
Puede sobrevenir algunas limitaciones prácticas a la hora de implementar modelos de IA para entornos minoristas. Los entornos minoristas pueden incluir sistemas a nivel de tienda, dispositivos periféricos y configuraciones ajustadas al presupuesto, especialmente para empresas minoristas pequeñas y medianas. Uno de esos casos de uso importantes es la previsión de la demanda para la dirección de inventario u optimización de estanterías. Requiere que el maniquí implementado sea pequeño, rápido y preciso.
Eso es exactamente en lo que trabajaremos aquí. En este artículo, lo guiaré paso a paso a través de tres técnicas de compresión. Comenzaremos construyendo un LSTM de narración. Luego mediremos su tamaño y precisión, y luego aplicaremos cada método de compresión uno a la vez para ver cómo cambia el maniquí. Al final, reuniremos todo con una comparación banda a banda.
Entonces, sin dilación, profundicemos.
El problema: IA minorista en el borde
Ahora que todo se está moviendo alrededor de el borde, el comercio minorista además está avanzando alrededor de aplicaciones móviles, dispositivos y sensores IOT a nivel de tienda, que pueden ejecutar los modelos y predecir el pronóstico localmente en extensión de clamar a las API de la estrato cada vez.
A maniquí de pronóstico ejecutarse en un dispositivo de tienda o una aplicación móvil, como un sensor de estante o un escáner, puede desavenir limitaciones como memoria limitada, depósito limitada y requiere una descenso latencia de red.
Incluso para implementaciones en la estrato, si el tamaño del maniquí es más pequeño, los costos pueden reducirse. Especialmente cuando ejecuta miles de predicciones diariamente en un enorme catálogo de productos. Un maniquí con un tamaño de 4 KB cuesta significativamente menos que un maniquí con un tamaño de 64 KB
No sólo el costo, la velocidad de inferencia además afecta las decisiones en tiempo efectivo. Una predicción del maniquí más rápida puede beneficiar la optimización del inventario y las alertas de reposición.
Configuración de evaluación comparativa
Para el prueba, utilicé el conjunto de datos de pronóstico de demanda de artículos de Kaggle a nivel de tienda. Los datos se distribuyen en 5 primaveras de ventas diarias en 10 tiendas y 50 artículos. Este conjunto de datos públicos tiene un patrón minorista con estacionalidad, tendencias y ruido semanales.
Para ello, utilicé datos de muestra de 5 tiendas, 10 artículos y creé 50 series temporales independientes. Cada una de las combinaciones de artículos de la tienda genera sus propias secuencias, lo que dará como resultado un total de 72.000 datos de muestra de entrenamiento. El maniquí predecirá los datos de ventas del día venidero basándose en el historial de ventas de los últimos 14 días, que es una configuración popular para los datos de previsión de la demanda.
El prueba se realizó 3 veces y se promedió para obtener resultados confiables.
| Parámetro | Detalles |
|---|---|
| Conjunto de datos | Conjunto de datos de previsión de demanda de artículos de la tienda Kaggle |
| Muestra | 5 tiendas × 10 artículos = 50 series temporales |
| Muestras de entrenamiento | ~72.000 muestras totales |
| Largura de la secuencia | Datos pasados 14 días |
| Tarea | Predicción de ventas diarias en un solo paso |
| Métrico | Error porcentual inmutable medio (MAPE) |
| Ejecuciones por maniquí | 3 veces, promedio |
Paso 1: construir el LSTM de narración
Antaño de comprimir cualquier cosa, necesitamos un punto de narración. Nuestra semirrecta de colchoneta es un LSTM normalizado con 64 unidades ocultas entrenadas en el conjunto de datos descrito anteriormente.
Código de narración:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
def build_lstm(units, seq_length):
"""Build LSTM with specified hidden units."""
model = Sequential((
LSTM(units, activation='tanh', input_shape=(seq_length, 1)),
Dropout(0.2),
Dense(1)
))
model.compile(optimizer="adam", loss="mse")
return model
# Baseline: 64 hidden units
baseline_model = build_lstm(64, seq_length=14) Rendimiento de narración:
| Método | Maniquí | Tamaño (KB) | MAPA (%) | MAPE normalizado (%) |
|---|---|---|---|---|
| Colchoneta | LSTM-64 | 66,25 | 15,92 | ±0,10 |
Este es nuestro punto de narración. El maniquí LSTM-64 tiene un tamaño de 66,25 KB con un MAPE del 15,92%. Cada técnica de compresión a continuación se comparará con estos números.
Paso 2: Técnica de compresión 1: dimensionamiento de la casa
En este enfoque, reducimos la capacidad del maniquí en algunas unidades ocultas. En extensión de un LSTM de 64 unidades, entrenamos un maniquí de 32/16 unidades desde cero y vemos cómo funciona. Este es un enfoque más simple entre los tres.
