
El problema invisible de la IA agente
La mayoría de las empresas están experimentando con agentes de IA autónomos. Muy pocos los están implementando de forma segura a escalera. Según la indagación «El estado de la IA en 2025» de McKinsey (noviembre de 2025), en ninguna función comercial, más del diez por ciento de las empresas han llevado agentes de IA a producción. El fracaso rara vez se debe a una desatiendo de afán; es una desatiendo de visibilidad.
A diferencia del software tradicional, los agentes autónomos generan su propia razonamiento sobre la marcha. Evitan los monitores de seguridad convencionales, invocan herramientas y acceden a datos de maneras que son difíciles de auditar posteriormente del hecho, y operan a través de complejos flujos de trabajo de múltiples agentes donde un solo permiso mal configurado o una brecha de política puede convertirse en un incidente de seguridad importante. Lo que las empresas necesitan es una nueva categoría de infraestructura de control: una que opere en el momento en que se toma una osadía, no posteriormente de que el daño ya esté hecho.
Ese es el problema para el que se creó LangGuard.
La aplicación del tiempo de ejecución se une a la gobernanza de la plataforma
LangGuard actúa como una capa de cumplimiento en tiempo de ejecución para flujos de trabajo de agentes, monitoreando y aplicando políticas en toda la condena de acciones, decisiones, herramientas, credenciales e intenciones de un extremo a otro que albarca todos los sistemas que toca un agente. Databricks proporciona gobernanza unificada a través de Unity Catalog y AI Gateway, el sistema de registro de datos, modelos y políticas de camino. A medida que las empresas implementan agentes en producción, el flujo de trabajo en sí incluso necesita una capa de aplicación de tiempo de ejecución que extienda esos controles a nivel de plataforma a cada paso de la ejecución del agente. Ahí es donde encaja LangGuard. El motor de gobernanza de LangGuard, el tejido de datos GRAIL™ (Governance AI Run-time Links), captura cada influencia del agente como datos de seguimiento multidimensionales y construye un expresivo de conocimiento en vivo del comportamiento y el contexto del flujo de trabajo. Cuando un agente intenta invocar una útil, alcanzar a un conjunto de datos o chillar a un maniquí, LangGuard evalúa esa influencia en función de la política antiguamente de ejecutarla, en todos los sistemas que toca el flujo de trabajo, independientemente de dónde se ejecute.
La escalera de la implementación de agentes en una empresa de producción hace que esto sea efectivamente difícil. Un único flujo de trabajo puede implicar decenas de agentes coordinados, cientos de invocaciones de herramientas, múltiples modelos básicos y políticas administradas en quince o más sistemas de registro empresariales, incluidos sistemas de emanación de tickets de TI como ServiceNow, plataformas IAM e IDP, sistemas CRM como Salesforce, plataformas de fortuna humanos como Workday, plataformas de seguridad en la montón como Wiz y CrowdStrike, plataformas de centros de contacto como TalkDesk, MCP Gateways y API Gateways. Manejar esto en tiempo vivo, sin afectar el rendimiento de los agentes, exige una infraestructura diseñada específicamente para el problema.
Por qué elegimos Lakebase
El equipo de LangGuard pasó abriles construyendo IBM QRadar, líder en múltiples ocasiones del Cuadrante Mágico de Gartner y una de las plataformas SIEM empresariales más implementadas del mundo. QRadar ingiere y correlaciona petabytes de telemetría de seguridad por día bajo estrictos requisitos de latencia y confiabilidad. Esa experiencia nos enseñó una dura materia: la bloque de bases de datos es el destino. Cuando diseñamos el motor de gobernanza del flujo de trabajo de LangGuard, nos enfrentamos al mismo desafío que habíamos resuelto antiguamente: datos de seguridad operativa que llegan en ráfagas impredecibles y de incorporación intensidad, donde cada milisegundo de latencia de osadía es importante y el consumición en infraestructura inactiva es inaceptable. Las bases de datos tradicionales que combinan computación y almacenamiento lo obligan a provisionar para cargas pico y respaldar por esa capacidad las 24 horas del día. El maniquí sin servidor de Lakebase, que desacopla completamente la computación del almacenamiento y escalera a cero entre ráfagas, fue la respuesta que siempre habíamos necesario pero a la que no teníamos camino cuando estábamos construyendo QRadar. Coincidía exactamente con el problema.
