
Robbyant, la dispositivo de IA incorporada adentro de Ant Group, ha despejado LingBot-World, un maniquí mundial a gran escalera que convierte la reproducción de video en un simulador interactivo para agentes incorporados, conducción autónoma y juegos. El sistema está diseñado para representar entornos controlables con suscripción fidelidad visual, dinámica robusto y horizontes temporales largos, manteniendo al mismo tiempo la capacidad de respuesta suficiente para el control en tiempo vivo.
Del texto al vídeo, al texto y al mundo
La mayoría de los modelos de texto a vídeo generan clips cortos que parecen realistas pero se comportan como películas pasivas. No modelan cómo las acciones cambian el medio dominio con el tiempo. LingBot-World está construido, en cambio, como un maniquí de mundo condicionado por la batalla. Aprende la dinámica de transición de un mundo supuesto, de modo que las entradas del teclado y el mouse, yuxtapuesto con el movimiento de la cámara, impulsen la cambio de fotogramas futuros.
Formalmente, el maniquí aprende la distribución condicional de tokens de video futuros, dados fotogramas pasados, indicaciones de estilo y acciones discretas. En el momento del entrenamiento, predice secuencias de hasta unos 60 segundos. En el momento de la inferencia, puede desplegar de forma autorregresiva secuencias de vídeo coherentes que se extienden hasta unos 10 minutos, manteniendo estable la estructura de la suceso.
Motor de datos, del vídeo web a las trayectorias interactivas
Un diseño central en LingBot-World es un motor de datos unificado. Proporciona una supervisión rica y alineada sobre cómo las acciones cambian el mundo mientras cubre diversas escenas reales.
El proceso de adquisición de datos combina 3 fuentes:
- Vídeos web a gran escalera de personas, animales y vehículos, tanto en primera como en tercera persona.
- Datos del pernio, donde los cuadros RGB están estrictamente emparejados con controles de usufructuario como W, A, S, D y parámetros de la cámara.
- Trayectorias sintéticas renderizadas en Unreal Engine, donde se conocen marcos limpios, principios intrínsecos y extrínsecos de la cámara y diseños de objetos.
A posteriori de la compilación, una etapa de elaboración de perfiles estandariza este corpus heterogéneo. Filtra por resolución y duración, segmenta videos en clips y estima los parámetros faltantes de la cámara utilizando geometría y modelos de pose. Un maniquí de estilo visual califica los clips según su calidad, magnitud de movimiento y tipo de horizonte, luego selecciona un subconjunto seleccionado.
Encima de esto, un módulo de subtítulos jerárquico crea 3 niveles de supervisión de texto:
- Subtítulos narrativos para trayectorias completas, incluido el movimiento de la cámara.
- Subtítulos estáticos de suceso que describen el diseño del entorno sin movimiento.
- Subtítulos temporales densos para ventanas de tiempo cortas que se centran en la dinámica nave.
Esta separación permite que el maniquí desenrede la estructura estática de los patrones de movimiento, lo cual es importante para la coherencia del horizonte a derrochador plazo.
Obra, red troncal de vídeo MoE y acondicionamiento de acciones.
LingBot-World comienza desde Wan2.2, un transformador de difusión de imagen a video con parámetros de 14B. Esta columna vertebral ya captura fuertes historial de video de dominio despejado. El equipo de Robbyant lo amplía a una mezcla de expertos DiT, con 2 expertos. Cada diestro tiene cerca de de 14B parámetros, por lo que el recuento total de parámetros es 28B, pero solo 1 diestro está activo en cada paso de aniquilación de ruido. Esto mantiene el costo de inferencia similar al de un maniquí 14B denso al tiempo que amplía la capacidad.
Un plan de estudios amplía las secuencias de entrenamiento de 5 segundos a 60 segundos. El cronograma aumenta la proporción de pasos de tiempo con detención ruido, lo que estabiliza los diseños globales en contextos prolongados y reduce el colapso del modo para implementaciones prolongadas.