Código:
# Using the same build_lstm function from baseline
# Compare: 64 units (66KB) vs 32 units vs 16 units
model_32 = build_lstm(32, seq_length=14)
model_16 = build_lstm(16, seq_length=14)Resultados:
| Método | Maniquí | Tamaño (KB) | MAPA (%) | MAPE normalizado (%) |
|---|---|---|---|---|
| Colchoneta | LSTM-64 | 66,25 | 15,92 | ±0,10 |
| Obra | LSTM-32 | 17.13 | 16.22 | ±0,09 |
| Obra | LSTM-16 | 4.57 | 16,74 | ±0,46 |
Observación: El maniquí LSTM-16 es 14,5 veces más pequeño que el maniquí de 64 bits (4,57 KB frente a 66,25 KB), mientras que MAPE aumenta solo un 0,82 %. Para muchas aplicaciones en el comercio minorista, esta diferencia es mínima, mientras que el maniquí LSTM 32 ofrece un término medio con una compresión de 3,9x y una pérdida de precisión del 0,3%.
Paso 3: Técnica de compresión 2: poda de magnitud
Poda es eliminar pesos de descenso importancia del entrenamiento del maniquí. La idea central es que las contribuciones de muchas conexiones de redes neuronales son mínimas y pueden ignorarse o establecerse en cero. Posteriormente de la poda, el maniquí se ajusta para recuperar la precisión.
Código:
import numpy as np
from tensorflow.keras.optimizers import Adam
def apply_magnitude_pruning(model, target_sparsity=0.5):
"""Apply per-layer magnitude pruning, skip biases"""
masks = ()
for layer in model.layers:
weights = layer.get_weights()
layer_masks = ()
new_weights = ()
for w in weights:
if w.ndim == 1: # Bias - don't prune
layer_masks.append(None)
new_weights.append(w)
else: # Kernel - prune per-layer
threshold = np.percentile(np.abs(w), target_sparsity * 100)
mask = (np.abs(w) >= threshold).astype(np.float32)
layer_masks.append(mask)
new_weights.append(w * mask)
masks.append(layer_masks)
layer.set_weights(new_weights)
return masks
# After pruning, fine-tune with lower learning rate
model.compile(optimizer=Adam(learning_rate=0.0001), loss="mse")
model.fit(X_train, y_train, epochs=50, callbacks=(maintain_sparsity))Resultados:
| Método | Maniquí | Tamaño (KB) | MAPA (%) | MAPE normalizado (%) |
|---|---|---|---|---|
| Colchoneta | LSTM-64 | 66,25 | 15,92 | ±0,10 |
| Poda | Poda-30% | 11,99 | 16.04 | ±0,09 |
| Poda | Podado-50% | 8.56 | 16.20 | ±0,08 |
| Poda | Podado-70% | 5.14 | 16,84 | ±0,16 |
Observación: Con la poda de magnitud con una escasez del 50 %, el tamaño del maniquí se redujo a 8,56 KB con solo una pérdida de precisión del 0,28 % en comparación con la semirrecta colchoneta. Incluso con una poda del 70 %, el MAPE estuvo por debajo del 17 %.
El hallazgo importante para que la poda funcione en LSTM fue usar umbrales en cada capa en extensión de un umbralado entero, eliminar ponderaciones de sesgo (usando solo ponderaciones de kernel) y además usar una tasa de enseñanza más descenso durante el ajuste fino. Sin estos, el rendimiento de LSTM puede degradarse significativamente adecuado a la interdependencia de los pesos recurrentes.
Paso 4: Técnica de compresión 3: cuantización INT8
La cuantificación se ocupa de la conversión de pesos de coma flotante de 32 bits a enteros de 8 bits luego del entrenamiento, lo que reducirá el tamaño del maniquí 4 veces sin perder mucha precisión.
Código:
def simulate_int8_quantization(model):
"""Simulate INT8 quantization on model weights."""
for layer in model.layers:
weights = layer.get_weights()
quantized = ()
for w in weights:
w_min, w_max = w.min(), w.max()
if w_max - w_min > 1e-10:
# Quantize to INT8 range (0, 255)
scale = (w_max - w_min) / 255.0
zero_point = np.round(-w_min / scale)
w_int8 = np.round(w / scale + zero_point).clip(0, 255)
# Dequantize
w_quant = (w_int8 - zero_point) * scale
else:
w_quant = w
quantized.append(w_quant.astype(np.float32))
layer.set_weights(quantized)Para la implementación en producción, se recomienda utilizar la cuantificación integrada de TensorFlow Lite:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = (tf.lite.Optimize.DEFAULT)
tflite_model = converter.convert()Resultados:
| Método | Maniquí | Tamaño (KB) | MAPA (%) | MAPE normalizado (%) |
|---|---|---|---|---|
| Colchoneta | LSTM-64 | 66,25 | 15,92 | ±0,10 |
| Cuantización | INT8 | 4.28 | 16.21 | ±0,22 |
Observación: La cuantificación INT8 ha limitado el tamaño del maniquí a 4,28 KB desde 66,25 KB (compresión de 15,5x) con un aumento del 0,29% en la precisión. Este es el maniquí más pequeño con una precisión comparable al maniquí LSTM 32 sin podar. Especialmente para implementaciones, se admite la inferencia INT8 y es la mejor entre tres técnicas.