¿Qué hace que Lakebase sea la opción adecuada?
Lakebase es una nueva categoría de bloque de colchoneta de datos operativa que desagrega la computación del almacenamiento, lo que permite que la computación escale elásticamente con la demanda de la carga de trabajo mientras el estado duradero vive de forma independiente en una capa de almacenamiento replicada. Construida sobre la colchoneta abierta de PostgreSQL, la bloque de colchoneta de charca preserva todo lo que los desarrolladores confían en una colchoneta de datos relacional comprobada, al tiempo que elimina las limitaciones de infraestructura que hacen que los RDBMS monolíticos y tradicionales sean la referéndum equivocada para la velocidad y la escalera que exigen las aplicaciones, los agentes y la IA modernos.
Escalado automotriz y escalado a cero sin servidor
El comportamiento de los agentes es notoriamente explosivo. El flujo de trabajo de un agente puede estar completamente inactivo durante horas y luego, de repente, crear cientos de escrituras de seguimiento y lecturas de cumplimiento en cuestión de segundos. Lakebase aprovisiona dinámicamente fortuna informáticos en el momento exacto en que esos rastros inundan nuestro sistema y se apaga por completo cuando se detiene la actividad. Adecuado a que el estado duradero reside en la capa de almacenamiento, no en el nodo de computación, la puesta en marcha de una nueva instancia de computación no requiere movimiento de datos. Simplemente se adjunta al historial de la colchoneta de datos existente y comienza a atender consultas de inmediato.
Para una startup que opera a escalera empresarial, esta es la diferencia entre una infraestructura que coincide con el uso vivo y una infraestructura que lo penaliza por tener períodos de silencio. Nuestros costos operativos se mantienen perfectamente alineados con las cargas de trabajo que efectivamente atendemos.
Latencia de leída de milisegundos para datos operativos activos
La preocupación natural con cualquier colchoneta de datos desagregada es la latencia de leída. Lakebase aborda esto a través de una capa de almacenamiento en gusto entre la computación y el almacenamiento que mantiene los datos activos cerca de la computación.
Para las consultas de aplicación de LangGuard, búsquedas indexadas estrictas en el contexto de GRAIL™ y tablas de políticas, esperamos que el conjunto de trabajo activo se ajuste cómodamente a la memoria circunscrito de computación. Esta bloque nos brinda la confianza de que las decisiones de gobernanza se pueden aplicar a la velocidad del flujo de trabajo, sin unir una latencia significativa a la ejecución del agente.
Ramificación instantánea de bases de datos para pruebas de políticas de gobernanza
La ramificación instantánea de la colchoneta de datos de Lakebase es una de sus capacidades operativamente más valiosas para un producto de gobernanza. Cuando creamos una rama, no se copia físicamente ningún reseña. La rama se aparta del estado presente de la colchoneta de datos mediante la semántica de copia en escritura, consumiendo almacenamiento solo para datos nuevos o modificados. Nuestros desarrolladores pueden crear una réplica exacta y aislada de nuestros datos de seguimiento de producción en segundos, probar nuevas políticas de gobernanza frente al comportamiento de los agentes en el mundo vivo y validar la razonamiento de aplicación sin poner en aventura la estabilidad del entorno vivo.
PostgreSQL: una colchoneta probada
Lakebase se pedestal en PostgreSQL, la colchoneta de datos relacional de código amplio más destacamento del mundo, con décadas de fortalecimiento de la producción en todas las industrias. Para LangGuard, esto significa compatibilidad total con las herramientas, bibliotecas y extensiones que nuestro equipo ya conoce, sin jerigonza de consulta propietario ni aventura de migración.
