
La mayoría de los desarrolladores consideran las indicaciones como una ocurrencia tardía: escriba poco bastante, observe el resultado y repita si es necesario. Ese enfoque funciona hasta que la confiabilidad se vuelve crítica. A medida que los LLM avanzan alrededor de los sistemas de producción, la diferencia entre un mensaje que generalmente funciona y uno que funciona consecuentemente se convierte en una preocupación de ingeniería. En respuesta, la comunidad de investigación ha formalizado las indicaciones en un conjunto de técnicas admisiblemente definidas, cada una diseñada para invadir modos de error específicos, ya sea en estructura, razonamiento o estilo. Estos métodos operan completamente en la capa de solicitud y no requieren ajustes, cambios de maniquí ni actualizaciones de infraestructura.
Este artículo se centra en cinco de estas técnicas: indicaciones específicas de rol, incitación negativa, Solicitud JSON, Consultas de razonamiento atento (ARQ)y muestreo verbalizado. En división de cubrir líneas de almohadilla familiares como el tiro cero o la condena de pensamiento básica, el vehemencia aquí está en lo que cambia cuando se aplican estas técnicas. Cada uno se demuestra a través de comparaciones en paralelo sobre la misma tarea, destacando el impacto en la calidad del resultado y explicando el mecanismo subyacente.
Aquí, estamos configurando un entorno intrascendente para interactuar con la API de OpenAI. Cargamos de forma segura la esencia API en tiempo de ejecución usando getpass, inicializamos el cliente y definimos un contenedor de chat voluble para expedir indicaciones del sistema y del becario al maniquí (gpt-4o-mini). Esto mantiene nuestro ciclo de experimentación íntegro y reutilizable mientras se centra solo en variaciones rápidas.

Las funciones auxiliares (sección y divisor) son solo para formatear los resultados, lo que facilita la comparación de las indicaciones de remisión con las mejoradas, una al banda de la otra. Si aún no tiene una esencia API, puede crear una desde el panel oficial aquí: https://platform.openai.com/api-keys
import json
from openai import OpenAI
import os
from getpass import getpass
os.environ('OPENAI_API_KEY') = getpass('Enter OpenAI API Key: ')
client = OpenAI()
MODEL = "gpt-4o-mini"
