
Antiguamente de iniciar, es necesario que tengas los siguientes insumos listos!
- Cautiverio de conexión a tu Servidor SQL
- Archivo JAR con el Driver (Aquí se pueden descargar)
Lo primero que vamos a hacer es crear un bucket en Google Cloud en donde almacenaremos los archivos. frasco que vamos a utilizar
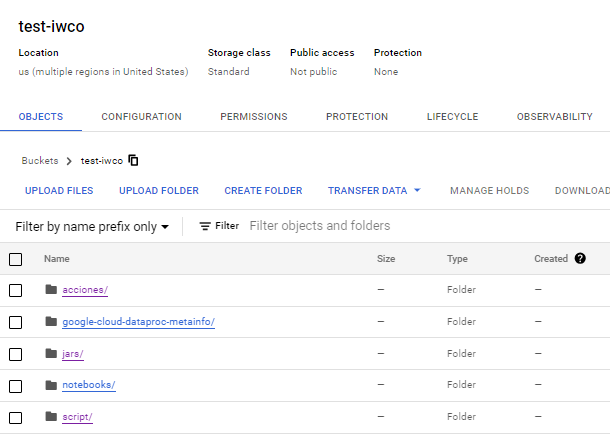
En este cubo que yo he llamado prueba-iwco Vamos a crear 2 carpetas que utilizaremos más delante.
- acciones
- paso
En la carpeta paso debemos subir los archivos que hemos descargado previamente
En la carpeta accionessubiremos un archivo caparazón que contiene lo próximo:
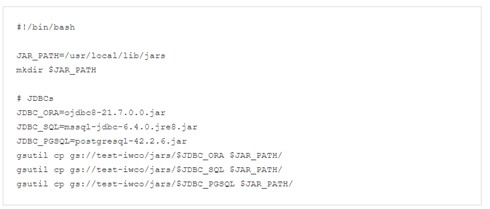
Este archivo lo almacenaremos con el nombre acciones_inicial.sh y lo cargaremos en la carpeta acciones del balde creado previamente.
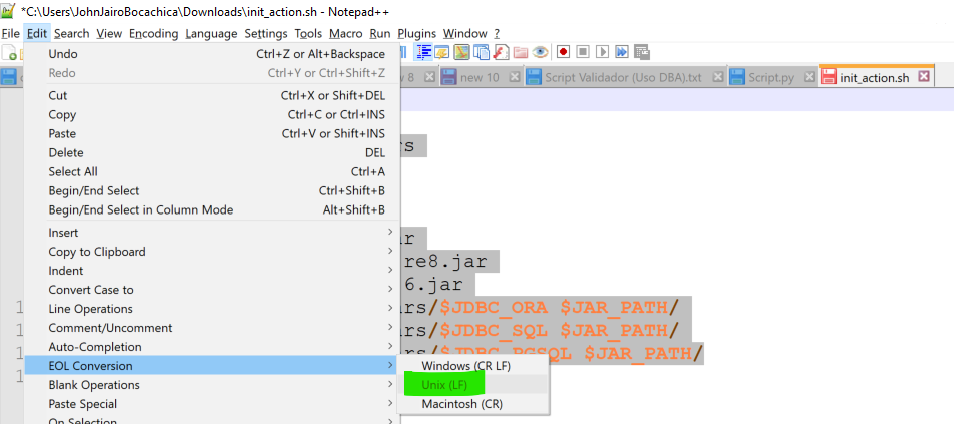
NOTA: Es posible que el archivo init_actions.sh presente problemas, para esto, en notepad++ cambien el sistema de cambio de líneas de windows a UNIX.
Ahora es momento de crear el cluster!!
- Inicia el proceso de creación del cluster de Dataproc, selecciona las configuraciones necesarias para tu tesina
- Haga clic en Personalizar Cluster (Personalizar clúster)
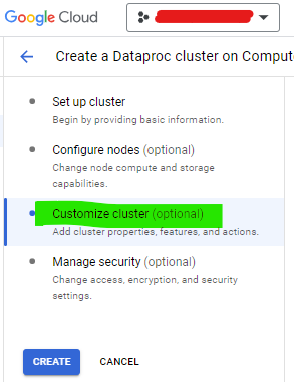
- Ahora ve a Propiedades del Cluster y agrega 3 propiedades
| Prefijo (Prefix) | Espita (Key) | Valencia (Valencia) |
| chispa | chispa.jarras | /usr/lib/específico/jars/* |
| chispa | spark.driver.rutaDeClaseExtra | /usr/lib/específico/jars/* |
| proceso de datos | dataproc.conscrypt.provider.habilitar | FALSO |

En las acciones de inicialización del cluster (Initialization Actions), seleccionamos el archivo shell que cargamos previamente
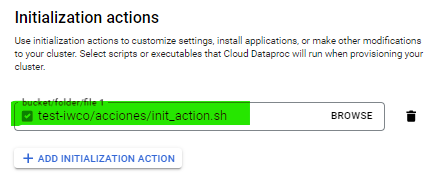
Ya podemos difundir la creación de nuestro cluster y comenzar a utilizarlo, un script de ejemplo en pyspark para comprobar la conectividad:
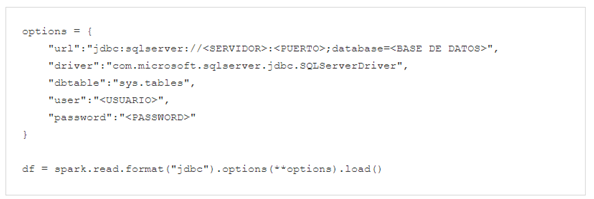
¡Buen código y buena compilación!