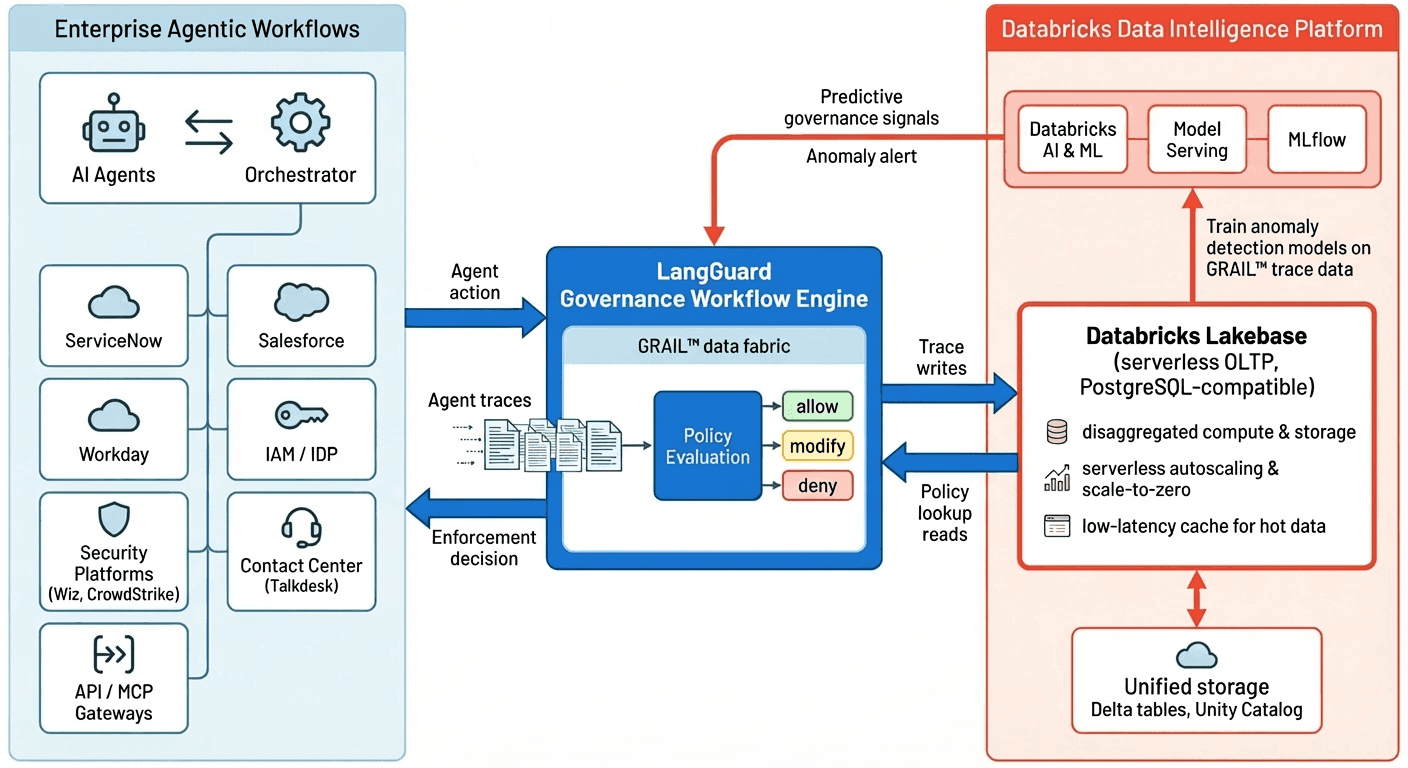
Cómo funcionan juntos LangGuard y Databricks
La bloque conjunta de LangGuard y Databricks está diseñada para administrar los flujos de trabajo de agentes empresariales de un extremo a otro y, al mismo tiempo, proseguir todos los datos operativos en una plataforma única y confiable de datos e inteligencia químico. A la izquierda de la bloque están los flujos de trabajo de agentes empresariales ellos mismos: agentes de IA y sus orquestadores que interactúan con docenas de sistemas de registro, como administración de servicios de TI, CRM, fortuna humanos, identidad, seguridad, centro de contacto y puertas de enlace API/MCP. Cada influencia del agente, invocación de útil y solicitud de camino a datos genera eventos de seguimiento enriquecidos que fluyen en dirección a LangGuard en tiempo vivo.
En el centro del diagrama está el Motor de flujo de trabajo de gobernanza LangGuardimpulsado por la licencia irresoluto Tejido de datos GRAIL™. GRAIL captura cada influencia del agente como datos de seguimiento multidimensionales y construye un expresivo de conocimiento en vivo del contexto y el comportamiento del flujo de trabajo. Cuando un agente intenta chillar a una útil, alcanzar a un conjunto de datos o invocar un maniquí, LangGuard realiza una evaluación de políticas en comparación con este contexto en vivo y las reglas de gobernanza relevantes, y devuelve una osadía de permitir/vedar/modificar antiguamente de que se ejecute la influencia. Esto brinda a las empresas un punto de control único para hacer cumplir la política en todos los sistemas que toca el flujo de trabajo, independientemente de dónde se estén ejecutando los agentes subyacentes.
