
¿Cómo cambiaría su pila de agentes si una política pudiera entrenarse exclusivamente a partir de sus propios lanzamientos basados en resultados (sin recompensas ni demostraciones) y aún así pasar el formación por imitación en ocho puntos de narración? Meta Superintelligence Labs propone ‘Experiencia temprana‘, un enfoque de capacitación sin recompensas que mejoramiento el formación de políticas en agentes lingüísticos sin grandes conjuntos de demostración humana y sin formación por refuerzo (RL) en el tirabuzón principal. La idea central es simple: dejar que el agente se ramifique desde estados expertos, tome sus propias acciones, recopile el estados futuros resultantesy convertir esas consecuencias en supervisión. El equipo de investigación ejemplifica esto con dos estrategias concretas:Modelado mundial implícito (IWM) y Autorreflexión (SR)—e informa ganancias consistentes en ocho entornos y múltiples modelos cojín.
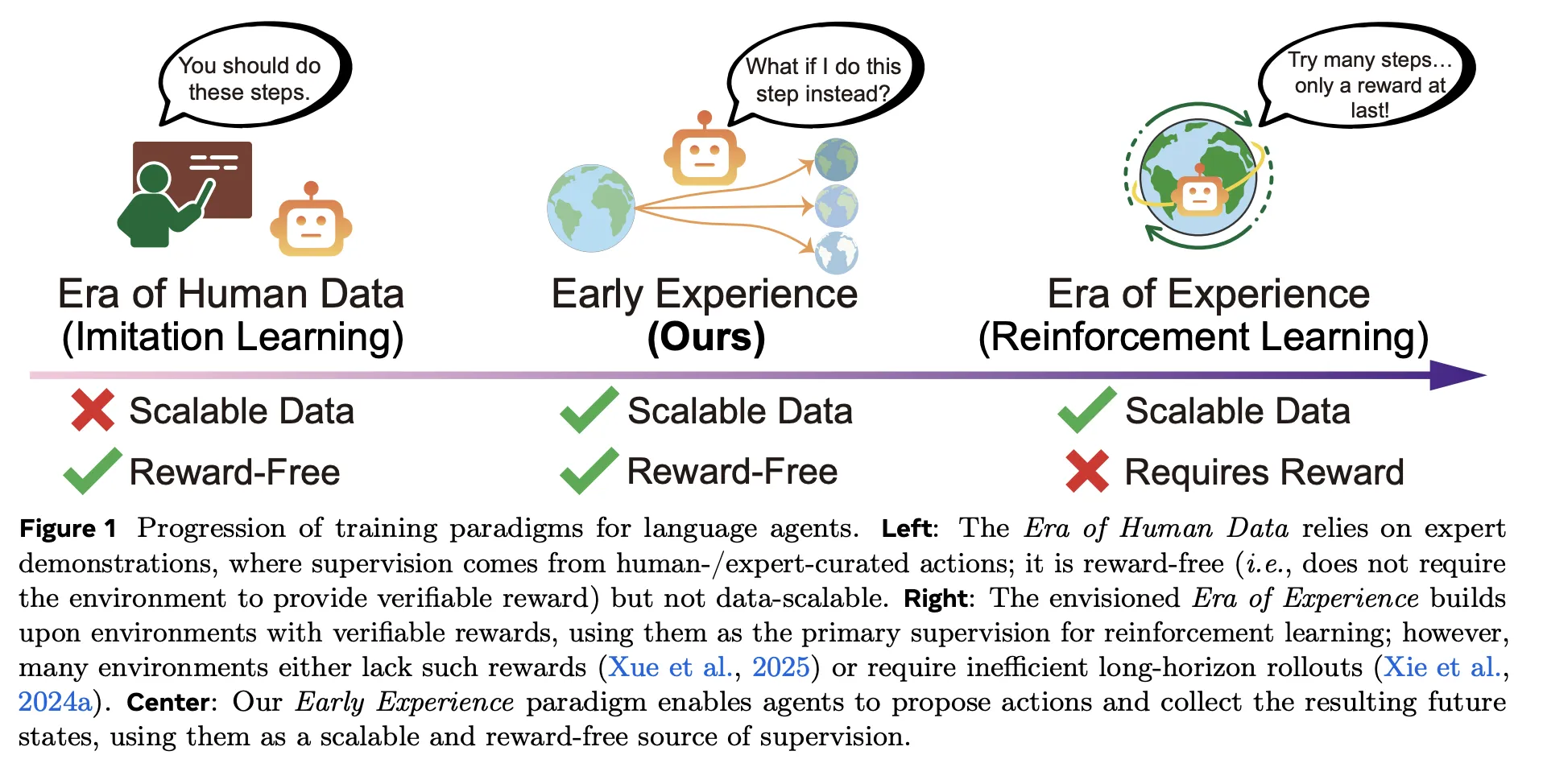
¿Qué cambia la experiencia temprana?
