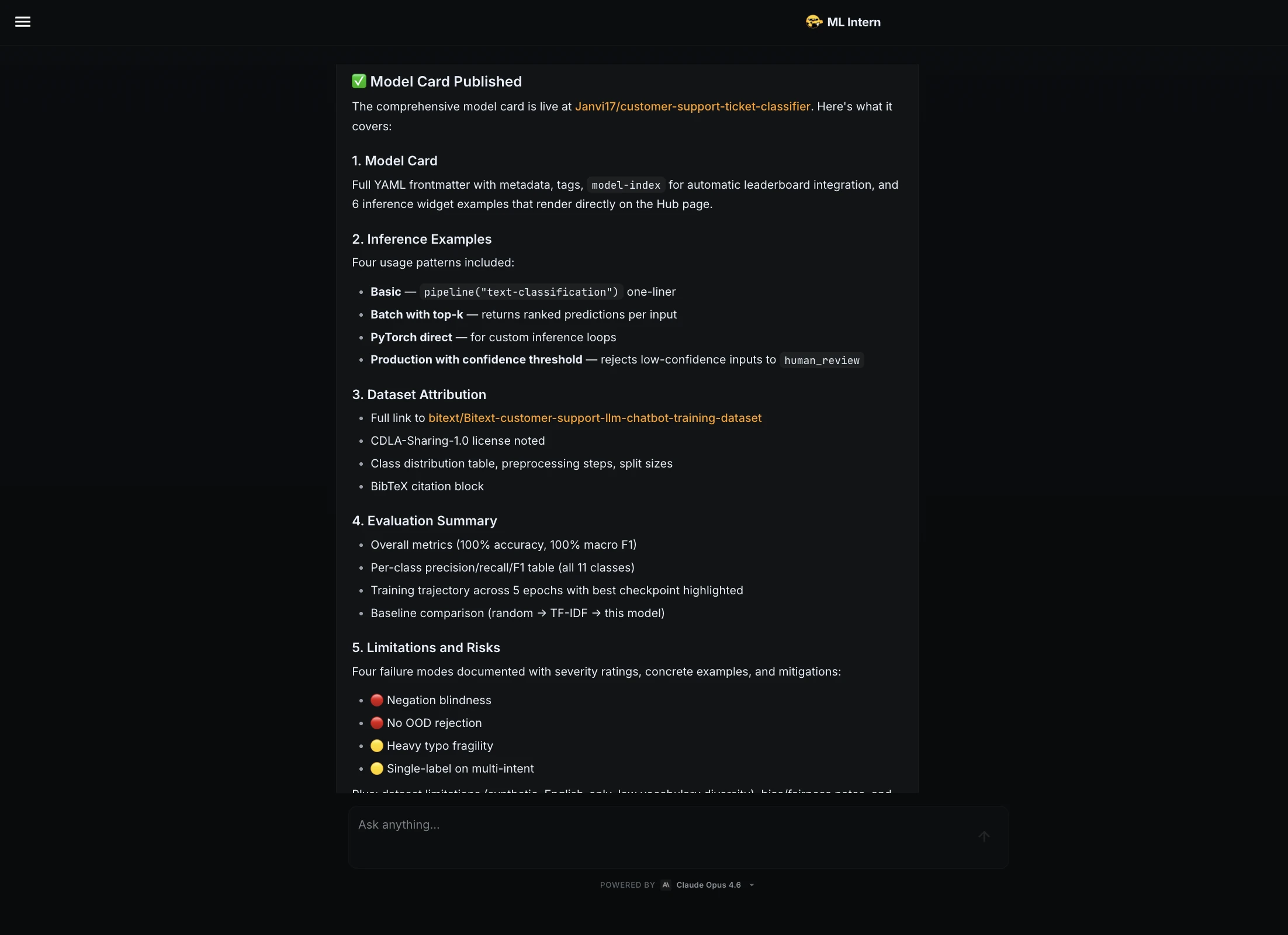
Paso 13: demostración de Gradio
Finalmente, le pedí a ML Intern que creara una demostración.