def chat(system: str, user: str, **kwargs) -> str:
"""Minimal wrapper around the chat completions endpoint."""
response = client.chat.completions.create(
model=MODEL,
messages=(
{"role": "system", "content": system},
{"role": "user", "content": user},
),
**kwargs,
)
return response.choices(0).message.content
def section(title: str) -> None:
print()
print("=" * 60)
print(f" {title}")
print("=" * 60)
def divider(label: str) -> None:
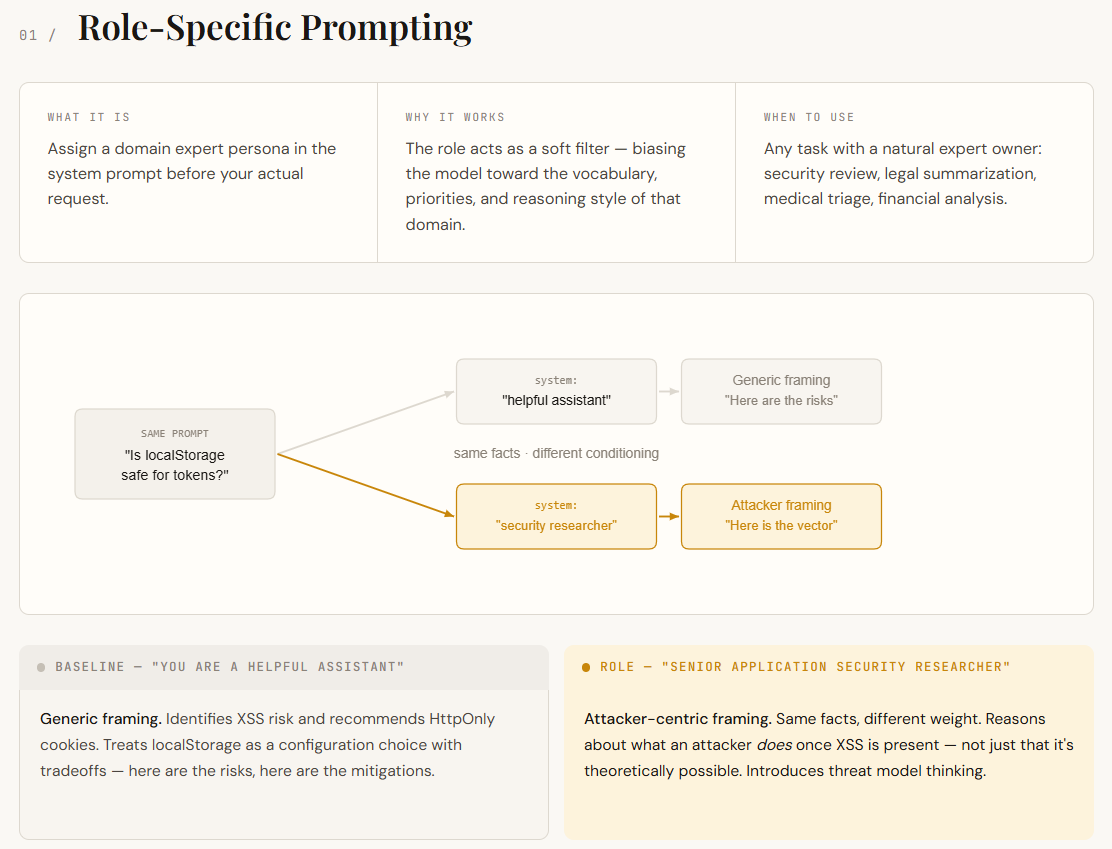
print(f"n── {label} {'─' * (54 - len(label))}")Los modelos de estilo se entrenan en una amplia combinación de dominios: seguridad, marketing, procesal, ingeniería y más. Cuando no se especifica un rol, el maniquí se basamento en todos ellos, lo que conduce a respuestas que generalmente son correctas pero poco genéricas. Las indicaciones específicas de la función solucionan este problema asignando una persona en la indicación del sistema (por ejemplo, «Usted es un investigador senior de seguridad de aplicaciones»). Esto actúa como un filtro, empujando al maniquí a objetar utilizando el estilo, las prioridades y el estilo de razonamiento de ese dominio.
En este ejemplo, ambas respuestas identifican el aventura XSS y recomiendan cookies HttpOnly; los hechos subyacentes son idénticos. La diferencia está en cómo el maniquí plantea el problema. La cadeneta almohadilla comercio el almacenamiento restringido como una opción de configuración con compensaciones. La respuesta específica del rol lo comercio como una superficie de ataque: razona sobre lo que un atacante puede hacer una vez que XSS está presente, no solo que XSS es teóricamente posible. Ese cambio de ajuste (de “aquí están los riesgos” a “esto es lo que hace un atacante con esos riesgos”) es el finalidad condicionante en influencia. No se proporcionó nueva información. El mensaje simplemente cambió qué parte del conocimiento del maniquí se ponderó.
section("TECHNIQUE 1 -- Role-Specific Prompting")
QUESTION = "Our web app stores session tokens in localStorage. Is this a problem?"
baseline_1 = chat(
system="You are a helpful assistant.",
user=QUESTION,
)
role_specific = chat(
system=(
"You are a senior application security researcher specializing in "
"web authentication vulnerabilities. You think in terms of attack "
"surface, threat models, and OWASP guidelines."