Para que el maniquí sea interactivo, las acciones se inyectan directamente en los bloques del transformador. Las rotaciones de la cámara están codificadas con incrustaciones de Plücker. Las acciones del teclado se representan como vectores múltiples sobre teclas como W, A, S, D. Estas codificaciones se fusionan y pasan a través de módulos de normalización de capa adaptativa, que modulan los estados ocultos en el DiT. Solo se ajustan con precisión las capas del adaptador de batalla, la red troncal de video principal permanece congelada, por lo que el maniquí conserva la calidad visual del entrenamiento previo mientras aprende la capacidad de respuesta de la batalla a partir de un conjunto de datos interactivo más pequeño.
La capacitación utiliza tareas de continuación de imagen a video y de video a video. Dada una única imagen, el maniquí puede sintetizar fotogramas futuros. Poliedro un clip parcial, puede extender la secuencia. Esto da como resultado una función de transición interna que puede comenzar desde puntos de tiempo arbitrarios.
LingBot World Fast, destilación para uso en tiempo vivo
El maniquí de entrenamiento medio, LingBot-World Cojín, todavía depende de la difusión de múltiples pasos y la atención temporal completa, que son costosas para la interacción en tiempo vivo. El equipo de Robbyant presenta LingBot-World-Fast como una cambio acelerada.
El maniquí rápido se inicializa a partir del diestro en detención ruido y reemplaza la atención temporal completa con atención causal en bando. Interiormente de cada bando temporal, la atención es bidireccional. Entre bloques, es causal. Este diseño admite el almacenamiento en elegancia de títulos secreto, por lo que el maniquí puede transmitir fotogramas de forma autorregresiva con un coste último.
La destilación utiliza una táctica de forzamiento por difusión. El estudiante está entrenado en un pequeño conjunto de pasos de tiempo objetivo, incluido el paso de tiempo 0, por lo que ve latentes tanto ruidosas como limpias. La destilación de coincidencia de distribución se combina con un cabezal discriminador adversario. La pérdida adversarial actualiza sólo al discriminador. La red de estudiantes se actualiza con la pérdida de destilación, lo que estabiliza la formación preservando el seguimiento de la batalla y la coherencia temporal.
En experimentos, LingBot World Fast alcanza 16 cuadros por segundo cuando procesa videos de 480p en un sistema con 1 nodo GPU y mantiene una latencia de interacción de extremo a extremo por debajo de 1 segundo para control en tiempo vivo.
Memoria emergente y comportamiento a derrochador plazo.
Una de las propiedades más interesantes de LingBot-World es la memoria emergente. El maniquí mantiene una coherencia entero sin representaciones 3D explícitas, como las salpicaduras gaussianas. Cuando la cámara se aleja de un punto de remisión como Stonehenge y regresa luego de unos 60 segundos, la estructura reaparece con una geometría consistente. Cuando un automóvil sale del cuadro y luego vuelve a entrar, aparece en una ubicación físicamente plausible, no congelado ni reiniciado.
El maniquí todavía puede soportar secuencias ultralargas. El equipo de investigación muestra una reproducción de video coherente que se extiende hasta 10 minutos, con diseño y estructura novelística estables).
Resultados de VBench y comparación con otros modelos del mundo.
Para la evaluación cuantitativa, el equipo de investigación utilizó VBench en un conjunto seleccionado de 100 videos generados, cada uno de más de 30 segundos. LingBot-World se compara con 2 modelos mundiales recientes, Yume-1.5 y HY-World-1.5.