Reuniéndolo todo: comparación banda a banda
Así es como se compara cada técnica con la semirrecta de colchoneta de LSTM-64:
| Técnica | Relación de compresión | Impacto en la precisión |
|---|---|---|
| LSTM-32 | 3,9x | +0,30% MAPA |
| LSTM-16 | 14,5x | +0,82% MAPE |
| Poda-30% | 5,5x | +0,12% MAPE |
| Podado-50% | 7,7x | +0,28% MAPE |
| Podado-70% | 12,9x | +0,92% MAPE |
| Cuantización INT8 | 15,5x | +0,29% MAPE |
Los resultados completos de las pruebas comparativas en todas las técnicas:
| Método | Maniquí | Tamaño (KB) | MAPA (%) | MAPE normalizado (%) |
|---|---|---|---|---|
| Colchoneta | LSTM-64 | 66,25 | 15,92 | ±0,10 |
| Obra | LSTM-32 | 17.13 | 16.22 | ±0,09 |
| Obra | LSTM-16 | 4.57 | 16,74 | ±0,46 |
| Poda | Poda-30% | 11,99 | 16.04 | ±0,09 |
| Poda | Podado-50% | 8.56 | 16.20 | ±0,08 |
| Poda | Podado-70% | 5.14 | 16,84 | ±0,16 |
| Cuantización | INT8 | 4.28 | 16.21 | ±0,22 |
Cada una de las técnicas anteriores tiene sus propias compensaciones. El tamaño de la casa puede resumir el tamaño del maniquí, pero es necesario retornar a entrenarlo. La poda preservará la casa pero filtrará las conexiones. La cuantificación puede ser rápida pero requiere tiempos de ejecución de inferencia compatibles.
Nominar la técnica adecuada
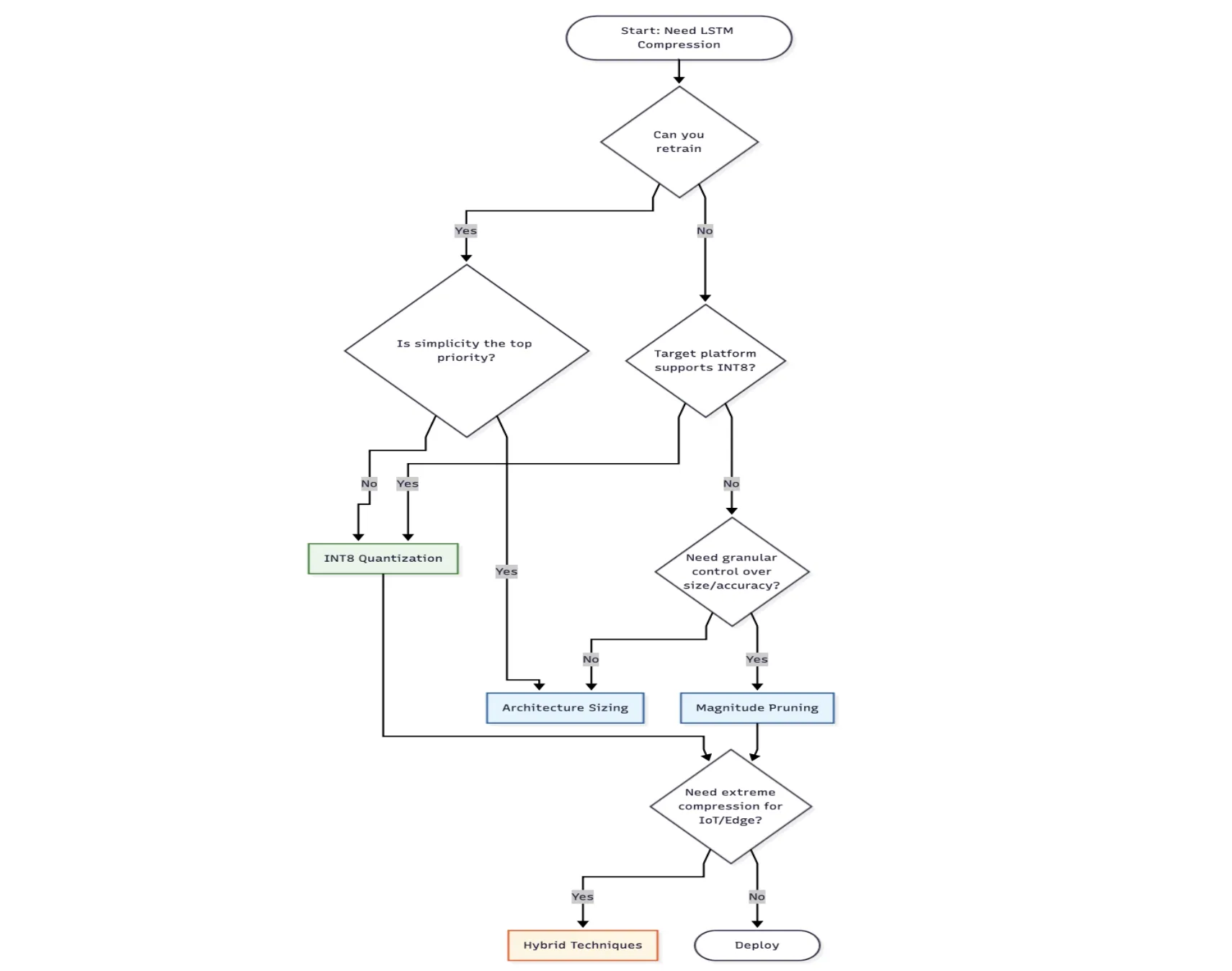
Elija el tamaño de la casa cuando:
- Estás empezando desde cero y puedes entrenar.