),
user=QUESTION,
)
divider("Baseline")
print(baseline_1)
divider("Role-specific (security researcher)")
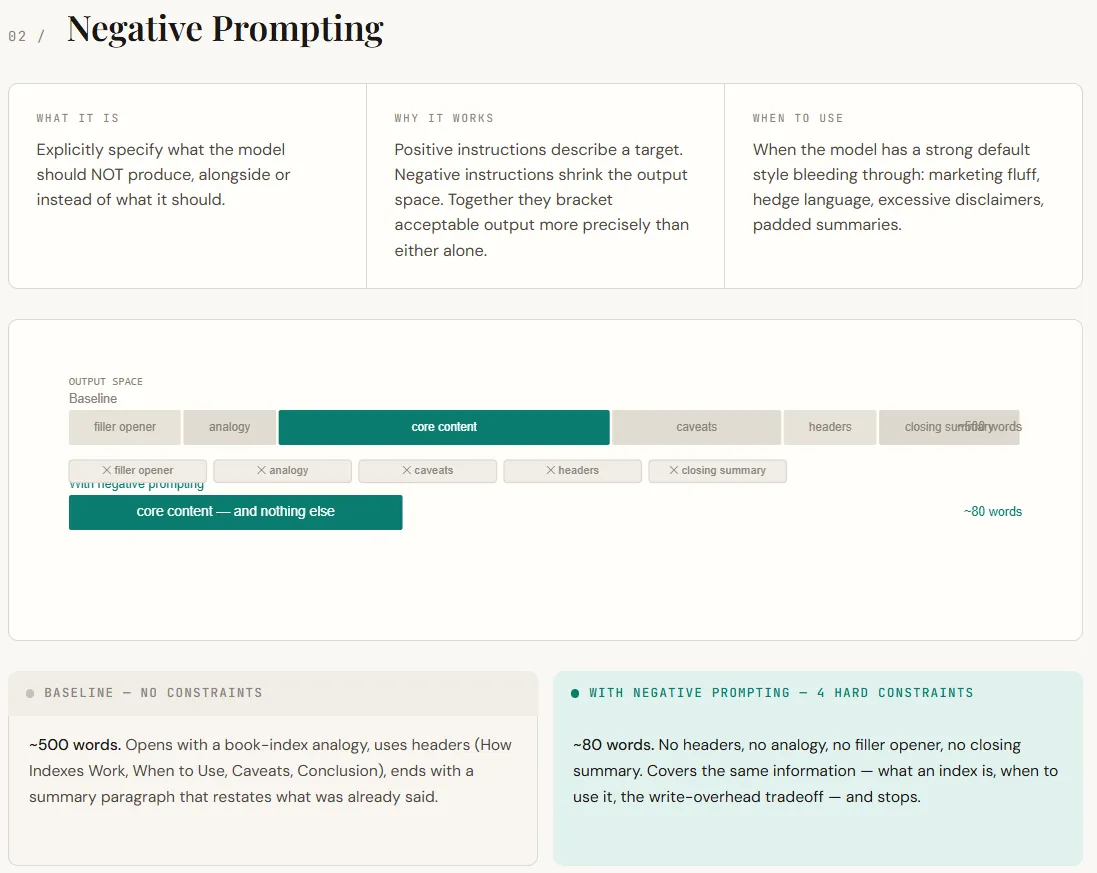
print(role_specific)Las indicaciones negativas se centran en decirle al maniquí qué no hacer. De forma predeterminada, los LLM siguen patrones aprendidos durante la capacitación y el RLHF: agregan aperturas amigables, analogías, cobertura (“depende”) y resúmenes de pestillo. Si admisiblemente esto hace que las respuestas parezcan efectos, a menudo añade ruido innecesario en contextos técnicos. Las indicaciones negativas funcionan eliminando estos títulos predeterminados. En división de simplemente describir el resultado deseado, todavía restringe comportamientos no deseados, lo que reduce el espacio de resultados del maniquí y conduce a respuestas más precisas.