Los oleoductos tradicionales se apoyan en formación por imitación (IL) sobre trayectorias expertas, que es moderado de optimizar pero difícil de ascender y frágil fuera de distribución; formación por refuerzo (RL) promete ilustrarse de la experiencia, pero necesita recompensas verificables e infraestructura estable, poco que a menudo desliz en entornos web y de múltiples herramientas. Experiencia temprana se sienta entre ellos: es sin premio como formación por imitación (IL)pero la supervisión se sostén en consecuencias de las propias acciones del agenteno sólo acciones de expertos. En extracto, el agente propone, actúa y aprende de lo que verdaderamente sucede a continuación, sin escazes de función de premio.
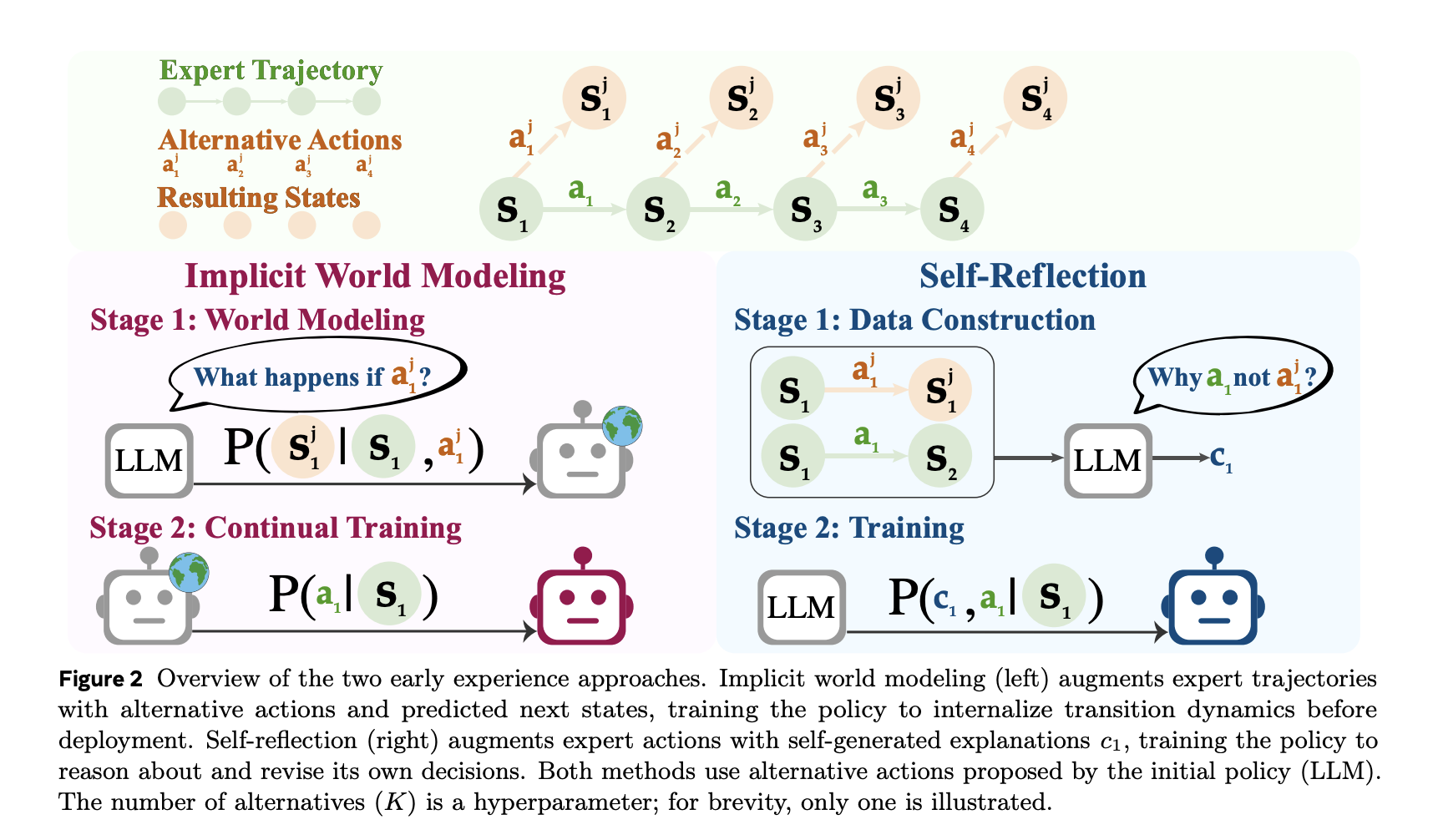
- Modelado mundial implícito (IWM): Entrene el maniquí para predecir la próxima observación poliedro el estado y la hecho elegida, endureciendo el maniquí interno de dinámica ambiental del agente y reduciendo la deriva fuera de las políticas.
- Autorreflexión (SR): Presentar acciones periciales y alternativas en el mismo estado; que el maniquí explique por qué la hecho experta es mejor utilizando los resultados observados, luego afinar la política a partir de esta señal contrastiva.
Ambas estrategias utilizan los mismos presupuestos y configuraciones de decodificación que IL; sólo difiere la fuente de datos (ramas generadas por agentes en oficio de trayectorias más expertas).