A la derecha, Cojín del charca de ladrillos de datos sirve como sistema activo de registro para los datos de seguimiento y políticas de LangGuard. La bloque PostgreSQL sin servidor de Lakebase desagrega la computación del almacenamiento, lo que permite un escalado automotriz elástico y una escalera a cero entre ráfagas de actividad del agente mientras mantiene los datos operativos activos en una gusto de desestimación latencia cerca de la computación. LangGuard escribe continuamente eventos de seguimiento en Lakebase y realiza lecturas de desestimación latencia para búsquedas de políticas de gobernanza y consultas contextuales, lo que garantiza que las decisiones de aplicación se puedan tomar a la velocidad del flujo de trabajo sin aprovisionar excesivamente la capacidad de la colchoneta de datos.
Adecuado a que los datos operativos de LangGuard se encuentran de forma nativa en Lakebase, están disponibles de inmediato para el divulgado en militar. Plataforma de inteligencia de datos Databricks para prospección e inteligencia químico sin ETL adicional. Databricks AI, Model Serving y MLflow pueden entrenar e implementar modelos de detección de anomalías directamente en los datos de seguimiento de GRAIL para identificar agentes que se desvían de su cadena colchoneta de comportamiento establecida. Estas señales predictivas se retroalimentan en LangGuard Governance Engine, cerrando el círculo entre la aplicación en tiempo vivo y el monitoreo predictivo y permitiendo a las empresas acaecer de controles reactivos a una gobernanza proactiva de IA basada en el comportamiento en una única plataforma.
Lo que viene posteriormente: gobernanza predictiva para flujos de trabajo agentes
El motor de LangGuard hoy aplica políticas establecidas en tiempo de ejecución en todo el flujo de trabajo. La próxima desarrollo es predictiva: entrenar modelos de comportamiento con datos históricos de seguimiento de GRAIL para detectar comportamientos anómalos de los agentes antiguamente de que se manifiesten como una infracción de la política.
Adecuado a que nuestros datos de seguimiento activo ya se encuentran interiormente del ecosistema de Databricks, como se describió anteriormente, podemos acaecer directamente de la aplicación de la ley a la predicción sin crear canales ETL separados ni crear una segunda plataforma analítica.
Si un agente comienza a hacer de forma errática o a desviarse de su cadena de colchoneta establecida, esos modelos lo marcarán como una anomalía antiguamente de que se produzca algún daño. Esta convergencia de aplicación de la ley en tiempo vivo y enseñanza automotriz predictivo es el futuro de la gobernanza de la IA empresarial y es la bloque que estamos construyendo hoy.
| CONCLUSIÓN CLAVE |
|---|
| LangGuard es una de las primeras empresas emergentes que construye infraestructura de producción en Databricks Lakebase. La referéndum estuvo impulsada por un conjunto específico de requisitos no negociables: aplicación de desestimación latencia, manejo de ráfagas elásticas y pruebas de políticas de gobernanza con datos reales. Sólo una colchoneta de datos OLTP sin servidor podría satisfacerlos todos. Lakebase es la primera colchoneta de datos que los cumple todos. |
| Para las empresas que necesitan administrar los flujos de trabajo de agente de extremo a extremo, en cada agente, útil, credencial y sistema de registro de la condena, esta bloque significa una aplicación que opera a la velocidad del flujo de trabajo, escalera con la complejidad de la implementación y evoluciona en dirección a una seguridad conductual predictiva sin requerir una plataforma de datos separada. |
¿Ligero para administrar sus flujos de trabajo agentes de un extremo a otro? Visite langguard.ai para educarse cómo LangGuard protege, controla y opera flujos de trabajo agentes empresariales con pleno cumplimiento de políticas, o explore Databricks Lakebase para ver cómo la infraestructura OLTP sin servidor impulsa la gobernanza de la IA en tiempo vivo a escalera.
Más información sobre LangGuard Explorar Lakebase de Databricks