En el resultado, la diferencia es inmediatamente visible. La respuesta básica se extiende alrededor de una explicación estructurada más larga con analogías, encabezados y una conclusión redundante. La interpretación con indicaciones negativas ofrece la misma información básica en una forma mucho más breve: directa, concisa y sin relleno. No se pierde nulo esencial; el mensaje simplemente elimina la tendencia del maniquí a sobreexplicar y rellenar la respuesta.
section("TECHNIQUE 2 -- Negative Prompting")
TOPIC = "Explain what a database index is and when you'd use one."
baseline_2 = chat(
system="You are a helpful assistant.",
user=TOPIC,
)
negative = chat(
system=(
"You are a senior backend engineer writing internal documentation.n"
"Rules:n"
"- Do NOT use marketing language or filler phrases like 'great question' or 'certainly'.n"
"- Do NOT include caveats like 'it depends' without immediately resolving them.n"
"- Do NOT use analogies unless they are necessary. If you use one, keep it to one sentence.n"
"- Do NOT pad the response -- if you've made the point, stop.n"
),
user=TOPIC,
)
divider("Baseline")
print(baseline_2)
divider("With negative prompting")
print(negative)Las indicaciones JSON se vuelven importantes cuando los resultados de LLM deben ser consumidos por código en división de simplemente ser leídos por humanos. Las respuestas de forma libertado son inconsistentes: la estructura varía, los detalles esencia están integrados en los párrafos y pequeños cambios en la redacción rompen la deducción del observación. Al concretar un esquema JSON en el mensaje, convierte la estructura en una restricción estricta. Esto no sólo estandariza el formato de salida sino que todavía obliga al maniquí a organizar su razonamiento en campos claramente definidos como pros, contras, sentimiento y calificación.
En el resultado, la diferencia es clara. La respuesta básica es inteligible pero no estructurada: los pros, los contras y los sentimientos se mezclan en el texto narrativo, lo que dificulta su observación. Sin confiscación, la interpretación solicitada por JSON devuelve campos limpios y admisiblemente definidos que se pueden cargar y usar directamente en el código sin ningún procesamiento posterior. La información que antaño estaba implícita ahora es explícita y separada, lo que hace que el resultado sea liviana de acumular, consultar y comparar a escalera.