- La simplicidad importa más que la máxima compresión
Elija podar cuando:
- Ya tienes un maniquí entrenado y buscas compresión del maniquí.
- Necesita control a nivel granular sobre la compensación entre precisión y tamaño
Opte por la cuantización cuando:
- Necesita la máxima compresión con una mínima pérdida de precisión
- Su plataforma de implementación de destino tiene optimización INT8 (Ex, dispositivos móviles, periféricos)
- Quiere una posibilidad rápida sin retornar a capacitarse desde el principio.
Elija técnicas híbridas cuando:
- Se requiere una gran compresión (implementación periférica, IoT)
- Puede cambiar tiempo en iterar en el proceso de compresión.
Puntos para rememorar para la implementación minorista
La compresión de modelos es sólo una parte del rompecabezas. Hay otros factores a considerar para los sistemas minoristas, como se indica a continuación.
- Un maniquí más ínclito siempre es mejor que un maniquí más pequeño y obsoleto. Incorpore la recapacitación a su cartera a medida que los patrones minoristas cambian con las temporadas, las tendencias, las promociones, etc.
- Los puntos de narración de una máquina recinto no se pueden comparar con un dispositivo del entorno de producción. Especialmente, los modelos cuantificados pueden comportarse de guisa diferente en diferentes plataformas.
- El monitoreo es un ambiente secreto en la producción, ya que la compresión puede causar una degradación sutil de la precisión. Todas las alertas y buscapersonas necesarias deben estar implementadas.
- Considere siempre el costo total del sistema, ya que un maniquí de 4 KB que necesita un tiempo de ejecución de inferencia escaso especializado puede costar más que implementar un maniquí ordinario de 17 KB, que se ejecuta en todas partes.
Conclusión
En conclusión, las tres técnicas de compresión pueden ofrecer reducciones de tamaño significativas manteniendo al mismo tiempo la precisión adecuada.
Dimensionamiento de la casa es el más simple entre 3. Un LSTM-16 ofrece una compresión de 14,5x con una pérdida de precisión de menos del 1%.
Poda ofrece más control. Con una ejecución adecuada (umbrales por capa, sesgos de omisión, ajuste fino de descenso tasa de enseñanza), la poda del 70 % logra una compresión de 12,9 veces.
Cuantización INT8 logra la mejor compensación con una compresión de 15,5x con solo un 0,29% de aumento en la precisión.
La referéndum de la mejor técnica dependerá de sus limitaciones y limitaciones. Si se necesita una posibilidad simple, comience con el tamaño de la casa. Si es necesario, un nivel mayor de compresión con una pérdida mínima de precisión, opte por la cuantificación. Elija la poda principalmente cuando necesite un control detallado sobre la compensación de la precisión de la compresión.
Para implementaciones perimetrales que ayudan a los dispositivos de la tienda, tabletas, sensores de estantería o escáneres, el tamaño del maniquí (4 KB frente a 66 KB) puede determinar si su La IA se ejecuta localmente en el dispositivo o requieren una conectividad continua a la estrato.
Ravi Teja Pagidoju es un ingeniero senior con más de 9 primaveras de experiencia.
construcción de sistemas AI/ML para la optimización del comercio minorista y la esclavitud de suministro. Tiene una habilidad en Ciencias de la Computación y ha publicado investigaciones sobre enfoques híbridos de optimización de LLM en publicaciones de IEEE y Springer.
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.