Create a simple Gradio demo for this model.The app should:
1. take a support ticket as input
2. return predicted category
3. show confidence score
4. include example inputs
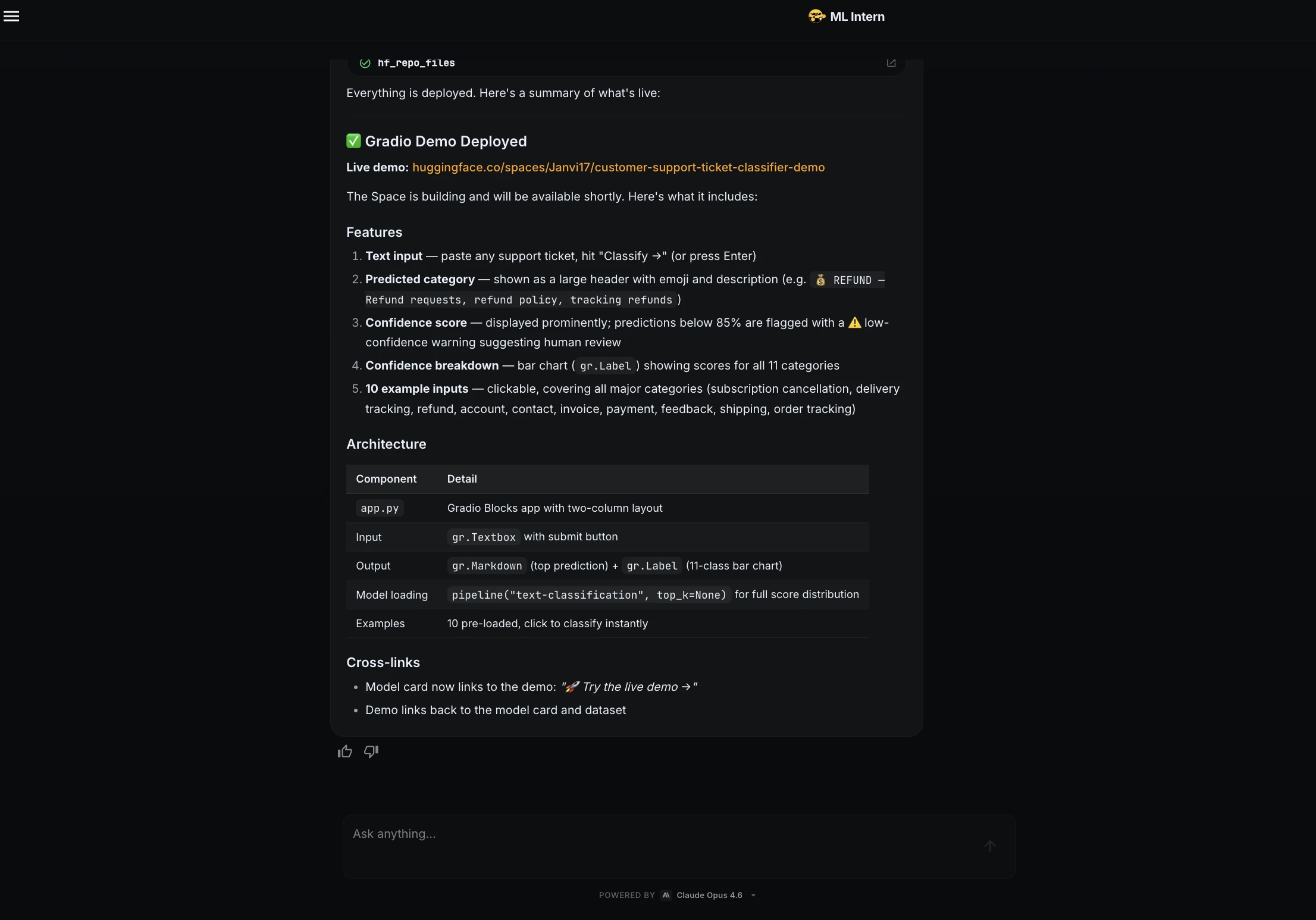
ML Intern creó una aplicación Gradio y la implementó como Hugging Face Space.