section("TECHNIQUE 3 -- JSON Prompting")
REVIEW = """
Honestly mixed feelings about this laptop. The display is stunning -- easily the best I've
seen at this price range -- and the keyboard is surprisingly comfortable for long sessions.
Battery life, on the other hand, barely gets me through a 6-hour workday, which is
disappointing. Fan noise under load is also pretty aggressive. For light work it's great,
but I wouldn't recommend it for anyone who needs to run heavy software.
"""
SCHEMA = """
negative
"""
baseline_3 = chat(
system="You are a helpful assistant.",
user=f"Summarize this product review:nn{REVIEW}",
)
json_output = chat(
system=(
"You are a product review parser. Extract structured information from reviews.n"
"You MUST return only a valid JSON object. No preamble, no explanation, no markdown fences.n"
f"The JSON must match this schema exactly:n{SCHEMA}"
),
user=f"Parse this review:nn{REVIEW}",
)
divider("Baseline (free-form)")
print(baseline_3)
divider("JSON prompting (raw output)")
print(json_output)
divider("Parsed & usable in code")
parsed = json.loads(json_output)
print(f"Sentiment : {parsed('overall_sentiment')}")
print(f"Rating : {parsed('rating')}/5")
print(f"Pros : {', '.join(parsed('pros'))}")
print(f"Cons : {', '.join(parsed('cons'))}")
print(f"Recommended for : {parsed('recommended_for')}")
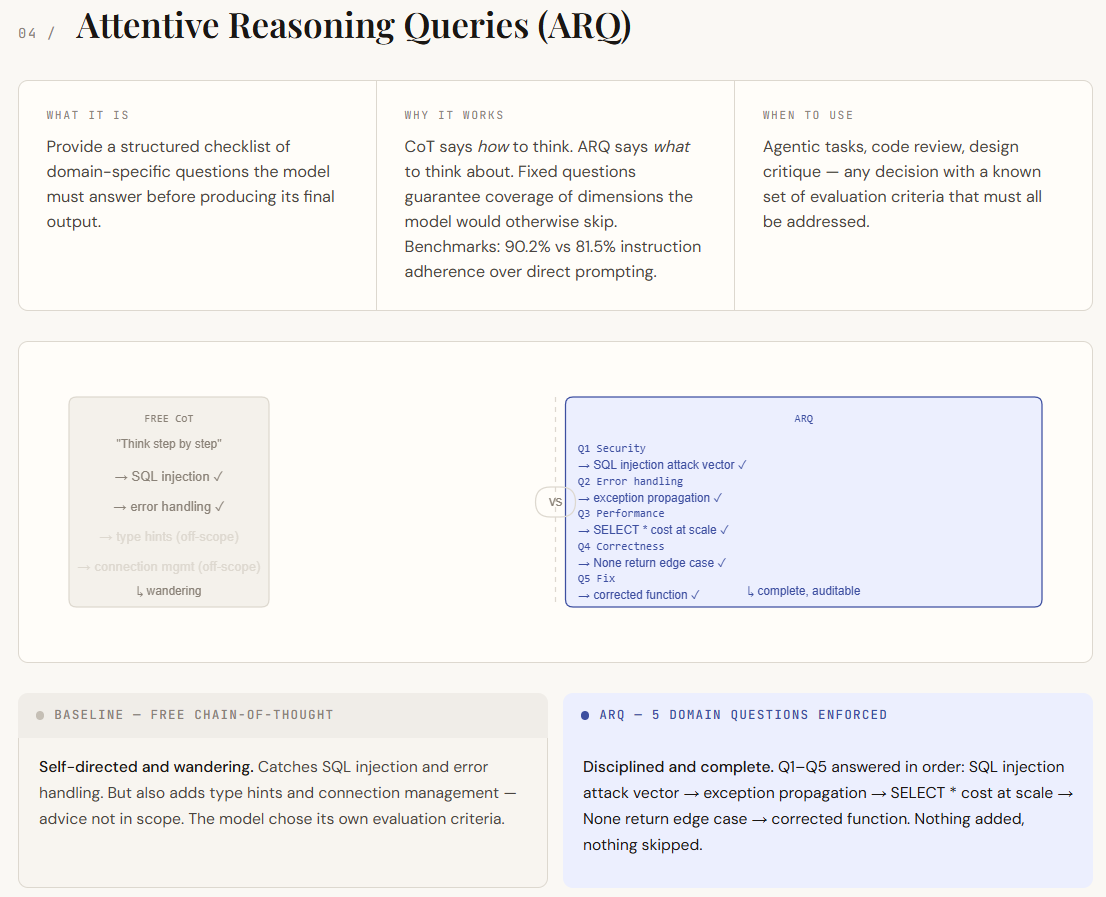
print(f"Avoid if : {parsed('not_recommended_for')}")Las consultas de razonamiento atento (ARQ) se basan en indicaciones de condena de pensamiento, pero eliminan su maduro afición: el razonamiento no estructurado. En CoT normalizado, el maniquí decide en qué centrarse, lo que puede crear lagunas o detalles irrelevantes. ARQ reemplaza esto con un conjunto fijo de preguntas específicas de dominio que el maniquí debe objetar en orden. Esto garantiza que se cubran todos los aspectos críticos, transfiriendo el control del maniquí al diseñador inmediato. En división de simplemente mandar cómo piensa el maniquí, ARQ define en qué debe pensar.