Comprender los puntos de narración
El equipo de investigación evalúa ocho entornos de agentes lingüísticos que abarcan navegación web, planificación a extenso plazo, tareas científicas/corporizadas y flujos de trabajo API multidominio, por ejemplo, Tienda web (navegación transaccional), Planificador de viajes (planificación rica en restricciones), CienciaMundo, ALFMundo, Cárcel Tauy otros. Experiencia temprana rendimientos ganancias absolutas promedio de +9.6 éxito y +9,4 fuera del dominio (OOD) sobre IL en toda la matriz de tareas y modelos. Estos avances persisten cuando se utilizan los mismos puntos de control para inicializar RL (GRPO), mejorando los límites máximos post-RL hasta +6,4 en comparación con formación por refuerzo (RL) comenzó desde formación por imitación (IL).
Eficiencia: menos datos expertos, mismo presupuesto de optimización
Una trofeo experiencia secreto es eficiencia de demostración. Con un presupuesto de optimización fijo, Experiencia temprana iguala o vence a IL usando un fracción de datos de expertos. En Tienda web, 1/8 de las manifestaciones con Experiencia temprana ya supera IL entrenado en el realizado conjunto de demostración; en ALFMundola paridad se ve afectada en 1/2 las demostraciones. La preeminencia crece con más demostraciones, lo que indica que los estados futuros generados por agentes proporcionan señales de supervisión que las demostraciones por sí solas no captan.
Cómo se construyen los datos?