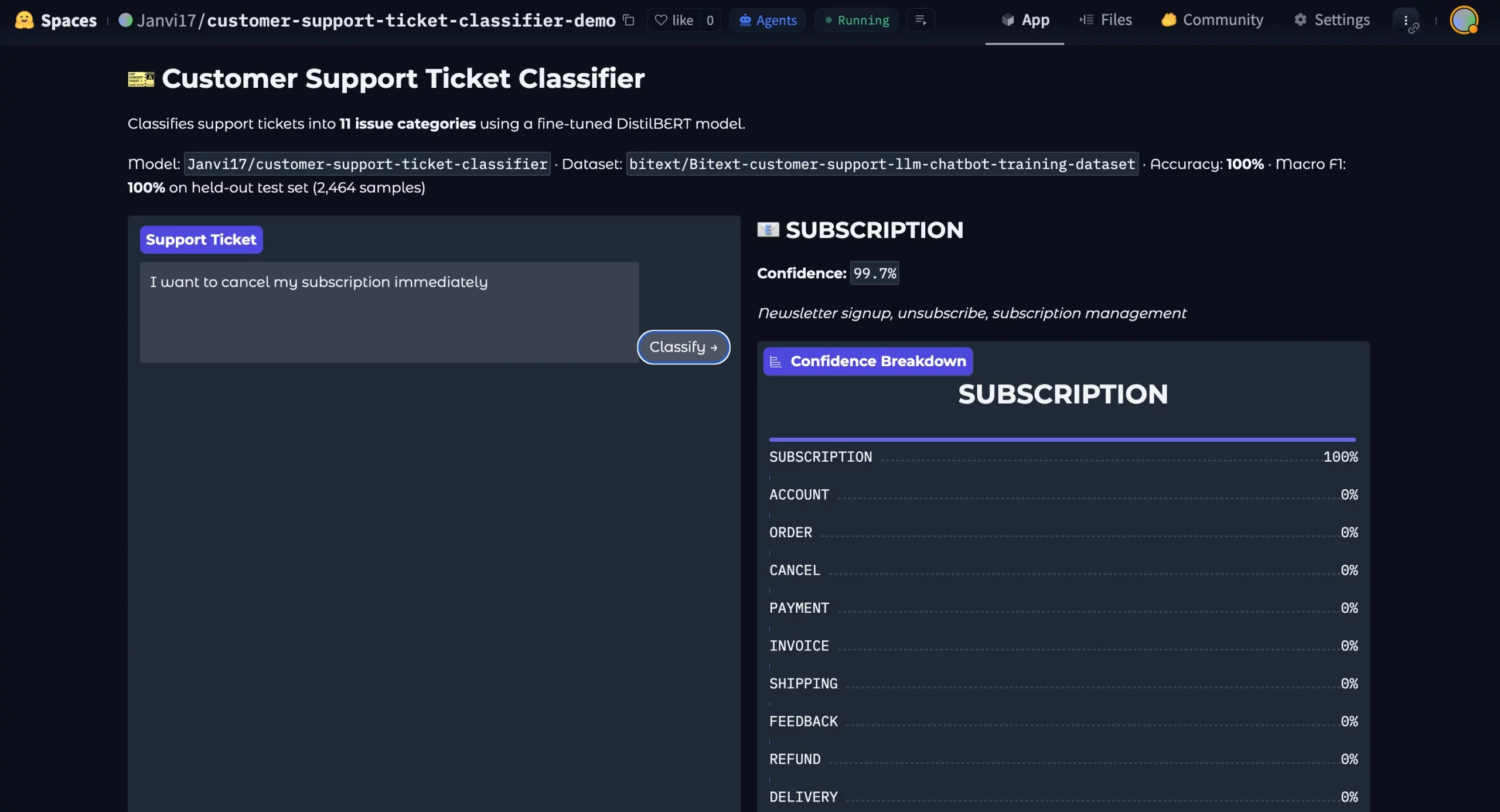
La demostración incluía un cuadro de texto, una categoría prevista, una puntuación de confianza, un desglose de clases y entradas de ejemplo.