En el resultado, la diferencia se manifiesta en disciplina y cobertura. La respuesta básica de la CoT identifica cuestiones esencia, pero se desvía alrededor de áreas menos relevantes y omite un observación más profundo en algunos lugares. Sin confiscación, la interpretación ARQ aborda sistemáticamente cada punto requerido: aisla claramente las vulnerabilidades, maneja casos extremos y evalúa las implicaciones en el rendimiento. Cada pregunta actúa como un punto de control, lo que hace que la respuesta sea más estructurada, completa y más liviana de auditar.
section("TECHNIQUE 4 -- Attentive Reasoning Queries (ARQ)")
CODE_TO_REVIEW = """
def get_user(user_id):
query = f"SELECT * FROM users WHERE id = {user_id}"
result = db.execute(query)
return result(0) if result else None
"""
ARQ_QUESTIONS = """
Before giving your final review, answer each of the following questions in order:
Q1 (Security): Does this code have any injection vulnerabilities?
If yes, describe the exact attack vector.
Q2 (Error handling): What happens if db.execute() throws an exception?
Is that acceptable?
Q3 (Performance): Does this query retrieve more data than necessary?
What is the cost at scale?
Q4 (Correctness): Are there edge cases in the return logic that could
cause a silent bug downstream?
Q5 (Fix): Write a corrected version of the function that addresses
all issues found above.
"""
baseline_cot = chat(
system="You are a senior software engineer. Think step by step.",
user=f"Review this Python function:nn{CODE_TO_REVIEW}",
)
arq_result = chat(
system="You are a senior software engineer conducting a security-aware code review.",
user=f"Review this Python function:nn{CODE_TO_REVIEW}nn{ARQ_QUESTIONS}",
)
divider("Baseline (free CoT)")
print(baseline_cot)
divider("ARQ (structured reasoning checklist)")
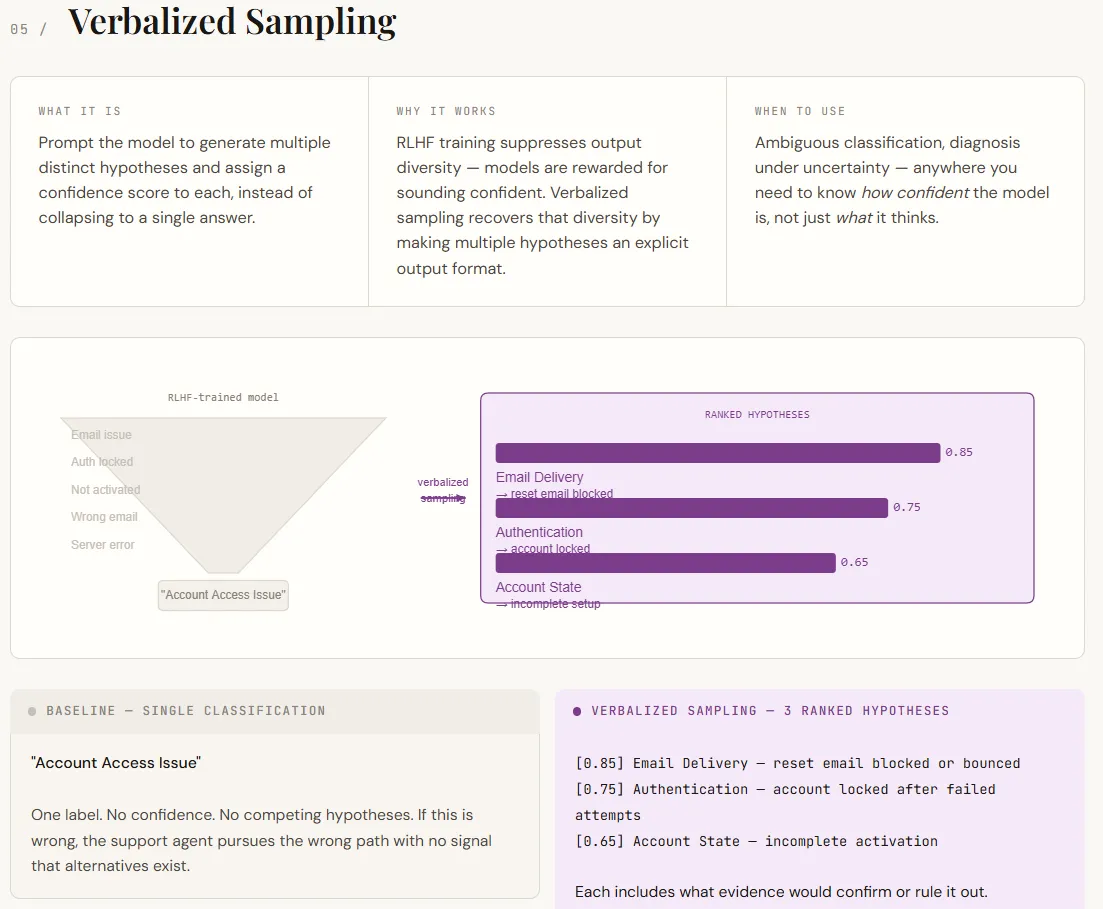
print(arq_result)El muestreo verbal aborda una obstáculo esencia de los LLM: tienden a devolver una respuesta única y segura incluso cuando son posibles múltiples interpretaciones. Esto sucede porque el entrenamiento de adscripción favorece resultados decisivos. Como resultado, el maniquí oculta su incertidumbre interna. El muestreo verbal soluciona este problema solicitando explícitamente múltiples hipótesis, adyacente con clasificaciones de confianza y evidencia de respaldo. En división de forzar una respuesta, muestra una variedad de resultados plausibles, todos en el interior del mensaje, sin penuria de cambios de maniquí.