El oleoducto se genera a partir de un conjunto constreñido de implementaciones de expertos para obtener estados representativos. En estados seleccionados, el agente propone acciones alternativaslos ejecuta y registra el próximas observaciones.
- Para IWMlos datos de entrenamiento son tripletes ⟨estado, hecho, próximo estado⟩ y el objetivo es predicción del próximo estado.
- Para SRlas indicaciones incluyen la hecho de los expertos y varias alternativas más sus resultados observados; el maniquí produce un razonamiento fundamentado explicando por qué es preferible la hecho de expertos, y esta supervisión luego se utiliza para mejorar la política.
Dónde encaja el formación por refuerzo (RL)?
Experiencia temprana es no “RL sin recompensas”. es un supervisado prescripción que utiliza resultados experimentados por el agente como etiquetas. En entornos con recompensas verificables, el equipo de investigación simplemente sumar RL luego Experiencia temprana. Oportuno a que la inicialización es mejor que IL, el mismo horario RL sube más detención y más rápido, con hasta +6,4 éxito final sobre RL inicializado con IL en todos los dominios probados. Esto posiciona a la Experiencia Temprana como un puente: entrenamiento previo sin recompensas a partir de consecuencias, seguido (cuando sea posible) de un unificado formación por refuerzo (RL).
Conclusiones secreto
- Capacitación sin recompensas a través de agentes generados estados futuros (no recompensas) usando Modelado del mundo implícito y Autorreflexión supera el formación por imitación en ocho entornos.
- Ganancias absolutas reportadas sobre IL: +18,4 (Tienda web), +15.0 (Planificador de viajes), +13.3 (Mundo de la ciencia) bajo presupuestos y entornos armonizados.
- Eficiencia de demostración: supera IL en WebShop con 1/8 de manifestaciones; alcanza la paridad ALFWorld con 1/2—a un costo de optimización fijo.
- Como inicializador, Experiencia temprana aumenta los puntos finales posteriores de RL (GRPO) al hasta +6,4 contra RL comenzó desde IL.
- Validado en múltiples familias troncales (3B–8B) con mejoras consistentes adentro y fuera del dominio; posicionado como un puente entre formación por imitación (IL) y formación por refuerzo (RL).
Experiencia temprana es una contribución pragmática: reemplaza el frágil aumento basado nada más en la método con una supervisión basada en resultados que un agente puede difundir a escalera, sin funciones de premio. Las dos variantes, el modelado mundial implícito (predicción de la próximo observación para fijar la dinámica del entorno) y la autorreflexión (justificaciones contrastantes y verificadas por resultados frente a las acciones de expertos), atacan directamente la deriva fuera de las políticas y la acumulación de errores a extenso plazo, lo que explica las ganancias constantes sobre el formación por imitación en ocho entornos y los límites máximos de RL más fuertes cuando se utilizan como inicializador para GRPO. En entornos web y de uso de herramientas donde las recompensas verificables son escasas, esta supervisión sin recompensas es el punto medio que desliz entre IL y RL y es inmediatamente procesable para las pilas de agentes de producción.
Mira el PAPEL aquí. No dudes en consultar nuestra Página de GitHub para tutoriales, códigos y cuadernos. Por otra parte, no dudes en seguirnos en Gorjeo y no olvides unirte a nuestro SubReddit de más de 100.000 ml y suscríbete a nuestro boletín. ¡Esperar! estas en telegrama? Ahora asimismo puedes unirte a nosotros en Telegram.
Asif Razzaq es el director ejecutante de Marktechpost Media Inc.. Como patrón e ingeniero fantaseador, Asif está comprometido a beneficiarse el potencial de la inteligencia sintético para el perfectamente social. Su esfuerzo más nuevo es el propagación de una plataforma de medios de inteligencia sintético, Marktechpost, que se destaca por su cobertura en profundidad del formación obligatorio y las parte sobre formación profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el conocido.