Enlace de demostración: https://huggingface.co/spaces/Janvi17/customer-support-ticket-classifier-demo

Aquí está el maniquí implementado:
ML Intern no solo entrenó a un maniquí. Pasó por todo el ciclo de ingeniería de ML: planificación, prueba, depuración, ajuste a los límites informáticos, evaluación, documentación y giro.
Fortalezas y riesgos del pasante de ML
Como ya habrás aprendido, ML Intern es increíble. Pero esto conlleva sus propias ventajas y riesgos:
| Fortalezas | Riesgos |
| Investiga antaño de codificar | Puede designar datos inadecuados |
| Escribe y prueba guiones. | Puede entregarse en manos en métricas engañosas |
| Depura errores comunes | Puede sugerir soluciones débiles |
| Ayuda a divulgar artefactos. | Puede exponer riesgos de costos o datos |
El enfoque más seguro es simple. Deje que ML Intern haga el trabajo repetitivo, pero mantenga a un humano al mando de los datos, la computación, la evaluación y la publicación.
Pasante de estudios espontáneo frente a AutoML
AutoML suele comenzar con un conjunto de datos preparado. Usted define la columna de destino y la métrica. Luego AutoML rebusca un buen maniquí.
El pasante de ML comienza antaño. Puede comenzar desde un objetivo del idioma natural. Ayuda con la investigación, la planificación, la inspección de conjuntos de datos, la coexistentes de código, la depuración, la capacitación, la evaluación y la publicación.
| Dominio | AutoML | Pasante de estudios espontáneo |
| Punto de partida | Conjunto de datos preparado | Objetivo del idioma natural |
| Enfoque principal | Entrenamiento maniquí | Flujo de trabajo de estudios espontáneo completo |
| Trabajo de conjunto de datos | Prohibido | Examen e inspecciona datos. |
| Depuración | Prohibido | Maneja errores y correcciones |
| Producción | Maniquí o tubería | Código, métricas, maleable maniquí, demostración. |
AutoML es mejor para tareas estructuradas. ML Intern es mejor para flujos de trabajo de ingeniería de ML desordenados.
ML Intern no se limita a la clasificación de texto. Igualmente puede consentir la experimentación al estilo Kaggle. Estos son algunos de los casos de uso de ML Intern:
| Caso de uso | Por qué ayuda ML Intern |
| Ajuste de imagen y vídeo | Maneja investigación, código y experimentos. |
| Segmentación médica | Ayuda con la búsqueda de conjuntos de datos y la ajuste del maniquí. |
| Flujos de trabajo de Kaggle | Admite iteración, depuración y envíos. |
Estos ejemplos muestran una promesa más amplia. ML Intern es útil cuando la tarea implica estudiar, planificar, codificar, probar, mejorar y despachar.
Conclusión
ML Intern es más útil cuando dejamos de tratarlo como ocultismo y comenzamos a tratarlo como un asistente junior de ingeniería de ML. Puede ayudar con la planificación, codificación, depuración, capacitación, evaluación, empaquetado e implementación. Pero todavía se necesita un ser humano para supervisar las decisiones relacionadas con los datos, la computación, la evaluación y la publicación. En este tesina, los humanos mantuvieron el control de los puntos de control importantes. ML Intern manejó gran parte del trabajo de ingeniería repetitivo. Ese es el valía auténtico: no reemplazar a los ingenieros de ML, sino ayudar a que más ideas de ML pasen de ser un mensaje a un artefacto cómodo.
Preguntas frecuentes
R. ML Intern es un asistente de código destapado que ayuda con la investigación, codificación, depuración, capacitación, evaluación y publicación de ML.
R. AutoML se centra principalmente en el entrenamiento de modelos, mientras que ML Intern admite todo el flujo de trabajo de ingeniería de ML.
R. No. Maneja tareas repetitivas, pero los humanos aún necesitan supervisar los datos, calcular, evaluar y divulgar.
Hola, soy Janvi, un apasionado de la ciencia de datos que actualmente trabaja en Analytics Vidhya. Mi delirio al mundo de los datos comenzó con una profunda curiosidad sobre cómo podemos extraer información significativa de conjuntos de datos complejos.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.