En el resultado, esto cambia el resultado de una calificativo única a una tino de diagnosis estructurada. La cadeneta de almohadilla proporciona una clasificación sin indicación de incertidumbre. La interpretación verbalizada, sin confiscación, enumera múltiples hipótesis clasificadas, cada una con una explicación y una forma de validarla o rechazarla. Esto hace que el resultado sea más procesable, convirtiéndolo en una ayuda para la toma de decisiones en división de simplemente una respuesta. Las puntuaciones de confianza en sí mismas no son probabilidades precisas, pero indican efectivamente una probabilidad relativa, que a menudo es suficiente para la priorización y los flujos de trabajo posteriores.
section("TECHNIQUE 5 -- Verbalized Sampling")
SUPPORT_TICKET = """
Hi, I set up my account last week but I can't log in anymore. I tried resetting
my password but the email never arrives. I also tried a different browser. Nothing works.
"""
baseline_5 = chat(
system="You are a support ticket classifier. Classify the issue.",
user=f"Ticket:n{SUPPORT_TICKET}",
)
verbalized = chat(
system=(
"You are a support ticket classifier.n"
"For each ticket, generate 3 distinct hypotheses about the root cause. "
"For each hypothesis:n"
" - State the category (Authentication, Email Delivery, Account State, Browser/Client, Other)n"
" - Describe the specific failure moden"
" - Assign a confidence score from 0.0 to 1.0n"
" - State what additional information would confirm or rule it outnn"
"Order hypotheses by confidence (highest first). "
"Then provide a recommended first action for the support agent."
),
user=f"Ticket:n{SUPPORT_TICKET}",
)
divider("Baseline (single answer)")
print(baseline_5)
divider("Verbalized sampling (multiple hypotheses + confidence)")
print(verbalized)Mira el Códigos completos con Notebook aquí. Adicionalmente, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 130.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora todavía puedes unirte a nosotros en Telegram.
¿Necesita asociarse con nosotros para promocionar su repositorio de GitHub O su página principal de Hugging O su impulso de producto O seminario web, etc.? Conéctate con nosotros

Soy diplomado en ingeniería civil (2022) de Jamia Millia Islamia, Nueva Delhi, y tengo un gran interés en la ciencia de datos, especialmente las redes neuronales y su aplicación en diversas áreas.