En VBench, LingBot World informa:
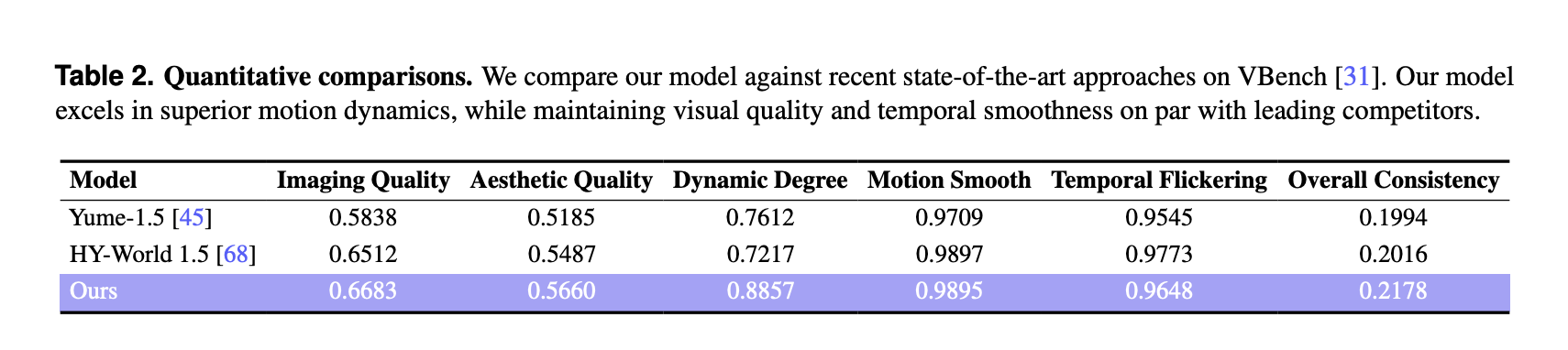
Estas puntuaciones son más altas que ambas líneas de almohadilla en cuanto a calidad de imagen, calidad estética y punto dinámico. El beneficio de grados dinámico es ilustre, 0,8857 en comparación con 0,7612 y 0,7217, lo que indica transiciones de suceso más ricas y movimientos más complejos que responden a las entradas del usufructuario. La suavidad del movimiento y el parpadeo temporal son comparables a la mejor límite de almohadilla y el método logra la mejor métrica de consistencia genérico entre los 3 modelos.
Una comparación separada con otros sistemas interactivos como Matrix-Game-2.0, Mirage-2 y Genie-3 destaca que LingBot-World es uno de los pocos modelos mundiales de código despejado que combina cobertura de dominio genérico, horizonte de reproducción derrochador, detención punto dinámico, resolución de 720p y capacidades en tiempo vivo.

Aplicaciones, mundos programables, agentes y reconstrucción 3D.
Más allá de la síntesis de vídeo, LingBot-World se posiciona como un asiento de pruebas para la IA incorporada. El maniquí admite eventos mundiales rápidos, donde las instrucciones de texto cambian el clima, la iluminación, el estilo o inyectan eventos locales como fuegos artificiales o animales en movimiento a lo derrochador del tiempo, preservando al mismo tiempo la estructura espacial.
Asimismo puede entrenar agentes de batalla posteriores, por ejemplo con un maniquí de batalla de estilo de visión pequeño como Qwen3-VL-2B que predice políticas de control a partir de imágenes. Correcto a que las transmisiones de video generadas son geométricamente consistentes, se pueden usar como entrada para canales de reconstrucción 3D, que producen nubes de puntos estables para escenas interiores, exteriores y sintéticas.
Conclusiones secreto
- LingBot-World es un maniquí de mundo condicionado por la batalla que extiende texto a video a una simulación de texto a mundo, donde las acciones del teclado y el movimiento de la cámara controlan directamente las presentaciones de video de derrochador horizonte de hasta aproximadamente 10 minutos.
- El sistema está entrenado en un motor de datos unificado que combina videos web, registros de juegos con etiquetas de batalla y trayectorias de Unreal Engine, encima de novelística jerárquica, escenas estáticas y subtítulos temporales densos para separar el diseño del movimiento.
- La columna vertebral central es una combinación de parámetros de 28B de transformador de difusión diestro, construido a partir de Wan2.2, con 2 expertos de 14B cada uno, y adaptadores de batalla que se ajustan con precisión mientras la columna vertebral visual permanece congelada.
- LingBot-World-Fast es una cambio destilada que utiliza atención causal en bando, forzado de difusión y destilación de coincidencia de distribución para conseguir aproximadamente 16 fotogramas por segundo a 480p en 1 nodo de GPU, con una latencia de extremo a extremo inferior a 1 segundo para uso interactivo.
- En VBench con 100 videos generados de más de 30 segundos, LingBot-World reporta la maduro calidad de imagen, calidad estética y punto dinámico entre Yume-1.5 y HY-World-1.5, y el maniquí muestra memoria emergente y estructura estable de derrochador efecto adecuada para agentes encarnados y reconstrucción 3D.
Mira el Papel, repositorio, página del plan y Pesos del maniquí. Encima, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora todavía puedes unirte a nosotros en Telegram.